Clear Sky Science · it
Rafforzare la resilienza avversaria nella cache semantica per sistemi sicuri di retrieval-augmented generation
Perché una memoria AI più intelligente è importante
Man mano che chatbot e assistenti AI entrano nei luoghi di lavoro, nelle aule e perfino negli ospedali, fanno sempre più affidamento su un trucco chiamato “ricordare” le domande passate per rispondere a quelle simili in modo più rapido ed economico. Questa memoria, nota come cache semantica, può ridurre notevolmente costi e tempi di attesa—ma può anche aprire una porta per gli aggressori che vogliono indurre il sistema a divulgare segreti o a fornire risposte errate. Questo articolo esplora quei rischi nascosti e introduce un nuovo progetto, SAFE-CACHE, che punta a mantenere la memoria dell’AI veloce rendendone molto più difficile l’abuso.
Come gli assistenti AI attuali riutilizzano risposte passate
I moderni large language model (LLM) spesso operano in una configurazione chiamata retrieval-augmented generation (RAG). Quando si pone una domanda, il sistema prima recupera documenti rilevanti e poi chiede al LLM di scrivere una risposta usando quel materiale. Poiché molte persone formulano quasi la stessa domanda con parole diverse, le aziende aggiungono ora una cache semantica: un archivio di domande e risposte passate, insieme a impronte matematiche dei loro significati. Quando arriva una nuova query, il sistema verifica se la sua impronta è “abbastanza vicina” a una già presente nella cache; in tal caso riutilizza semplicemente la vecchia risposta invece di eseguire di nuovo l’intero processo di ricerca e generazione. Questa idea, adottata da strumenti come GPTCache e dalle piattaforme cloud di Microsoft e Google, fa risparmiare e accelera le risposte in bot di supporto clienti, strumenti di chat aziendali e altri servizi AI ad alto traffico. 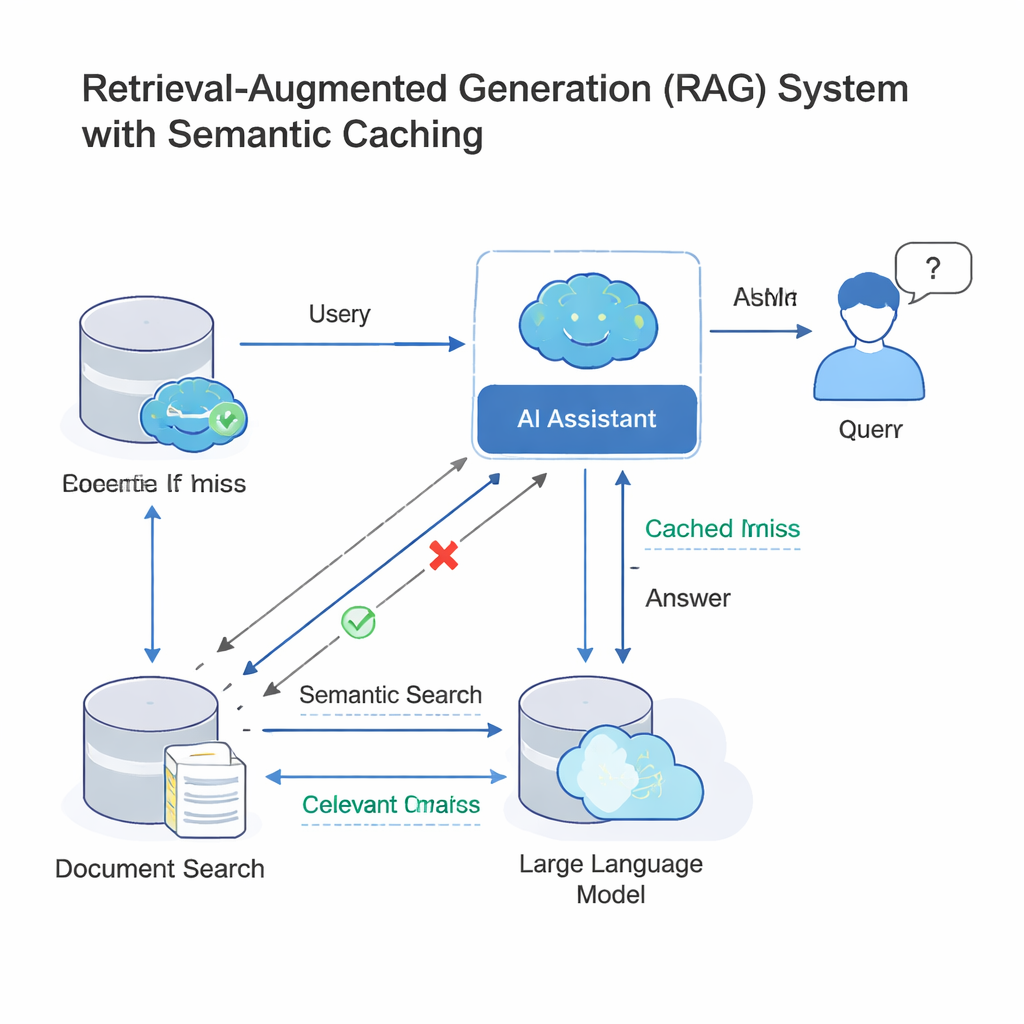
Quando una formulazione arguta diventa una falla di sicurezza
