Clear Sky Science · it
Generalizzabilità e trasferibilità dei modelli di apprendimento automatico che utilizzano dati di riflettanza iperspettrale per i caratteri del mais
Perché scansionare le foglie delle piante è importante per il nostro cibo futuro
Nutrire una popolazione in crescita in un clima che cambia richiede colture capaci di prosperare in condizioni di caldo, siccità e altri stress. I miglioratori vogliono sapere quali piante possiedono la giusta combinazione di struttura fogliare, chimica e prestazioni fotosintetiche, ma misurare direttamente questi caratteri su migliaia di piante è lento e distruttivo. Questo studio esplora se la semplice scansione delle foglie di mais con un sensore iperspettrale, unita all’apprendimento automatico, possa sostituire in modo affidabile le misurazioni di laboratorio laboriose, anche quando le piante sono coltivate in anni diversi e in condizioni di campo variabili.
Le “impronte” luminose delle foglie di mais
Ogni foglia riflette la luce secondo uno schema che dipende dai suoi pigmenti, dal contenuto d’acqua e dalla struttura interna. I sensori iperspettrali catturano questo schema su centinaia di lunghezze d’onda, dal visibile al vicino infrarosso a onde corte, creando una dettagliata “impronta” per ogni foglia. I ricercatori hanno raccolto tali impronte da una popolazione diversificata di mais coltivata in tre stagioni di campo consecutive, insieme a 25 caratteri che descrivono l’anatomia fogliare (come l’area fogliare specifica e l’equilibrio carbonio–azoto), gli scambi gassosi (come le foglie assorbono CO2 e perdono acqua) e la fluorescenza della clorofilla (una finestra sull’efficienza e la regolazione della fotosintesi). Questo ricco set di dati ha permesso di testare quanto bene diversi modelli statistici potessero convertire gli spettri della luce in stime dei caratteri.
Insegnare alle macchine a leggere le foglie
Il team si è concentrato su due approcci di apprendimento automatico ampiamente usati e relativamente semplici: la regressione a minimi quadrati parziali (PLSR) e la regressione con support vector lineare (SVR). Entrambi i metodi comprimono gli spettri altamente dettagliati in un insieme più piccolo di caratteristiche informative prima di collegarle ai caratteri misurati. Gli scienziati hanno confrontato con attenzione i modi per sintonizzare i modelli, in particolare il numero di componenti da usare in PLSR, e come evitare l’overfitting. Hanno inoltre esaminato se fosse meglio alimentare i modelli con misure di singole foglie, medie provenienti da una singola parcella o medie su tutte le piante dello stesso genotipo. Un rigoroso schema di validazione incrociata annidata — essenzialmente cicli ripetuti di addestramento e test — è stato usato per verificare prestazioni e incertezze.
Quali caratteri sono più facili da prevedere
Alcuni caratteri fogliari si sono rivelati molto più “leggibili” dagli spettri luminosi rispetto ad altri. I caratteri strutturali e biochimici, come l’area fogliare specifica e il contenuto di azoto, sono stati predetti con alta accuratezza, soprattutto quando i dati venivano mediati a livello di genotipo per ridurre il rumore di misura. Alcune caratteristiche della capacità fotosintetica e alcuni indicatori di fluorescenza della clorofilla legati al comportamento del fotosistema II sotto luce hanno mostrato una prevedibilità moderata. Al contrario, i caratteri legati a processi rapidi e di breve durata — come la velocità con cui le foglie attivano o rilasciano meccanismi protettivi di dissipazione dell’energia — sono stati poco catturabili. Per questi ultimi, il segnale spettrale è o troppo debole o facilmente sovrastato da variazioni ambientali nel momento della misura.
