Clear Sky Science · it
Colmare il divario di prestazioni: ottimizzazione sistematica di LLM locali per l'estrazione di PHI mediche in giapponese
Perché questo è importante per la privacy dei pazienti
Gli ospedali possiedono enormi raccolte di annotazioni mediche che potrebbero migliorare cure e ricerca, ma questi documenti contengono dettagli sensibili come nomi, indirizzi e date. I potenti sistemi di IA basati su cloud sono molto efficaci nel nascondere queste informazioni, tuttavia molti ospedali non possono inviare dati grezzi dei pazienti a server esterni. Questo studio dimostra che, con una messa a punto accurata, modelli di IA più piccoli eseguiti interamente all'interno dell'ospedale possono avvicinarsi sorprendentemente alle prestazioni dei migliori sistemi cloud—offrendo un modo per usare l'IA mantenendo i dati dei pazienti al sicuro in sede.
Il dilemma privacy contro progresso
I moderni modelli linguistici di grandi dimensioni possono individuare e rimuovere in modo affidabile le informazioni sanitarie protette (PHI) dal testo medico, spesso superando il 90% di accuratezza. Tuttavia, inviare referti pazienti non modificati ai servizi cloud solleva preoccupazioni legali ed etiche sotto regolamentazioni come HIPAA, GDPR e l'APPI giapponese. Molte istituzioni insistono per una piena “sovranità dei dati”, cioè che le informazioni non escano mai dai loro sistemi. Fino ad ora, i modelli locali eseguibili su hardware interno generalmente mancavano molti più identificatori, costringendo gli ospedali a un compromesso: analisi avanzate nel cloud o maggiore privacy con strumenti meno performanti. Gli autori si sono proposti di verificare se questo divario potesse essere sufficientemente ridotto per un uso clinico reale.
Un piano a tappe per un'IA locale più intelligente