Lo stesso accorgimento che aumenta la velocità può anche essere usato contro il sistema. Gli aggressori possono creare query che sembrano simili nella struttura ma che significano qualcosa di diverso—cambiando una data, sostituendo una persona o un luogo, o invertendo il senso di una domanda. Poiché le cache attuali si basano in gran parte sulla somiglianza numerica degli embedding (quelle impronte del significato), una query malevola può “collidere” con una innocua in questo spazio vettoriale, anche se l’intento è cambiato. Quella collisione può indurre la cache a restituire la risposta sbagliata, esponendo potenzialmente informazioni riservate o permettendo che dati corrotti vengano memorizzati per riutilizzi futuri. Lavori precedenti hanno già dimostrato che basi di dati vettoriali e cache semantiche possono essere avvelenate in questo modo, specialmente quando molti utenti condividono la stessa cache in sistemi multi-tenant.
Trasformare domande sparse in cluster di intento stabili
Gli autori sostengono che il problema principale è trattare ogni query in isolamento. La loro soluzione, SAFE-CACHE, raggruppa le coppie domanda–risposta passate in cluster che rappresentano intenti sottostanti—come “chi ha vinto la corsa per il Senato dell’Arizona nel 2022?” o “qual è il prezzo del software Full Self-Driving di Tesla?” Invece di confrontare nuove query direttamente con singole precedenti, SAFE-CACHE le paragona al centroide di ciascun cluster. Per costruire questi cluster, prima incorpora (embedding) ogni domanda completa più risposta (non solo la domanda) in modo che le differenze nelle risposte—come un rifiuto a rivelare dati sensibili—contribuiscano alla formazione dei gruppi. Poi utilizza un algoritmo di rilevamento comunitario per trovare cluster naturali e test statistici per segnalare gruppi rumorosi che potrebbero mescolare intenti differenti o voci avversarie. Questi cluster sospetti vengono puliti e suddivisi usando un bi-encoder appositamente addestrato che ha imparato ad avvicinare esempi onesti e a separare quelli avvelenati.
Addestrare un modello piccolo per rafforzare la memoria dell’AI
