Clear Sky Science · it
Rappresentazione collaborativa e apprendimento semisupervisionato guidato dalla fiducia per la classificazione di immagini iperspettrali
Occhi più acuti sui colori nascosti della Terra
Dal monitoraggio della salute delle colture al controllo delle zone umide, gli scienziati si affidano sempre più alle immagini iperspettrali—fotografie dettagliate che catturano dozzine o addirittura centinaia di colori che i nostri occhi non percepiscono. Questi dati ricchi promettono mappe più accurate dell’uso del suolo e della vegetazione, ma sono notoriamente difficili da analizzare. Questo studio presenta un nuovo metodo, chiamato GCN-ARE, che interpreta queste immagini complesse in modo più affidabile ed efficiente, aprendo la strada a un monitoraggio ambientale migliore, a un’agricoltura più intelligente e a una pianificazione urbana migliorata.
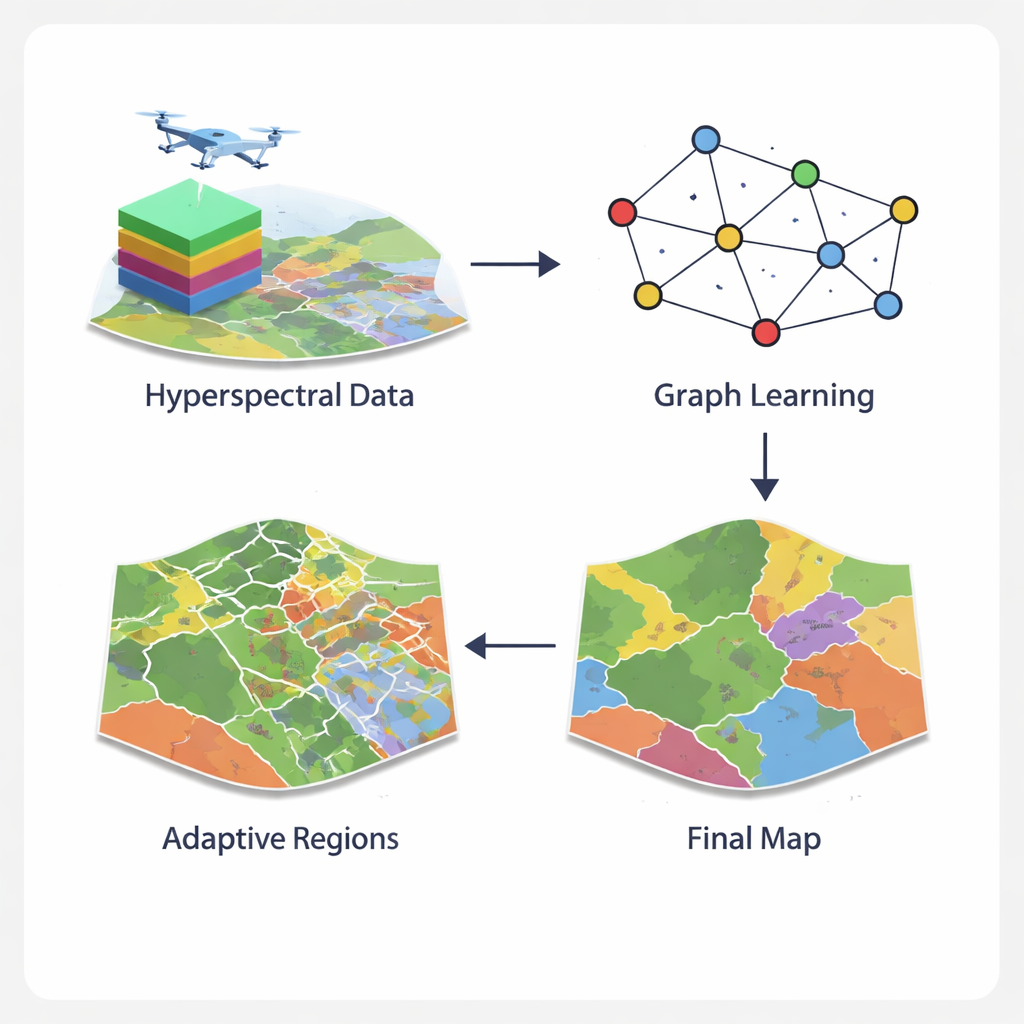
Perché le immagini iperspettrali sono così insidiose
A differenza di una foto ordinaria, un’immagine iperspettrale registra uno spettro cromatico completo per ogni pixel. Questo permette agli scienziati di distinguere, per esempio, erba sana da erba stressata o tipi di colture diversi che appaiono quasi identici nelle immagini convenzionali. Ma questa ricchezza crea sfide. Aree vicine possono mescolare molti tipi di copertura del suolo, le classi sono spesso sbilanciate (alcune coperture sono rare) e il terreno può essere irregolare—pensate a vegetazione frammentata o a blocchi urbani intrecciati. L’apprendimento automatico tradizionale dipende da caratteristiche costruite a mano e spesso perde pattern sottili, mentre le reti profonde moderne come le convolutional neural network e i Transformer possono faticare con forme irregolari e richiedono grandi risorse computazionali. Di conseguenza, modelli che funzionano bene su una scena possono fallire su un’altra.