Il team ha progettato un quadro di ottimizzazione in cinque fasi per migliorare progressivamente le prestazioni dei modelli linguistici locali nella rimozione delle PHI nei referti di radiologia in giapponese. Hanno iniziato con 14 modelli diversi di varie dimensioni, tutti eseguiti su un computer isolato e senza connessione a Internet per imitare la sicurezza ospedaliera. Usando 160 referti sintetici accuratamente costruiti—realistici ma interamente fittizi—hanno misurato quanto bene ogni modello individuasse e separasse otto tipi di identificatori, da nomi e numeri di identificazione fino a date e reparti. Dopo un test di baseline iniziale, hanno creato prompt generali più efficaci, poi istruzioni personalizzate per le peculiarità di ciascun modello, aggiunto un ciclo automatico di “autoverifica e correzione” e infine testato i migliori candidati su un insieme riservato di referti. 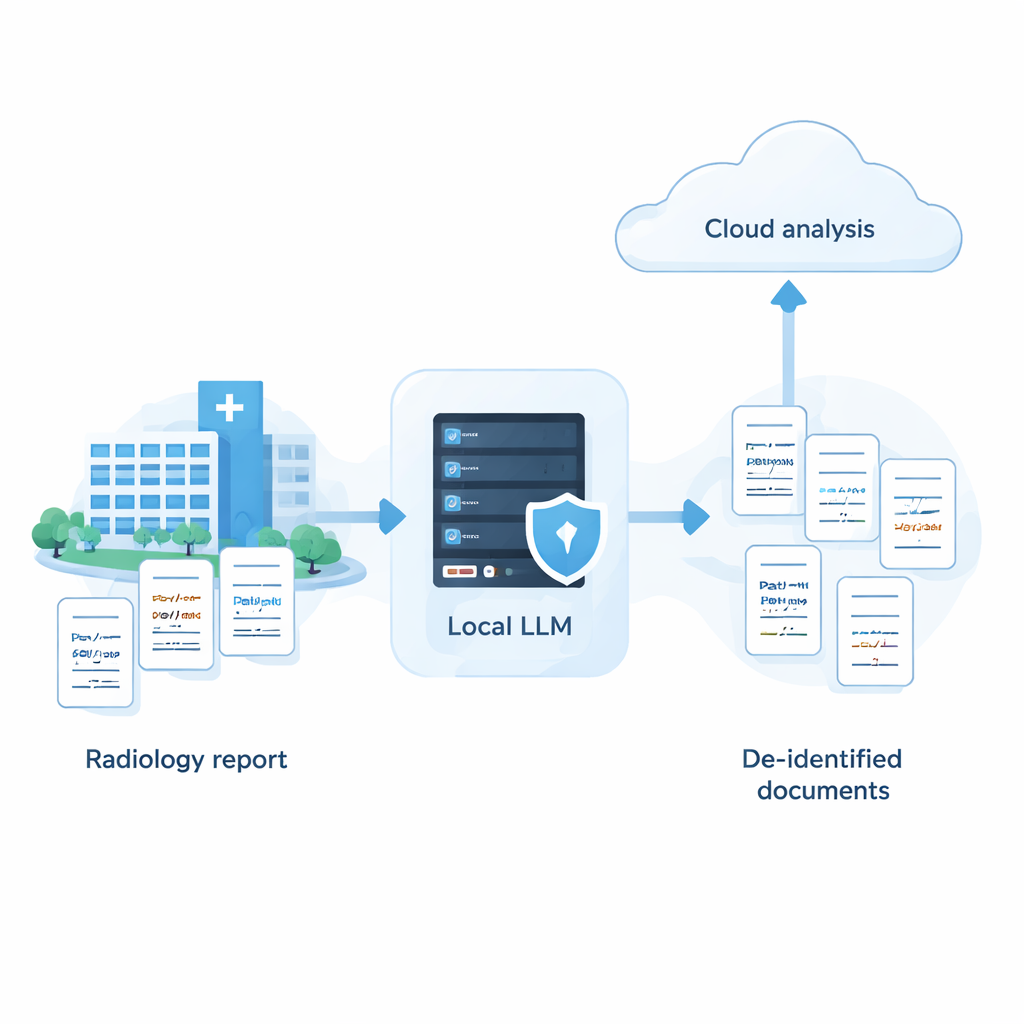
Avvicinarsi alle prestazioni cloud
Attraverso questo processo a tappe, i ricercatori hanno scoperto che la semplice dimensione del modello non era la chiave del successo; anche alcuni sistemi molto grandi hanno ottenuto risultati scadenti. Al contrario, i modelli più promettenti erano quelli che rispondevano bene a un'attenta progettazione delle istruzioni e all'analisi degli errori. Un sistema di media dimensione, Mistral-Small-3.2, è emerso come vincitore dopo prompt personalizzati e una fase di auto-rifinitura in cui il modello ha rivisto e corretto selettivamente le proprie uscite. Sui 60 casi di test finali, questa configurazione locale ottimizzata ha ottenuto 91,54 su 100—circa il 97,8% dei 93,56 punti del modello cloud leader—rispettando perfettamente le regole di formattazione. In termini pratici, il deficit residuo è stato giudicato clinicamente di entità minima. Il costo principale è stato la velocità: l'elaborazione locale ha richiesto circa 25 secondi per referto tipico, contro meno di 2 secondi nel cloud, ma ciò è stato ritenuto accettabile per lavoro in batch di routine non urgente. 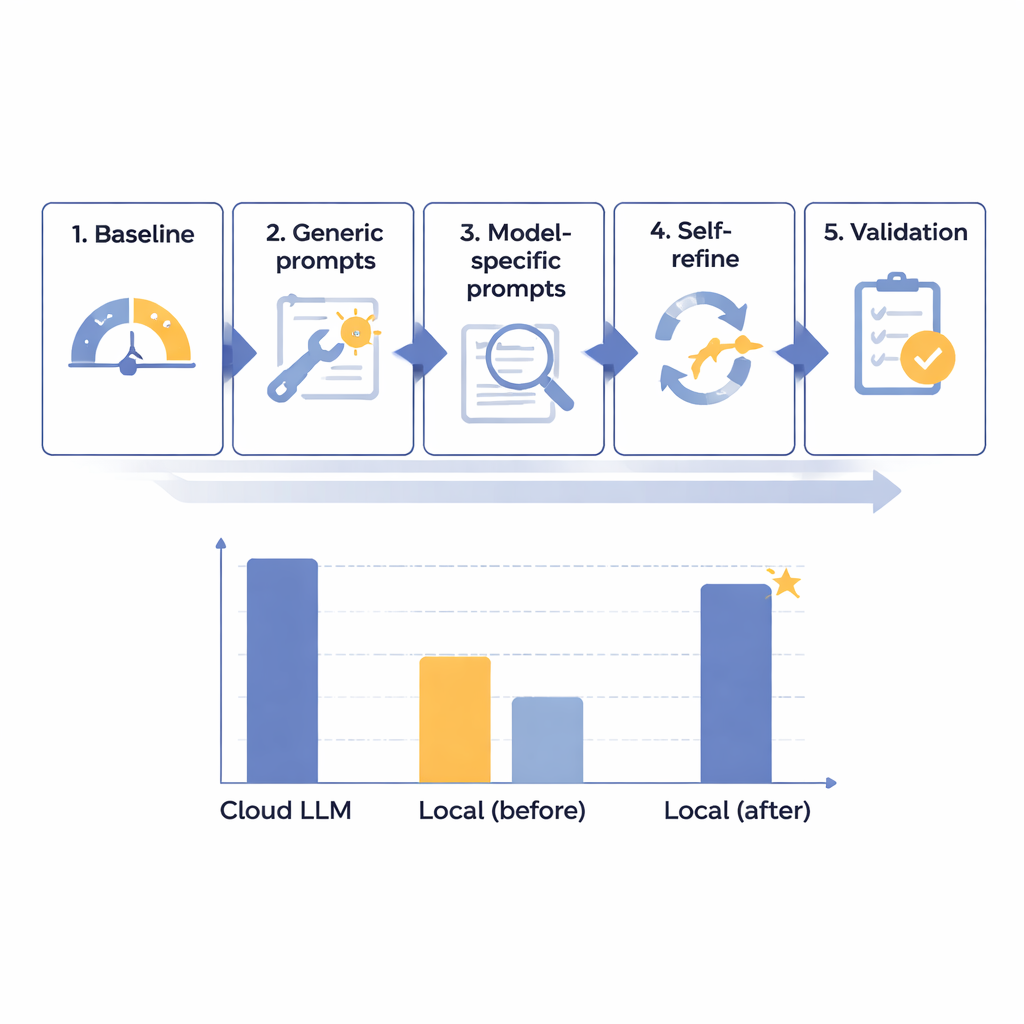
Una soglia sorprendente per l'auto-correzione
