Clear Sky Science · it
Rilevamento oggetti su SoC edge a bassa potenza di calcolo: un benchmark riproducibile e linee guida per il deployment
Perché i chip minuscoli per le videocamere intelligenti sono importanti
Molti dei dispositivi “intelligenti” che ci circondano — videocamere di sicurezza, droni, sensori industriali e campanelli smart — devono individuare persone e oggetti in tempo reale, ma si basano su chip molto piccoli e a basso consumo invece che sull’hardware energivoro dei data center. Le aziende spesso scelgono popolari modelli YOLO per il rilevamento, tuttavia la velocità dichiarata dei chip dice poco su come questi si comportino realmente sul campo. Questo studio adotta un approccio sperimentale rigoroso per analizzare come nove varianti moderne di YOLO si comportano su tre diffusi processori Rockchip a basso costo, rivelando cosa determina veramente velocità, consumo energetico e affidabilità quando l’intelligenza si sposta verso l’edge.
Tre chip di uso quotidiano sotto il microscopio
Gli autori si concentrano su tre system-on-chip (SoC) commerciali che alimentano discretamente molti sistemi di visione embedded: il compatto RV1106, il di fascia media RK3568 e il più capace RK3588. Ognuno combina core di elaborazione generici con un’unità di elaborazione neurale (NPU) dedicata e memoria esterna. Su queste piattaforme il team distribuisce nove modelli YOLO — tre generazioni (YOLOv5, YOLOv8, YOLO11) in tre taglie (Nano, Small, Medium) — tutti addestrati sullo stesso dataset di benchmark. Convertono accuratamente i modelli in un formato comune, li quantizzano a precisione a 8 bit, li compilano con gli strumenti Rockchip e quindi eseguono centinaia di test temporizzati per ottenere misure stabili di latenza, potenza ed energia per frame processato.
La velocità non è quella che suggerisce la scheda tecnica
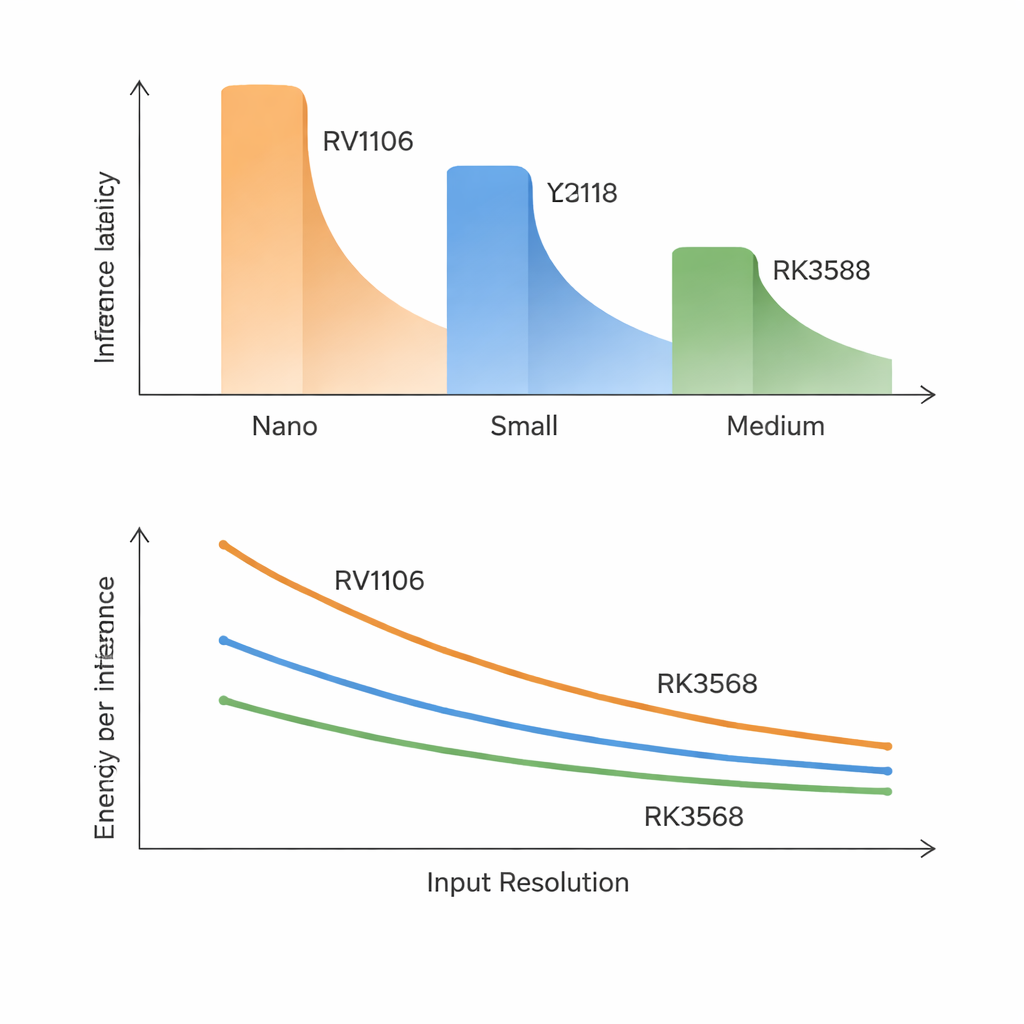
Una delle lezioni più nette è che i numeri tradizionali sui modelli e sui chip sono cattivi predittori della velocità reale. Sul chip più lento, anche i modelli più piccoli impiegano circa 70–100 millisecondi per frame e quelli di taglia media sono troppo lenti per un uso in tempo reale. Il chip più veloce può eseguire modelli Nano e molti Small vicino al traguardo di 30 fotogrammi al secondo, ma i modelli più grandi restano lontani dagli obiettivi di frame rate molto elevati. In modo sorprendente, la latenza si allinea più strettamente con l’accuratezza del modello che non con il numero di operazioni matematiche o di parametri. Le versioni YOLO più recenti e più accurate introducono blocchi interni che migliorano l’accuratezza ma risultano ostici da eseguire per queste NPU; di conseguenza “più intelligente” spesso significa “notabilmente più lento” su questo tipo di hardware.
Quando immagini più grandi e memoria condivisa mordono