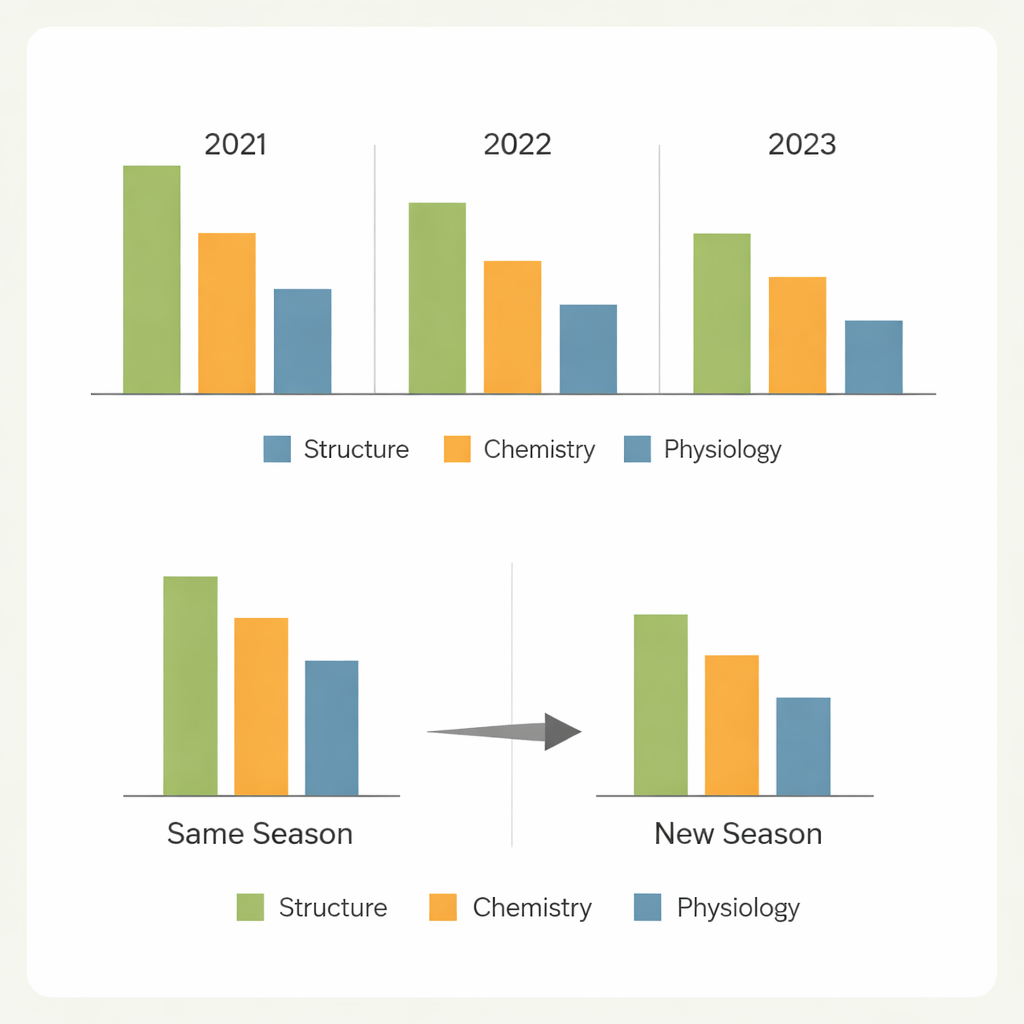
Da una stagione all’altra
Una domanda chiave per il miglioramento genetico reale è se un modello addestrato in un set di condizioni possa essere attendibile in un altro. Quando i modelli prevedevano piante casuali all’interno della stessa stagione, le prestazioni sono state generalmente buone per i caratteri più facili. Prevedere genotipi completamente nuovi coltivati nella stessa stagione ha comportato solo cali modesti per i caratteri strutturali e correlati all’azoto, ma diminuzioni molto maggiori per i caratteri di scambio gassoso. La prova più severa — prevedere nuovi genotipi in un anno diverso — ha rivelato perdite marcate in accuratezza, particolarmente per i caratteri fortemente modellati dall’ambiente. Differenze nel clima, nelle condizioni del campo e nella composizione dei genotipi hanno modificato gli schemi spettrali a sufficienza da limitare la trasferibilità, con una stagione che si è distinta come particolarmente difficile da prevedere a partire dalle altre.
Cosa significa per il miglioramento genetico e il telerilevamento
Per i miglioratori e gli scienziati delle colture, lo studio offre al contempo incoraggiamento e cautela. La scansione iperspettrale combinata con modelli di apprendimento automatico relativamente semplici è già uno strumento potente per la stima ad alta produttività di caratteri stabili e integrativi come la struttura fogliare e lo stato dell’azoto, e può generalizzare ragionevolmente bene tra genotipi e anni per questi target. Tuttavia, lo stesso approccio è molto meno affidabile per caratteri fisiologici rapidi e sensibili all’ambiente quando i modelli sono applicati al di fuori delle condizioni su cui sono stati addestrati. Gli autori concludono che i metodi iperspettrali sono pronti a supportare lo screening su larga scala di alcuni caratteri chiave del mais, ma che prevedere il comportamento fisiologico dinamico attraverso gli ambienti richiederà dati di addestramento più ricchi, modellizzazione più avanzata e forse tipi aggiuntivi di misurazioni.
Citazione: Xu, R., Ferguson, J., Breil-Aubert, M. et al. Generalizability and transferability of machine learning models using hyperspectral reflectance data for maize traits. Sci Rep 16, 5865 (2026). https://doi.org/10.1038/s41598-026-36819-1
Parole chiave: riflettanza iperspettrale, mais, apprendimento automatico, fenotipizzazione delle piante, fotosintesi