Una delle scoperte più interessanti è stata una sorta di punto di svolta attorno agli 87–88 punti nella scala a 100 punti degli autori. I modelli che partivano sotto questo livello al baseline—come Mistral-Small-3.2—hanno beneficiato notevolmente del ciclo di auto-rifinitura, guadagnando quasi sette punti correggendo una piccola frazione dei propri errori. I modelli che iniziavano già sopra questa soglia hanno mostrato quasi nessun miglioramento e talvolta hanno sprecato risorse cercando di “correggere” risposte già corrette. Questo suggerisce che gli strumenti di ottimizzazione avanzata dovrebbero essere riservati a modelli che sono buoni ma non eccellenti, offrendo agli ospedali un modo per concentrare potenza di calcolo e tempo del personale dove rende di più. Gli autori avvertono che questa soglia si basa su appena due modelli e necessita di conferma, ma offre una regola empirica iniziale per la pianificazione del deployment.
Cosa significa per ospedali e pazienti
Lo studio sostiene che gli ospedali non devono scegliere tra forte privacy e IA performante. Con un approccio sistematico—selezionando molti modelli, adattando i prompt ai loro punti di forza e di debolezza e aggiungendo una fase intelligente di auto-revisione—è possibile che un sistema completamente locale si avvicini all'accuratezza dei migliori servizi cloud nella rimozione delle informazioni sensibili dal testo medico. In pratica, questo apre la strada a una strategia ibrida: le PHI vengono rimosse in modo sicuro su macchine di proprietà dell'ospedale e solo referti anonimizzati, con nomi e altri identificatori rimossi, vengono inviati al cloud per analisi più avanzate. Sebbene il lavoro attuale sia basato su referti di radiologia sintetici in giapponese e debba essere testato su dati reali e altre lingue, offre una roadmap concreta per le istituzioni che vogliono sfruttare l'IA mantenendo al centro la fiducia e la privacy dei pazienti.
Citazione: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
Parole chiave: de-identificazione medica, privacy del paziente, modelli linguistici locali, IA per la sanità, referti di radiologia