Clear Sky Science · it
Stima della varianza basata su machine learning in campionamento a due fasi usando dati dei settori salute e istruzione
Perché medie più intelligenti contano per decisioni del mondo reale
Quando i medici studiano la pressione arteriosa o gli educatori monitorano i voti degli studenti, non si interessano solo alla media; hanno bisogno di sapere quanto le persone differiscano attorno a quella media. Questa dispersione, chiamata variabilità, guida il numero di pazienti da reclutare per uno studio clinico, le dimensioni di un programma di tutoraggio o il grado di fiducia nelle decisioni politiche. L’articolo dietro questo riassunto presenta un nuovo metodo, fondato statisticamente, per misurare quella variabilità in modo più preciso fondendo idee classiche sul campionamento con il moderno machine learning, testato su dati di salute e istruzione.
Misurare la dispersione quando l’informazione è incompleta
In un mondo ideale, i ricercatori conoscerebbero dettagli aggiuntivi su ogni persona di una popolazione prima di condurre un’indagine: età, abitudini di studio, storia medica e altro. In realtà, queste informazioni sono spesso incomplete o costose da raccogliere. Gli autori lavorano all’interno di un disegno chiamato campionamento a due fasi per gestire questa situazione. Nella prima fase prendono un campione ampio e relativamente economico e registrano informazioni di base semplici, come l’età o se una persona ha accesso a internet. Nella seconda fase estraggono un sottocampione più piccolo e misurano un esito più oneroso o che richiede tempo, come la pressione sistolica o i voti finali. La sfida è usare questi due livelli di informazione per stimare quanto sia realmente variabile l’esito nell’intera popolazione.
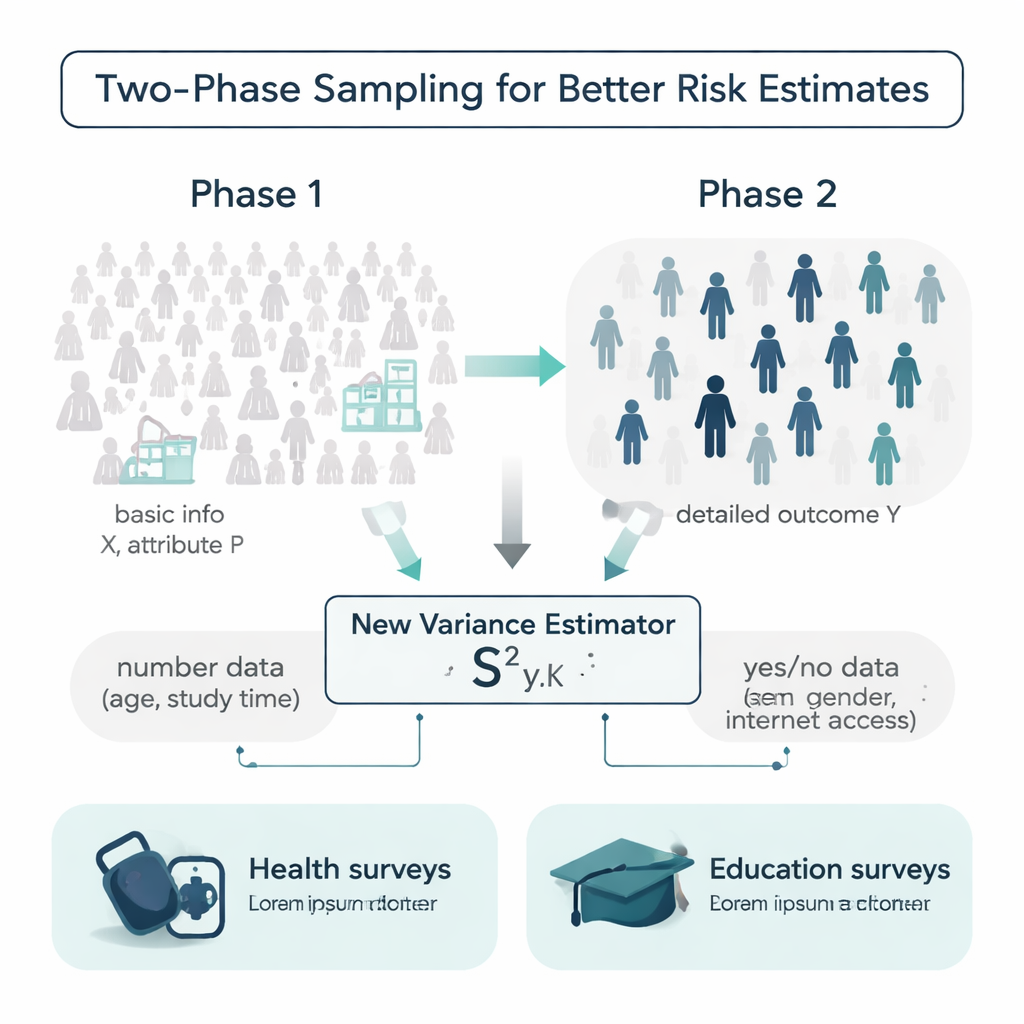
Un nuovo stimatore che usa sia variabili numeriche sia attributi binari
