Clear Sky Science · it
Migrazione adattiva dei servizi consapevole di latenza ed energia nel mobile edge computing
Perché è importante avvicinare le app a te
Ogni volta che giochi online in auto, ricevi indicazioni AR in streaming sul telefono o un sensore in una città intelligente invia dati, quei compiti digitali devono essere elaborati da qualche parte. Il Mobile Edge Computing (MEC) sposta quel lavoro dai data center remoti verso piccoli server posti vicino alle stazioni base cellulari, riducendo i ritardi e rendendo le app più reattive. Ma mantenere questi servizi vicini a utenti in movimento significa spesso “spostare” (migrare) l’applicazione in esecuzione tra server edge vicini. Troppa migrazione spreca energia e denaro; troppo poche crea ritardi e frustrazione. Questo studio esplora come trovare un equilibrio intelligente usando tecniche avanzate di machine learning.
Bilanciare velocità e consumo elettrico
La maggior parte delle ricerche precedenti sulla migrazione dei servizi MEC si è concentrata principalmente su un obiettivo: mantenere la latenza percepita dall’utente il più bassa possibile. Ciò tipicamente significa inseguire l’utente mentre si muove e spostare ripetutamente la sua app sul server più vicino. Tuttavia, ogni migrazione consuma energia di comunicazione aggiuntiva e introduce un proprio ritardo. Molti metodi precedenti hanno inoltre assunto ampia capacità dei server e condizioni stabili, ignorando la realtà per cui i server edge hanno risorse limitate, competono per molti utenti e sperimentano carichi e qualità wireless in rapido cambiamento. Gli autori sostengono che l’energia di migrazione debba essere trattata come un obiettivo centrale, sullo stesso piano della latenza, e che le politiche di migrazione debbano adattarsi online al movimento degli utenti, al carico dei server e alle fluttuazioni della rete.
Da un problema matematico a un agente che impara
I ricercatori costruiscono innanzitutto un modello matematico dettagliato di un sistema MEC con più stazioni base, server edge co‑localizzati e utenti mobili. Ogni utente delega compiti di calcolo a server vicini tramite collegamenti wireless. La latenza totale del servizio è scomposta in tre parti: il tempo per inviare il compito alla stazione base, il tempo di elaborazione sul server e il tempo impiegato se il servizio viene spostato tra server tramite backhaul cablato. L’energia di migrazione è modellata principalmente in funzione della quantità di dati da trasferire quando un servizio si muove. L’obiettivo complessivo è minimizzare sia la latenza sia l’energia di migrazione rispettando i vincoli sulla capacità di calcolo di ciascun server e le scadenze di ciascun servizio. Risolvere esattamente questo problema misto intero, non lineare, è computazionalmente intrattabile in tempo reale, quindi il team ricorre al deep reinforcement learning, in cui un agente impara buone decisioni interagendo con un ambiente simulato.
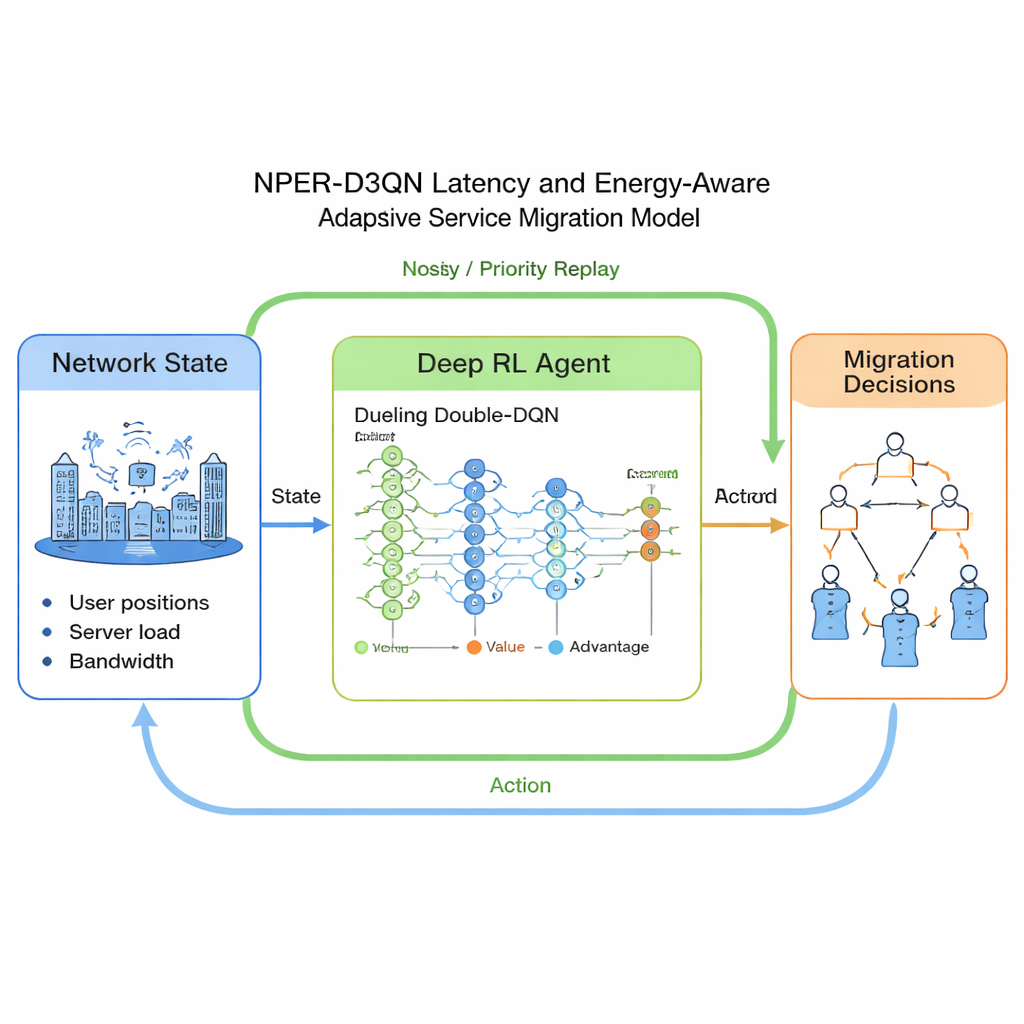
Come funziona il cervello adattivo della migrazione
