Clear Sky Science · it
Kernel mean matching migliora la stima del rischio in presenza di spostamenti spaziali della distribuzione
Perché è importante stimare il rischio con mappe che cambiano
I modelli di machine learning sono sempre più usati per prevedere dove vivranno le specie, come sono organizzati i tumori nei tessuti o come si diffonde l'inquinamento. Tuttavia i dati usati per addestrare questi modelli sono spesso raccolti in luoghi molto specifici—campionamenti intensi vicino a città, ospedali o siti di facile accesso—mentre i modelli vengono applicati su regioni molto più vaste e diverse. Questo disallineamento tra dove provengono i dati e dove si fanno le predizioni può far apparire i modelli più sicuri e più accurati di quanto non siano in realtà. L'articolo "Kernel mean matching enhances risk estimation under spatial distribution shifts" pone una domanda apparentemente semplice: quando il mondo appare diverso rispetto ai dati di addestramento, quanto può sbagliare il modello e come possiamo capirlo?
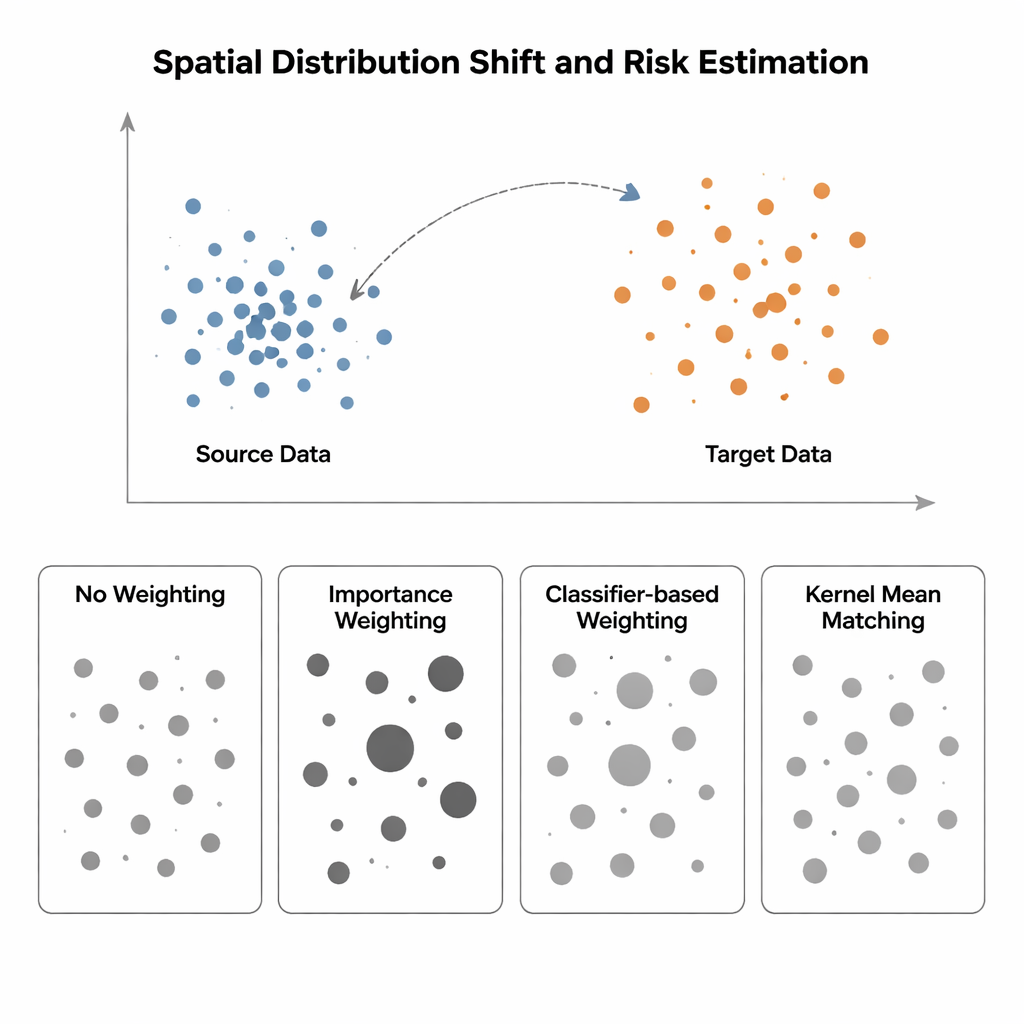
Quando addestramento e test vivono in mondi diversi
In statistica, il "rischio" di un modello è il suo errore atteso su dati nuovi e non visti. I trucchi standard di valutazione—come la cross-validation o il mantenere un set di test scelto a caso—presuppongono implicitamente che i dati di addestramento e di test siano estratti dalla stessa distribuzione. I dati spaziali infrangono questa assunzione. Gradienti ambientali, campionamenti clusterizzati e cambiamenti climatici significano che le condizioni in cui addestriamo un modello possono differire nettamente da quelle in cui lo impieghiamo. Per esempio, le osservazioni di specie sono spesso concentrate vicino alle strade, mentre le decisioni di conservazione riguardano aree remote; i campioni tumorali possono essere prelevati da una parte di un tessuto, ma le predizioni servono altrove. In questi casi, le stime convenzionali del rischio tendono a essere eccessivamente ottimistiche, nascondendo quanto male un modello potrebbe funzionare in nuove località.
