Clear Sky Science · it
Verifica dell’autenticità delle notizie in urdu usando deep learning con embedding concatenati BERT e GloVe
Perché individuare le fake news in urdu è importante
In Pakistan e nel resto del mondo, sempre più persone ricavano le notizie da siti web e dai social media piuttosto che da giornali o televisione. Questo cambiamento ha reso più facile che mai la rapida diffusione di storie false, soprattutto nelle lingue nazionali come l’urdu, dove gli strumenti digitali sono limitati. Questo studio affronta una domanda semplice ma urgente: l’intelligenza artificiale moderna può distinguere automaticamente le notizie urdu vere da quelle false, aiutando i lettori comuni, i giornalisti e le piattaforme a difendersi dalle informazioni fuorvianti?
La crescente sfida della disinformazione online
Gli autori iniziano descrivendo come titoli fabbricati e storie distorte possano modellare l’opinione pubblica, alimentare tensioni politiche e perfino danneggiare la salute e le finanze delle persone. Mentre molti siti di fact-checking e progetti di ricerca si concentrano sull’inglese, le lingue regionali come l’urdu vengono spesso trascurate. Le risorse esistenti in urdu comprendono solo poche migliaia di articoli, molti tradotti dall’inglese e focalizzati su temi ristretti come la politica. Ciò rende difficile addestrare sistemi informatici affidabili a riconoscere contenuti sospetti nella lingua che la maggior parte dei pakistani legge realmente.
Costruire una grande raccolta di notizie in urdu
Per colmare questa lacuna, i ricercatori hanno assemblato quella che descrivono come la più ampia raccolta di fake news in urdu finora, contenente 14.178 articoli raccolti tra il 2017 e il 2023 da rinomati siti di informazione pakistani e piattaforme online. Le storie coprono quindici ambiti della vita quotidiana, inclusi politica, salute, istruzione, economia, criminalità, sport e ambiente. Utilizzando fonti di fact-checking come PolitiFact, FactCheck e API di notizie specializzate, ogni voce è stata etichettata come vera o falsa; gli elementi parzialmente veri sono stati raggruppati con le notizie vere per riflettere una rendicontazione più sfumata. Il team ha quindi pulito i testi rimuovendo duplicati, indirizzi web e punteggiatura superflua, segmentando le frasi in parole e eliminando le parole di riempimento molto comuni.
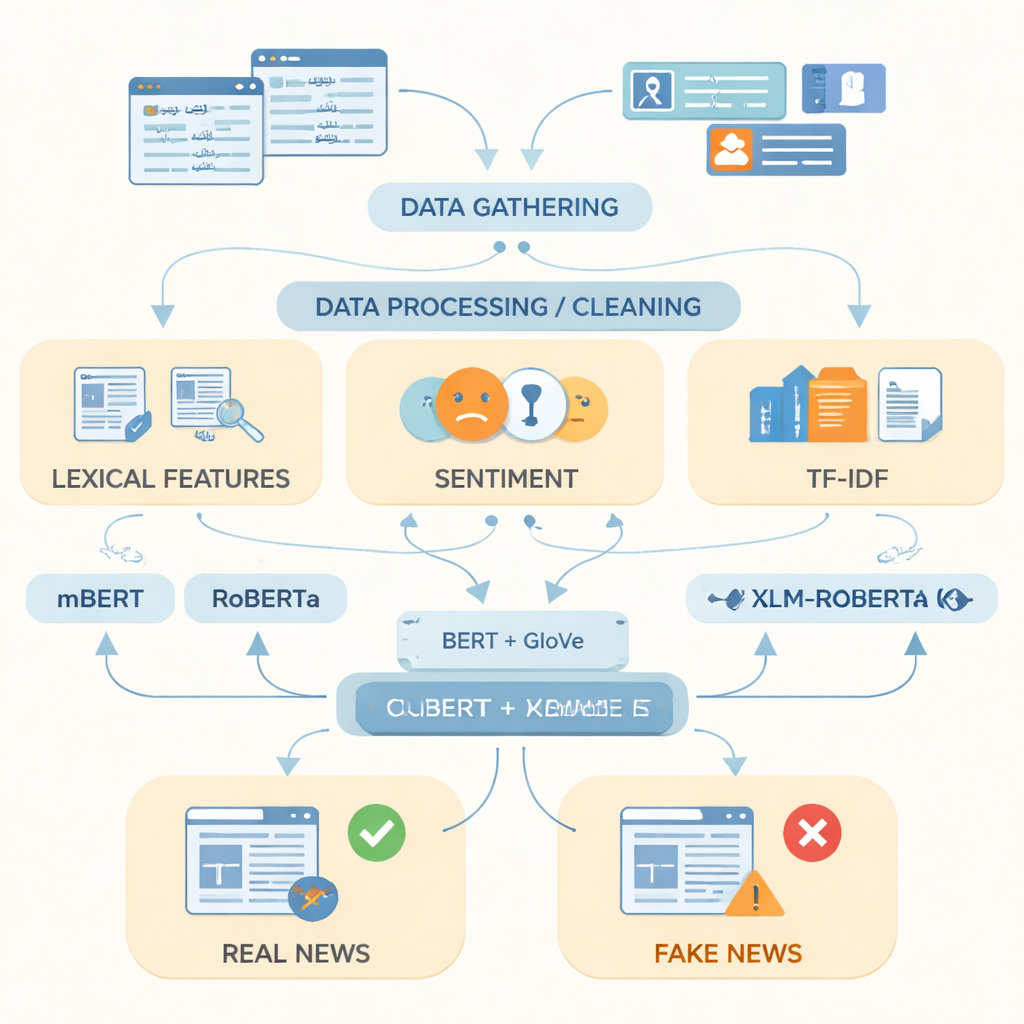
Insegnare ai computer l’aspetto delle fake news