Lo studio mostra che aumentare la risoluzione di input non aumenta il lavoro in modo lineare. In teoria raddoppiare larghezza e altezza dovrebbe quadruplicare il costo, ma su chip a banda passante ridotta può crescere ancora di più. Con immagini più grandi, i dati intermedi non riescono più a stare comodamente in memoria locale e devono essere trasferiti ripetutamente nella memoria esterna. Sui SoC più piccoli e di fascia media questo si trasforma in un ingorgo: i modelli di taglia media rallentano molto più del previsto e l’uso intensivo della memoria da parte di altri processi può gonfiare le latenze del 50–270%. Al contrario, l’RK3588, con una banda memoria molto superiore, gestisce bene gli aumenti di risoluzione e non si scompone sotto carichi CPU o di memoria aggiuntivi, evidenziando che la velocità della memoria — non la sola potenza di calcolo — è spesso il vero collo di bottiglia.
Più core e più potenza non garantiscono efficienza
Il chip più veloce di Rockchip include una NPU a tre core, ma distribuire YOLO su più core apporta soltanto benefici modesti. Per la maggior parte dei modelli, spartire il lavoro su due o tre core riduce la latenza di meno del 10% e a volte le prestazioni peggiorano. L’overhead di coordinamento tra core e la condivisione dello stesso pool di memoria annulla gran parte del guadagno teorico. Le misure di potenza aggiungono un’altra sfumatura: tutti e tre i SoC consumano pochi watt durante l’esecuzione, eppure l’energia per frame processato può differire di un fattore tre. L’RK3588 consuma istantaneamente più potenza ma porta a termine il lavoro così più rapidamente che spesso risulta la scelta più efficiente in termini energetici, specialmente per modelli di taglia media e risoluzioni più elevate.
Indicazioni pratiche per dispositivi nel mondo reale
Per chi progetta videocamere intelligenti, robot o dispositivi IoT, il messaggio è diretto. Sui chip più piccoli sono praticabili solo i modelli YOLO più minuscoli a risoluzioni moderate, e anche in quel caso il video in tempo reale è una sfida. I chip di fascia media supportano agevolmente i modelli small e talvolta quelli medium se si è disposti a rinunciare a frame rate elevati o a durata della batteria. L’RK3588 di fascia alta rende infine realistico eseguire varianti YOLO più accurate e di taglia media pur mantenendo sotto controllo l’energia per frame. In generale, il documento sostiene che i progettisti dovrebbero scegliere i modelli tenendo fermamente conto dell’hardware, prestare molta attenzione alla banda della memoria e privilegiare tecniche che risparmiano memoria anziché inseguire reti sempre più grandi. Ciò che conta in ultima istanza non sono i tera-operazioni al secondo dichiarati, ma se l’intero sistema è in grado di fornire un rilevamento oggetti veloce, stabile ed energeticamente sostenibile nelle condizioni imperfette del mondo reale.
Citazione: Kong, C., Li, F., Yan, X. et al. Object detection on low-compute edge SoCs: a reproducible benchmark and deployment guidelines. Sci Rep 16, 5875 (2026). https://doi.org/10.1038/s41598-026-36862-y
Parole chiave: edge AI, rilevamento oggetti, visione embedded, modelli YOLO, SoC a basso consumo