Gli strumenti tradizionali faticano con il bias spaziale
Lo studio confronta quattro modi per stimare il rischio del modello quando la distribuzione degli input si sposta da una regione "sorgente" (dove le etichette sono note) a una regione "target" (dove le etichette scarseggiano o mancano). Il metodo più semplice, chiamato No Weighting, misura semplicemente l'errore medio sui dati disponibili e assume che sorgente e target siano simili—un'ipotesi che si rompe in presenza di bias spaziale. L'Importance Weighting cerca di correggere questo pesando ogni campione di sorgente in base a quanto quel tipo di punto è comune nel target rispetto alla sorgente. In teoria questo recupera il rischio corretto, ma in pratica richiede la stima di densità di probabilità in spazi ad alta dimensione. Quando i dati di sorgente sono fortemente clusterizzati e quelli di target più diffusi—una situazione tipica in ecologia spaziale o imaging medico—queste stime di densità diventano inaffidabili, e pochi campioni ricevono pesi enormi, rendendo la stima del rischio estremamente instabile. Gli approcci basati su classificatori, che addestrano un classificatore per distinguere punti di sorgente e target e convertono le sue probabilità in pesi, evitano la stima esplicita delle densità ma spesso producono stime del rischio mal calibrate perché ottimizzano l'accuratezza di classificazione, non l'allineamento delle distribuzioni.
Una via diversa: confrontare direttamente le distribuzioni
Gli autori propongono il Kernel Mean Matching (KMM), un approccio che evita del tutto la stima delle densità. Invece di cercare di calcolare quanto è probabile ogni punto sotto le distribuzioni di sorgente e target, KMM cerca pesi sui campioni di sorgente che rendano la loro "firma" media in uno spazio di caratteristiche definito da un kernel flessibile uguale a quella dei campioni target. Intuitivamente, allunga o restringe l'influenza di ciascun punto di sorgente in modo che, presi insieme, il cloud di sorgente pesato assomigli al cloud di target. Una volta trovati questi pesi, il rischio si stima come media pesata degli errori sulla sorgente. Uno strumento complementare, la Local Correlation Function, quantifica quanto i dati sono clusterizzati nello spazio; serve come diagnostico per capire quando gli spostamenti di distribuzione sono abbastanza forti da rendere utile il ripesamento.
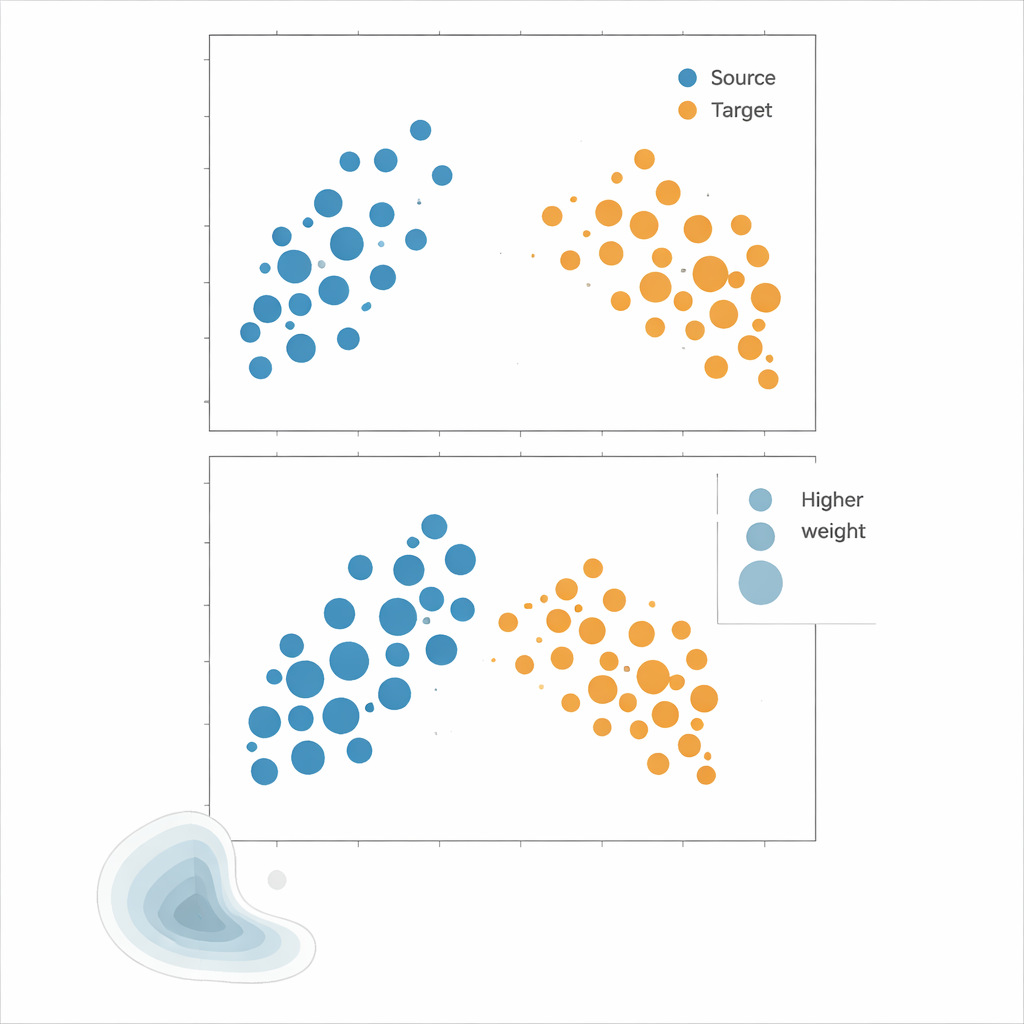
Mettere i metodi alla prova