Trasformare i pixel in una rete intelligente
Il framework GCN-ARE affronta questi problemi ripensando la rappresentazione delle immagini iperspettrali. Invece di trattare ogni pixel isolatamente o costringerli in vicinanze quadrate rigide, il metodo costruisce un grafo—una rete in cui i pixel sono nodi e i pixel vicini sono collegati. Un operatore di grafo specializzato mantiene stabile il flusso di informazioni, prevenendo problemi numerici che possono compromettere l’addestramento quando il territorio è disomogeneo. Una rete convoluzionale su grafo quindi diffonde e affina l’informazione lungo questa rete, combinando ciò che ogni pixel “vede” nel suo spettro con quanto rivelano i suoi vicini. Questa visione a grafo cattura layout spaziali complessi, come confini di campo frastagliati o vegetazione urbana frammentata, in modo più naturale rispetto ai filtri d’immagine standard.
Ridurre le regioni complesse alla dimensione giusta
Anche con un potente modello a grafo, alcune parti di un’immagine restano difficili da classificare—per esempio, zone di confine dove le colture incontrano le strade o dove la vegetazione si mescola con il suolo nudo. GCN-ARE affronta questo problema suddividendo adattivamente la scena in regioni in base a quanto bene vengono classificate. Se una regione performa male, viene automaticamente suddivisa in pezzi più piccoli e più uniformi usando un passaggio di clustering che raggruppa pixel simili. Questo processo è guidato da regole statistiche, quindi non è solo un espediente visivo: gli autori dimostrano che, in teoria, queste divisioni riducono l’errore atteso del modello, aiutandolo a distinguere differenze sottili nella copertura del suolo in modo più affidabile.
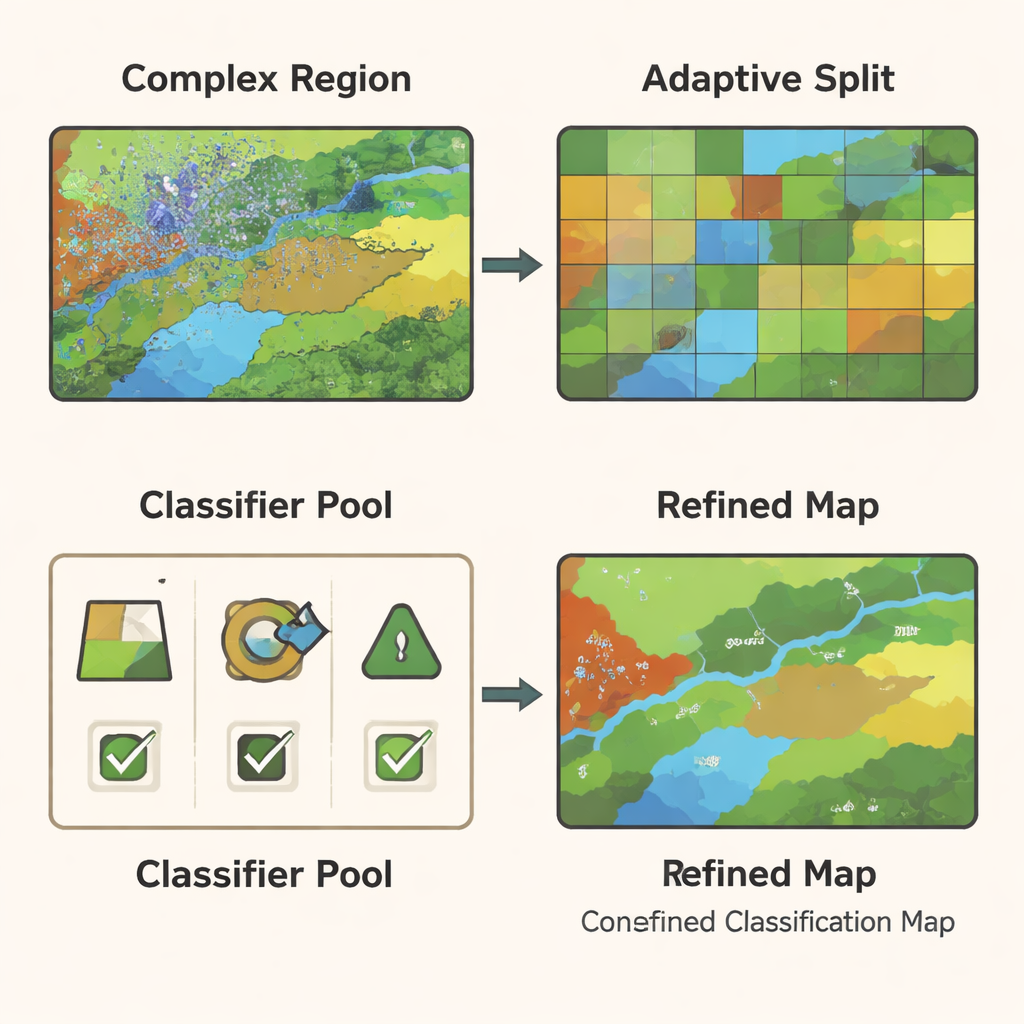
Lasciare che più classificatori votino—ma in modo intelligente
Diversi tipi di classificatori—come alberi decisionali, macchine a vettori di supporto e random forest—eccellono in condizioni diverse. Piuttosto che puntare su un singolo modello, GCN-ARE addestra un piccolo insieme di questi classificatori sulle caratteristiche basate sul grafo e poi sceglie tra di essi regione per regione. La scelta non è lasciata al caso: uno strumento matematico chiamato disuguaglianza di Hoeffding viene usato per mostrare che, quando una regione contiene più dati, la probabilità di scegliere il classificatore effettivamente migliore aumenta rapidamente. Durante l’uso, il sistema confronta le predizioni dei classificatori. Se sono d’accordo, accetta la decisione di consenso; se non concordano, attiva il classificatore "migliore" selezionato per quella regione. Questo ensemble adattivo rende la mappa finale stabile nelle aree semplici e più precisa in quelle difficili.