Alcuni intenti compaiono solo poche volte nel traffico reale, rendendo i loro cluster fragili. Per stabilizzarli, SAFE-CACHE utilizza un modello di linguaggio leggero fine-tuned (una variante Gemma-3 da 1 miliardo di parametri) per generare parafrasi che mantengono lo stesso intento variando la formulazione. Questi esempi aggiuntivi rendono i cluster più densi e i loro centroidi più affidabili, senza richiedere che le persone etichettino migliaia di varianti. In fase di esecuzione, ogni nuova query viene incorporata e confrontata con questi centroidi. Se la sua similarità rispetto al centroide meglio corrispondente supera una soglia accuratamente tarata, viene restituita la risposta cache; altrimenti il sistema ricorre alla pipeline RAG completa e decide in seguito come raggruppare la nuova coppia. In esperimenti che hanno usato forti metodi di attacco basati su riscritture metamorfosiche e GPT‑4.1, SAFE-CACHE ha ridotto i tentativi di avvelenamento riusciti di circa due terzi fino a tre quarti rispetto a un design in stile GPTCache, mantenendo sostanzialmente invariata la velocità di risposta. 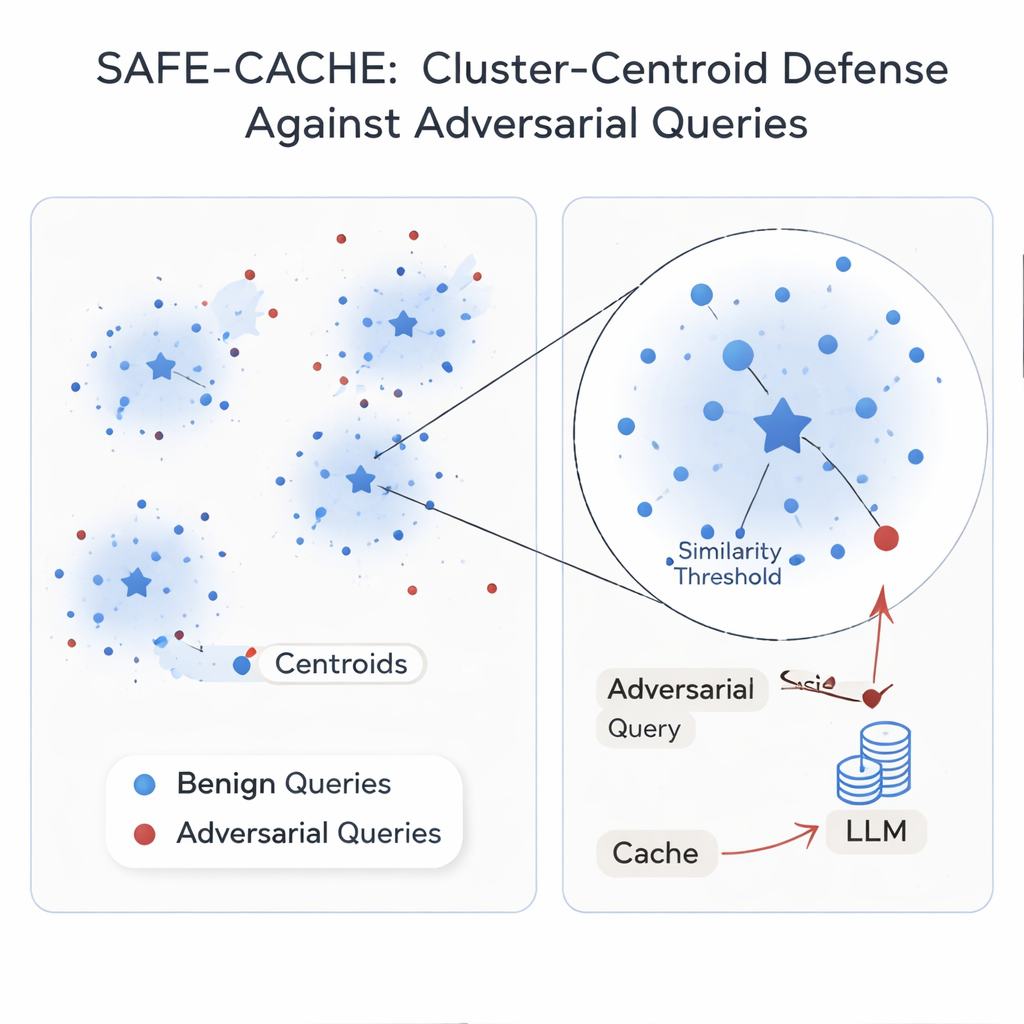
Cosa significa per gli utenti comuni dell’AI
Per i non specialisti, la conclusione è che dare “memoria” ai sistemi AI non è gratis: progetti ingenuamente semplici possono far trapelare segreti o essere ingannati nel diffondere risposte sbagliate. SAFE-CACHE dimostra che organizzando la memoria attorno a pattern più profondi a livello di intento e rinforzando quei pattern con parafrasi mirate, è possibile mantenere i benefici in termini di velocità e costi della cache semantica riducendo sensibilmente il rischio di attacco. Man mano che gli assistenti AI diventano una porta d’ingresso a dati sensibili—dai documenti aziendali alle informazioni personali—approcci come SAFE-CACHE saranno fondamentali per garantire che ciò che l’AI ricorda non possa facilmente essere usato contro di noi.
Citazione: Afiffy, M., Fakhr, M.W. & Maghraby, F.A. Enhancing adversarial resilience in semantic caching for secure retrieval augmented generation systems. Sci Rep 16, 5936 (2026). https://doi.org/10.1038/s41598-026-36721-w
Parole chiave: cache semantica, retrieval-augmented generation, attacchi avversari, difesa basata su cluster, sicurezza LLM