Dopo aver preparato i dati, gli autori si sono concentrati su come rappresentare al meglio il testo urdu per un computer. Hanno combinato indicatori semplici come parole usate frequentemente, tono emotivo del linguaggio e punteggi di frequenza dei termini con due potenti tecniche di rappresentazione delle parole. Una, chiamata GloVe, tratta ogni parola come un vettore numerico fisso basato sulla frequenza con cui appare insieme ad altre parole nell’intera raccolta. L’altra, basata su modelli in stile BERT, considera ogni parola nel suo contesto di frase e le assegna un significato sensibile al contesto. Unendo queste due prospettive linguistiche in una singola rappresentazione più ricca, il sistema può catturare sia i pattern generali sia le sottili variazioni di formulazione che spesso distinguono storie false da quelle vere.
Mettere alla prova modelli linguistici avanzati
I ricercatori hanno quindi fornito queste rappresentazioni a tre moderni modelli di deep learning che sono stati addestrati su testi in molte lingue: mBERT, RoBERTa e XLM-RoBERTa. Tutti e tre sono stati fine-tuned sul dataset in urdu per prevedere se ogni articolo fosse vero o falso. Le loro prestazioni sono state valutate con misure standard: accuratezza (quanto spesso erano corretti), precisione (quanto spesso le segnalazioni di falso erano effettivamente false), recall (quante delle notizie false totali hanno individuato) e F1-score, che equilibra precisione e recall. Pur mostrando buone prestazioni tutte le varianti, XLM-RoBERTa combinato con la rappresentazione fusa BERT e GloVe si è imposto, classificando correttamente circa il 96% degli articoli di test e ottenendo un F1-score di 0,956—meglio dei precedenti sistemi per le fake news in urdu che usavano dataset più piccoli o metodi più semplici.
Cosa significa per i lettori di tutti i giorni
Per i non specialisti, il messaggio è chiaro: con una quantità sufficiente di dati di qualità sulle notizie in urdu e il tipo giusto di IA, è ora possibile costruire strumenti che segnalano automaticamente con alta affidabilità le storie probabilmente false. Lo studio mostra che rappresentazioni linguistiche più ricche e modelli multilingue forniscono ai computer una comprensione molto migliore di come l’urdu venga realmente scritto in diverse regioni e argomenti. Sebbene il lavoro attuale si concentri solo sul testo e non analizzi ancora immagini o comportamenti sui social media, pone una solida base per sistemi futuri che potrebbero funzionare attraverso lingue e tipi di media. In termini pratici, questa ricerca avvicina il Pakistan a plug-in per browser, dashboard redazionali o filtri sui social media che aiutino le persone a separare fatti e finzione nella lingua che usano ogni giorno.
Citazione: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
Parole chiave: rilevamento delle fake news, lingua urdu, deep learning, BERT e GloVe, disinformazione online