Dimostrare che funziona nel mondo reale
Gli autori hanno testato GCN-ARE su quattro dataset ben noti: zone umide in Botswana, un’area urbana intorno a Houston, aree agricole in Indiana (Indian Pines) e una scena agricola ad alta risoluzione in Cina (WHU‑Hi‑LongKou). In tutti questi casi, il loro metodo ha raggiunto una maggiore accuratezza complessiva, una migliore accuratezza media per classe e punteggi di concordanza più elevati rispetto ad approcci di punta come le graph attention network e i Vision Transformer—migliorando tipicamente l’accuratezza complessiva di circa 1,5 fino a 5,7 punti percentuali. Si è dimostrato particolarmente efficace nel riconoscere classi rare e confini complessi, e lo ha fatto con tempi e memoria di calcolo modestI. Esperimenti di ablazione hanno mostrato che sia la suddivisione adattiva delle regioni sia l’ensemble dinamico sono essenziali—rimuoverne uno dei due riduceva sensibilmente le prestazioni.
Cosa significa per le applicazioni quotidiane
In termini pratici, GCN-ARE è un modo più intelligente per trasformare dati iperspettrali grezzi in mappe affidabili. Combinando una rappresentazione a grafo stabile, un raffinamento mirato delle regioni e una selezione del modello fondata su basi statistiche, produce mappe della copertura del suolo più chiare anche quando i dati etichettati per l’addestramento scarseggiano e il paesaggio è disordinato. Per gli agricoltori, questo potrebbe significare un monitoraggio delle colture più preciso con meno rilevamenti sul campo; per le agenzie ambientali, un tracciamento più affidabile di zone umide, foreste o espansione urbana. Sebbene il metodo attuale affronti ancora sfide su scale realmente massive, gli autori delineano percorsi per renderlo più veloce e leggero, suggerendo che strumenti di mappatura adattivi e guidati dalla fiducia diventeranno sempre più importanti man mano che i sensori iperspettrali si diffusero da satelliti ad aerei e droni.
Citazione: Chen, Y., Lu, H. & Huang, X. Collaborative representation and confidence-driven semi-supervised learning for hyperspectral image classification. Sci Rep 16, 6180 (2026). https://doi.org/10.1038/s41598-026-36806-6
Parole chiave: imaging iperspettrale, mappatura dell’uso del suolo, reti neurali a grafo, apprendimento ensemble, telerilevamento