Per capire quale strategia funzioni meglio, gli autori eseguono esperimenti estesi su dati sintetici e del mondo reale. I "paesaggi" sintetici sono costruiti da miscele di cluster gaussiani la cui dispersione, forma e copertura del dominio possono essere controllate con precisione, permettendo test strutturati come il ritaglio di parte del dominio, il cambiamento dei pattern di correlazione tra le caratteristiche o l'alternanza tra configurazioni fortemente clusterizzate e quasi uniformi. I dataset reali comprendono occorrenze di specie vegetali nordiche, descritte da clima e posizione, e layout spaziali di cellule immunitarie all'interno di tumori. In questi scenari, i modelli sono addestrati su dati sorgente clusterizzati e valutati su dati target meno clusterizzati, imitandone i bias di campionamento comuni. Le prestazioni sono valutate usando diverse metriche di errore, concentrandosi su quanto da vicino la stima del rischio di ciascun metodo segua l'errore vero sul target.
Stime del rischio più affidabili in spazi disordinati e ad alta dimensione
In quasi tutti gli scenari sintetici e nei dataset reali, KMM fornisce le stime del rischio più accurate e stabili. Riduce l'errore percentuale medio assoluto approssimativamente dal 12% fino al 87% rispetto alle alternative e, cosa cruciale, evita la "esplosione dei pesi" che affligge l'importance weighting in alte dimensioni. In layout complicati di cellule tumorali, per esempio, l'importance weighting può produrre errori che superano di diverse migliaia di percento, mentre KMM resta entro limiti gestibili. Il ripesamento basato su classificatori migliora tipicamente rispetto ai metodi ingenuo ma rimane comunque inferiore a KMM, riflettendo il suo focus sulla discriminazione piuttosto che su un fedele matching delle distribuzioni. Questi risultati suggeriscono che, per applicazioni spaziali—dove i dati sono clusterizzati, distorti e ad alta dimensionalità—KMM offre un modo rigoroso per stimare quanto fidarsi delle predizioni di un modello.
Cosa significa per le decisioni nel mondo reale
Per i non specialisti che usano il machine learning in ecologia, scienze ambientali o biomedicina, il messaggio è chiaro: i punteggi di test standard possono essere pericolosamente fuorvianti quando la regione di applicazione differisce da quella di provenienza dei dati. Il Kernel Mean Matching fornisce un modo per correggere questo riequilibrando l'influenza dei campioni di addestramento in modo che somiglino statisticamente ai luoghi o ai tessuti di interesse. Lo studio mostra che questo approccio produce in modo consistente stime di errore del modello più oneste, anche in presenza di bias spaziali severi e con molte variabili in input. In pratica, ciò significa indicazioni più affidabili nella scelta tra modelli e un quadro più chiaro su dove le predizioni sono degne di fiducia—e dove è necessario procedere con cautela.
Citazione: Serov, E., Koldasbayeva, D. & Zaytsev, A. Kernel mean matching enhances risk estimation under spatial distribution shifts. Sci Rep 16, 6921 (2026). https://doi.org/10.1038/s41598-026-36740-7
Parole chiave: shift di distribuzione, modellazione spaziale, kernel mean matching, stima del rischio del modello, dati ecologici e biomedici