La maggior parte degli strumenti tradizionali per misurare la variabilità si basa solo sull’esito stesso o su una singola variabile ausiliaria e spesso assumono che i dati seguano comodi schemi a campana. Gli autori propongono un nuovo stimatore della varianza che utilizza contemporaneamente due tipi di informazione aggiuntiva: un aiuto numerico (per esempio età o ore settimanali di studio) e un attributo sì/no (come il genere o l’accesso a internet). Mostrano matematicamente come si comporta questo stimatore “misto”, ricavando formule per il suo bias e per l’errore quadratico medio—due misure chiave di accuratezza. Sotto condizioni ragionevoli, lo stimatore è praticamente non distorto e il suo errore atteso è inferiore a quello di formule concorrenti ampiamente usate, il che significa che dovrebbe fornire stime di incertezza più precise con la stessa quantità di dati.
Valutare le prestazioni in molti scenari di dati
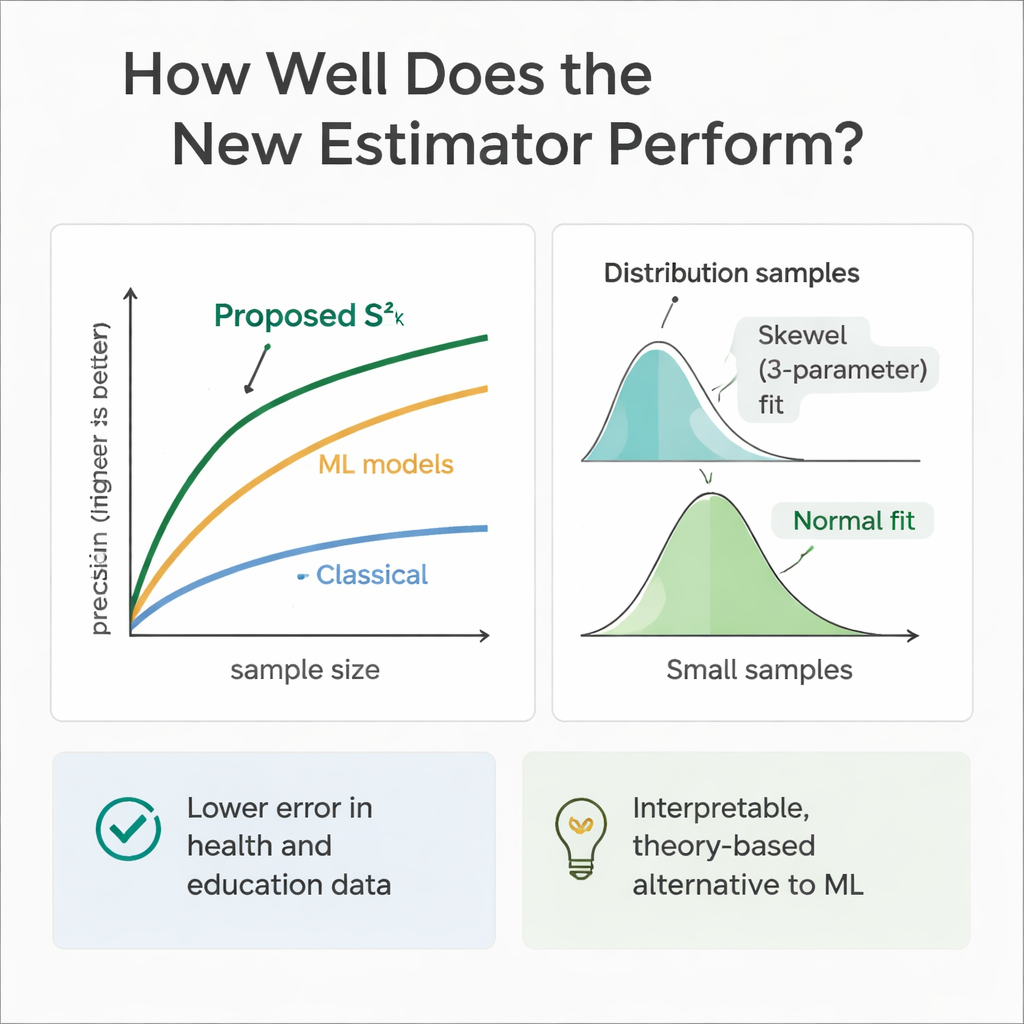
Per verificare se la teoria si rispecchia nella pratica, il gruppo ha eseguito estesi esperimenti al computer. Hanno simulato popolazioni in cui le variabili ausiliarie e l’esito seguivano una gamma di distribuzioni, da quelle simmetriche (Normale e Uniforme) a quelle asimmetriche (Gamma e Weibull). Utilizzando campionamenti ripetuti, hanno confrontato l’errore del nuovo stimatore con quello di diversi metodi consolidati su molteplici dimensioni del campione. In quasi tutti gli scenari, e specialmente al crescere della dimensione del campione, il nuovo approccio ha mostrato un’efficienza relativa molto più alta—spesso riducendo l’errore del 30–70 percento rispetto allo stimatore classico della varianza. Gli autori hanno anche esaminato come si comporta la distribuzione campionaria dello stimatore, trovando che per campioni moderati una curva Weibull a tre parametri la descrive meglio, mentre tende a una forma Normale al crescere della dimensione del campione.
Dati reali da cliniche e aule
Il metodo è stato quindi applicato a due studi di caso reali. In un dataset sanitario, l’esito era la pressione sistolica, con l’età come variabile numerica ausiliaria e il genere come attributo binario. In un dataset educativo, l’esito era il voto finale del corso, l’ausiliaria erano le ore settimanali di studio e l’attributo indicava se lo studente avesse accesso a internet. In entrambi i casi, lo stimatore proposto ha prodotto il più basso errore quadratico medio fra tutti i concorrenti statistici testati, restringendo in modo sostanziale la variabilità stimata attorno alla pressione media e alla performance media degli studenti. Questo miglioramento si traduce in intervalli di confidenza più precisi e in confronti fra gruppi o interventi più affidabili.
