Clear Sky Science · it
Modellazione tassonomica e classificazione nella segnalazione dei guasti dell’hardware spaziale
Trovare schemi nei guasti del volo spaziale
Ogni missione nello spazio dipende da innumerevoli componenti hardware che funzionino senza intoppi, dai bulloni e cavi ai sistemi di supporto vitale. Quando qualcosa va storto, gli ingegneri redigono dettagliati rapporti di discrepanza, ma la NASA ora dispone di più di 54.000 di questi documenti—troppi perché le persone possano leggerli uno per uno. Questo studio mostra come gli strumenti moderni di linguaggio e apprendimento automatico possano trasformare quella montagna di testo in conoscenza organizzata, aiutando gli ingegneri a individuare schemi nei guasti, migliorare i progetti e mantenere gli astronauti più sicuri.
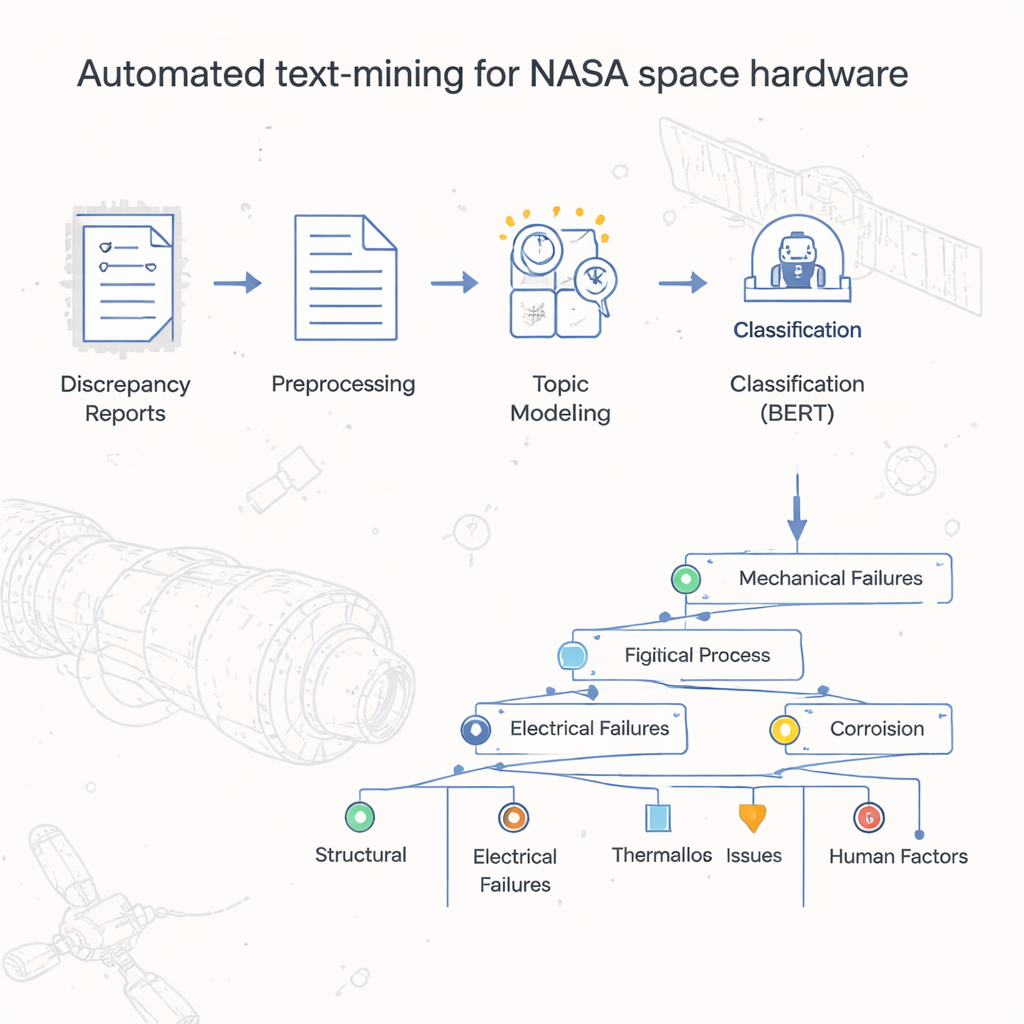
Dalle pile di rapporti a intuizioni organizzate
Per decenni, il Johnson Space Center della NASA ha archiviato i rapporti di guasto e discrepanza dell’hardware come documenti digitali, simili a versioni scansionate di vecchi moduli cartacei. I conteggi di base in fogli di calcolo rivelavano quali codici di difetto ufficiali apparivano più spesso, ma la vera storia—le cause specifiche, le azioni e le condizioni che hanno portato ai problemi—era sepolta nei campi testuali liberi. Leggere e classificare a mano oltre 54.000 record sarebbe stato proibitivamente dispendioso in termini di tempo. Gli autori si sono posti l’obiettivo di costruire un metodo automatizzato per classificare e raggruppare questi rapporti, creando una sorta di “mappa” o tassonomia che catturi come l’hardware spaziale effettivamente si guasta nella pratica quotidiana.