Il metodo proposto, chiamato NPER‑D3QN, è una variante sofisticata delle Deep Q‑Networks (DQN). Lo “stato” in ingresso dell’agente riassume dove si trovano gli utenti, quanto sono lontani dalla stazione base che li serve, quanto sono carichi i singoli server edge, la capacità di calcolo disponibile, i tassi di dati wireless e quanto grandi e intensivi in termini di calcolo sono i singoli servizi. Le “azioni” sono le scelte su quale server edge dovrà ospitare il servizio di ciascun utente nel prossimo intervallo di tempo. La funzione di ricompensa favorisce bassa latenza rispetto alla scadenza di ciascun servizio penalizzando l’energia di migrazione, spingendo l’agente a bilanciare velocità e consumo energetico. Tecnicamente, il modello combina tre idee: una rete dueling che stima separatamente il valore dello stato e il vantaggio di ciascuna azione, una struttura di double Q‑learning che riduce stime troppo ottimistiche, e due aiuti all’esplorazione — reti rumorose e replay prioritizzato delle esperienze — che gli permettono di apprendere più velocemente e in modo più affidabile in condizioni complesse e variabili.
Mettere alla prova l’approccio
Per valutare l’efficacia di NPER‑D3QN, gli autori simulano una griglia in stile urbano con dozzine di stazioni base e fino a centinaia di utenti mobili che si muovono casualmente inviando compiti di dimensioni variabili. I server edge hanno potenza di calcolo limitata e possono ospitare solo un numero fisso di macchine virtuali, creando code e contese realistiche. Confrontano il loro metodo con sei baseline all’avanguardia, incluse versioni classiche di DQN, varianti double‑dueling migliorate e schemi che o inseguono sempre il server più vicino o si concentrano esclusivamente sulla minima latenza. In una gamma di scenari, NPER‑D3QN converge più rapidamente a strategie efficaci e raggiunge costantemente una latenza media di servizio inferiore, un consumo energetico legato alla migrazione più basso e meno migrazioni rifiutate quando i server sono pieni. In un test su larga scala con 720 utenti e 96 server, riduce la latenza fino a circa due terzi e l’energia di migrazione di oltre il 90% rispetto ad alcune alternative, mantenendo il tempo di calcolo per decisione entro limiti pratici.
Cosa significa per i servizi connessi del futuro
Per i non specialisti, la conclusione è che spingere semplicemente le app più vicino agli utenti non basta: serve anche un controllo intelligente di quando e dove i servizi in esecuzione vengono spostati. Questo lavoro dimostra che un controllore basato sull’apprendimento può “giocolare” gli obiettivi in competizione di reattività, risparmio energetico e capacità edge limitata senza regole scritte a mano. Se sistemi simili fossero dispiegati in reti reali, potrebbero aiutare gli operatori a offrire esperienze più fluide per applicazioni come guida autonoma, AR immersiva e IoT industriale, contenendo al contempo bollette elettriche e stress sull’infrastruttura. Gli autori osservano che lo studio è basato su simulazioni e omette alcuni dettagli del mondo reale come il consumo energetico totale dei server e il monitoraggio imperfetto, ma rappresenta un passo promettente verso un edge computing più verde e adattabile.
Citazione: Li, L., Lv, J., Wang, S. et al. Latency and energy-aware adaptive service migration in mobile edge computing. Sci Rep 16, 6178 (2026). https://doi.org/10.1038/s41598-026-36711-y
Parole chiave: mobile edge computing, service migration, deep reinforcement learning, ottimizzazione della latenza, efficienza energetica