Come si confronta con il machine learning
Poiché i modelli di machine learning eccellono nella previsione, gli autori hanno anche addestrato alberi di regressione, random forest e support vector regression sugli stessi scenari simulati di salute e istruzione. Questi modelli, alimentati con le stesse variabili ausiliarie, spesso eguagliavano o superavano leggermente il nuovo stimatore in termini di pura accuratezza predittiva. Tuttavia, si comportano come scatole nere: è difficile tracciare esattamente come combinino le informazioni e mancano delle formule esplicite necessarie per l’inferenza classica in ambito di indagini. Lo stimatore proposto, al contrario, è trasparente e radicato nella teoria del campionamento, il che lo rende più facilmente giustificabile in contesti regolatori, clinici o politici dove la spiegabilità conta tanto quanto la prestazione pura.
Cosa significa per le indagini pratiche
In termini pratici, questo lavoro mostra che i ricercatori possono ottenere misure di dispersione più affidabili senza aumentare drasticamente le dimensioni dei campioni, semplicemente facendo un uso disciplinato di informazioni aggiuntive minime che spesso già raccolgono. Integrando un fattore numerico (come età o tempo di studio) con un semplice attributo sì/no (come genere o accesso a internet) in un piano di campionamento a due fasi, il nuovo stimatore fornisce stime della varianza più nette e più stabili rispetto a metodi di lunga data. Pur rimanendo gli strumenti avanzati di machine learning utili come confronti di riferimento, questo approccio offre un terreno intermedio pratico e interpretabile, aiutando gli analisti dei settori salute e istruzione a trarre conclusioni più solide da dati limitati.
Citazione: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
Parole chiave: campionamento per indagine, stima della varianza, machine learning, dati sanitari, ricerca educativa