Clear Sky Science · it
Migliorare la stima della profondità a lunga distanza tramite codifica eterogenea CNN-transformer e fusione semantica multidimensionale
Vedere la profondità con un solo occhio
Robot moderni, auto a guida autonoma e droni spesso si affidano a costosi sensori 3D per capire a quale distanza si trovano gli oggetti. Questo studio dimostra come le normali fotocamere a colori, come quelle degli smartphone, possano essere sfruttate molto più a fondo: gli autori progettano un nuovo metodo perché un computer inferisca la profondità a partire da una sola immagine, concentrandosi sulla parte più difficile da valutare della scena — le distanze maggiori, dove gli ostacoli sono piccoli, sfocati e facili da stimare male.
Perché è così difficile giudicare gli oggetti lontani
La stima della profondità da una singola immagine, detta stima monoculare della profondità, è una specie di trucco visivo. Gli oggetti vicini occupano molti pixel e hanno texture nitide, quindi le reti neurali odierne funzionano già bene a brevi e medie distanze. Più lontano, però, le auto si riducono a poche pixel e le segnaletiche stradali svaniscono nella foschia. Le reti convoluzionali standard sono efficaci nel cogliere dettagli locali fini ma faticano a cogliere il quadro globale di una strada intera. I modelli Transformer più recenti colgono bene il contesto globale, ma sono meno sensibili ai bordi e alle texture minute. Di conseguenza, entrambe le famiglie di metodi spesso inciampano proprio dove la navigazione sicura ha più bisogno di stime affidabili: a lunga distanza.
Fondere due modi di vedere
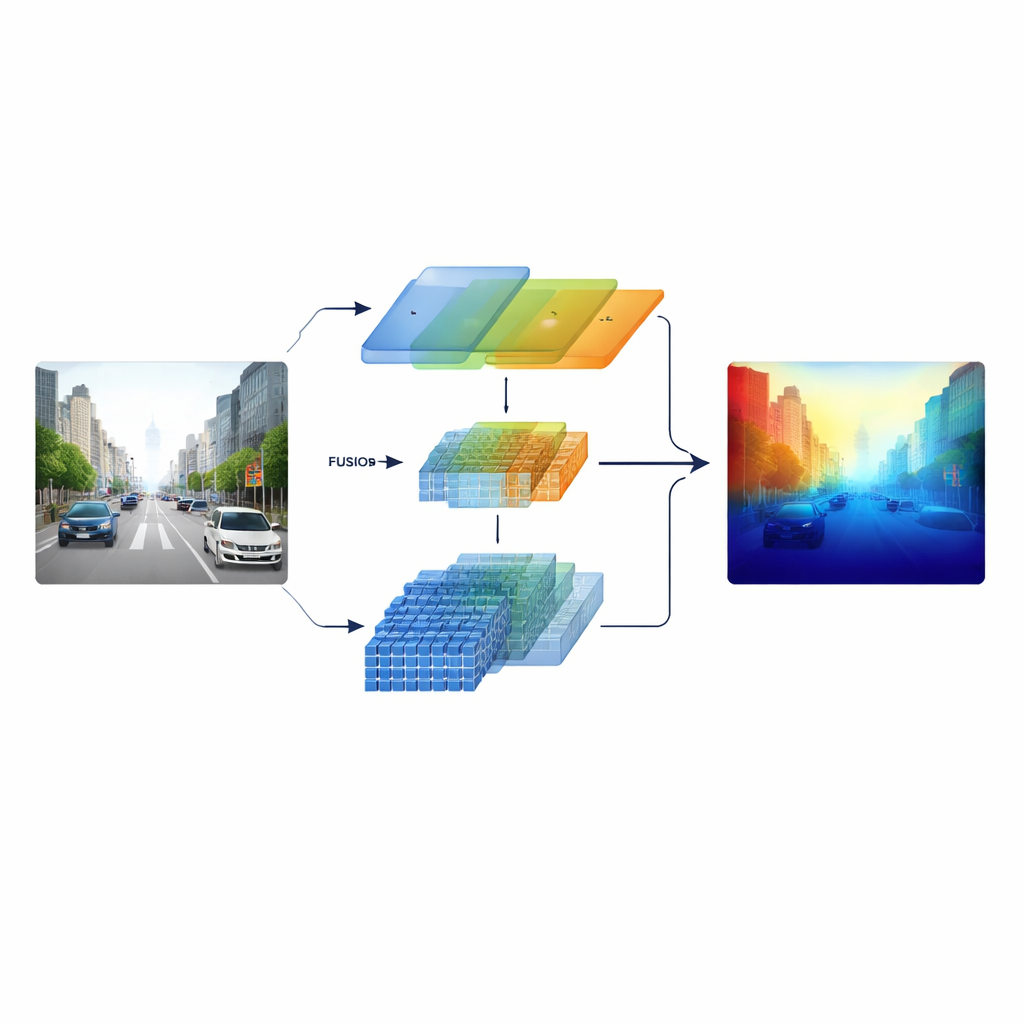
I ricercatori affrontano il problema costruendo un encoder “eterogeneo” che esegue in parallelo due diversi tipi di elaborazione visiva. Un ramo si basa su una classica rete convoluzionale in stile ResNet, specializzata in pattern locali nitidi come le segnaletiche, i pali e i bordi degli oggetti. L’altro ramo utilizza uno Swin Transformer, progettato per catturare connessioni a lungo raggio attraverso l’immagine, come l’assetto di un corridoio stradale o l’orizzonte di edifici lontani. Invece di combinare queste due visioni solo alla fine, il sistema conserva caratteristiche multi-scala da entrambi i rami e le porta in una fase di fusione attentamente progettata, in modo che struttura fine e contesto ampio si informino reciprocamente lungo tutto il processo.