Insegnare ai computer a leggere il linguaggio ingegneristico
Il team ha prima pulito il testo di ogni rapporto in modo che i computer potessero lavorarci efficacemente. Hanno rimosso simboli e cifre spurie che aumentavano il rumore, suddiviso le frasi in parole individuali e convertito queste ultime in una forma di base più semplice (per esempio, trasformando “perduto” e “perdendo” in “perdita”). Sono state filtrate le parole comuni che hanno poco significato, come “il” o “e”. Una volta standardizzato il testo, i ricercatori lo hanno convertito in numeri che gli algoritmi di apprendimento automatico possono gestire, usando tecniche consolidate che catturano quanto spesso le parole compaiono e quanto caratterizzano un documento. Questa preparazione ha permesso loro di applicare strumenti potenti originariamente sviluppati per compiti linguistici generali al mondo altamente specializzato dei rapporti sull’hardware spaziale.
Costruire un albero dei tipi di guasto
Al centro del progetto c’è un modello in due fasi che gli autori chiamano LDA-BERT. Il primo passo, Latent Dirichlet Allocation (LDA), scopre automaticamente i temi—detti topic—cercando schemi di parole che tendono a comparire insieme attraverso migliaia di rapporti. Un singolo rapporto può mescolare diversi topic, rispecchiando la realtà in cui un problema hardware può avere più cause concorrenti. Il secondo passo utilizza BERT, un moderno modello linguistico, per verificare e affinare quanto bene questi topic separino i rapporti. Trattando i topic LDA come etichette provvisorie e addestrando BERT a prevederle, i ricercatori hanno potuto identificare il numero e la combinazione di topic che fornivano classificazioni stabili e accurate. Hanno poi suddiviso ulteriormente ogni topic in sottotopic, usando clustering e controlli statistici, per costruire una tassonomia ramificata che organizza i rapporti di guasto dai codici di difetto generali fino ad etichette dettagliate a livello di processo.
Trasformare le tassonomie in trend azionabili
Una volta stabilita la tassonomia, il team l’ha visualizzata con dashboard e strumenti interattivi. Ogni ramo e sottoramo dell’albero poteva essere collegato ad altre informazioni nei rapporti: quando un problema è stato rilevato per la prima volta, quanto tempo ha richiesto la chiusura, quale organizzazione era responsabile e quale decisione finale è stata presa. I grafici temporali hanno mostrato se certi tipi di problemi—come mancanze nell’ispezione o questioni legate ai dati di tolleranza—diventavano più o meno comuni nel corso degli anni. Mappe di parole fornivano un’immediata percezione del linguaggio usato in ogni cluster senza dover leggere tutti i rapporti. Queste visualizzazioni aiutano i responsabili a concentrarsi sui guasti di processo ad alto trend e alto impatto, guidando formazione, modifiche procedurali o aggiornamenti di progetto dove avranno maggiore effetto.
Limiti dell’indagine automatica delle cause radice
I ricercatori hanno anche esplorato strumenti che cercano di andare oltre l’etichettatura e l’individuazione di trend per inferire relazioni di causa-effetto direttamente dal testo. Hanno testato sistemi come INDRA-Eidos e set di regole personalizzate sviluppati con la libreria linguistica spaCy. Sebbene questi strumenti potessero estrarre alcune coppie causa-effetto e visualizzarle come reti interattive, molti dei collegamenti suggeriti risultavano troppo vaghi o confusi per essere utili. In pratica, i modelli hanno faticato perché i rapporti originali spesso non esplicitavano chiaramente le cause profonde; gli ingegneri le lasciavano sottintese o per indagini successive. Lo studio conclude che automatizzare in modo affidabile la scoperta delle cause radice richiederebbe sia una compilazione dei dati più ricca—ad esempio campi espliciti per le cause probabili—sia un addestramento di modelli altamente personalizzato e quindi più costoso di quanto giustifichi questa singola analisi.
Perché questo conta per le missioni future
Trasformando un grande archivio non strutturato di rapporti di guasto in una tassonomia chiara e stratificata, questo lavoro offre alla NASA un modo pratico per monitorare come e perché i problemi hardware emergono nel tempo. Sebbene i metodi non possano ancora sostituire il giudizio umano per un’analisi profonda delle cause radice, eccellono nello scansionare grandi quantità di testo per mettere in evidenza dove i problemi si stanno concentrando e quali tipi di processi tendono a essere coinvolti. Questo genere di allerta precoce e intuizione strutturata può aiutare i team di ingegneria a mirare la loro attenzione, affinare le procedure e progettare sistemi più robusti—passi concreti verso missioni più sicure e affidabili verso la Luna, Marte e oltre.
Citazione: Palacios, D., Hill, T.R. Taxonomical modeling and classification in space hardware failure reporting. Sci Rep 16, 5868 (2026). https://doi.org/10.1038/s41598-026-36813-7
Parole chiave: guasti dell’hardware spaziale, elaborazione del linguaggio naturale, topic modeling, analisi del rischio ingegneristico, rapporti di discrepanza NASA