Attraversare canali, spazio e scala
Al centro del modello c’è un modulo di Fusione Semantica Cross-dimensionale che funziona come una sala riunioni intelligente per i due flussi di informazione. Prima decide quali canali — diversi tipi di pattern visivi appresi — meritano più attenzione, bilanciando segnali da texture dettagliate e indizi di scena di alto livello. Poi esamina separatamente le direzioni orizzontale e verticale, particolarmente significative in scene piene di strade, edifici e alberi, per evidenziare strutture importanti che si estendono nell’immagine. Infine miscela caratteristiche superficiali ricche di dettagli con altre più profonde e astratte su più scale. Un passo di pesatura apprendibile permette alla rete di decidere quanto fidarsi di ciascun ramo per ogni regione, così i piccoli oggetti lontani non vengono sommersi dallo scenario vicino.
Rifinire l’immagine finale
Anche con buone caratteristiche fuse, trasformarle in una mappa di profondità a piena risoluzione può sfocare i bordi e far perdere strutture sottili. Per evitarlo, il team progetta un decoder guidato dall’attenzione. I suoi blocchi di upsampling usano convoluzioni depth-wise leggere per ingrandire la mappa senza perdere contesto, e un meccanismo di self-attention multi-scala raggruppa i canali di feature in modo che l’attenzione possa essere calcolata in modo efficiente. Questo passaggio affina le predizioni di profondità a ogni scala mantenendo sotto controllo il costo computazionale. Il risultato è un campo di profondità coerente e uniforme in cui i contorni degli oggetti — come il profilo di un ciclista distante o i pioli di un letto a castello — restano nitidi.
Quanto bene funziona nel mondo reale
Il metodo è testato su diversi dataset standard. Su KITTI, una vasta raccolta di scene di guida, il modello raggiunge uno stato dell’arte in molti degli indicatori comuni e, soprattutto, produce l’errore più basso nelle aree designate a lunga distanza. Offre anche bordi di profondità più puliti attorno agli oggetti rispetto ai sistemi concorrenti. Su NYU Depth V2, che contiene scene indoor, e sul benchmark SUN RGB-D, lo stesso modello si generalizza con successo, ricostruendo mobili e layout delle stanze in convincenti nuvole di punti 3D. Studi di ablazione — test sistematici che rimuovono o scambiano componenti — mostrano che ogni elemento proposto, dall’encoder ibrido al modulo di fusione e al blocco di attenzione del decoder, migliora misurabilmente le prestazioni, specialmente per le aree distanti e a bassa texture.
Cosa significa per la tecnologia di tutti i giorni
In termini semplici, questo lavoro insegna a una rete neurale a usare contemporaneamente una lente d’ingrandimento e un grandangolo, e a combinarli con giudizio. Bilanciando meglio i dettagli locali con la comprensione globale della scena, il framework proposto migliora significativamente la capacità di una singola fotocamera di valutare la profondità in fondo alla strada o attraverso una stanza. Questo rende più pratico dotare robot, veicoli e droni di sensori più economici pur fornendo loro una ricca percezione 3D del mondo — un passo importante verso sistemi autonomi più sicuri, più capaci e più accessibili.
Citazione: Chen, Y., Yin, Q., Zhao, L. et al. Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion. Sci Rep 16, 9396 (2026). https://doi.org/10.1038/s41598-026-36755-0
Parole chiave: stima della profondità monoculare, visione artificiale, fusione transformer e CNN, guida autonoma, ricostruzione di scene 3D