Clear Sky Science · it
Autoencoder guidato dall'importanza delle feature per la riduzione della dimensionalità nei sistemi di rilevamento delle intrusioni
Perché difese informatiche più intelligenti contano
Ogni e-mail che invii, video che trasmetti e acquisto che fai viaggia su reti costantemente sotto attacco. I sistemi di rilevamento delle intrusioni (IDS) funzionano come allarmi per queste reti, individuando comportamenti sospetti prima che diventino violazioni. Ma i dati di rete moderni sono vasti e complessi, e setacciare tutti quei dettagli può rallentare i sistemi o far loro perdere attacchi sottili. Questo articolo esplora un nuovo modo di comprimere i dati in modo intelligente affinché gli strumenti IDS diventino sia più veloci sia più efficaci nel catturare anche cyberattacchi rari e difficili da individuare. 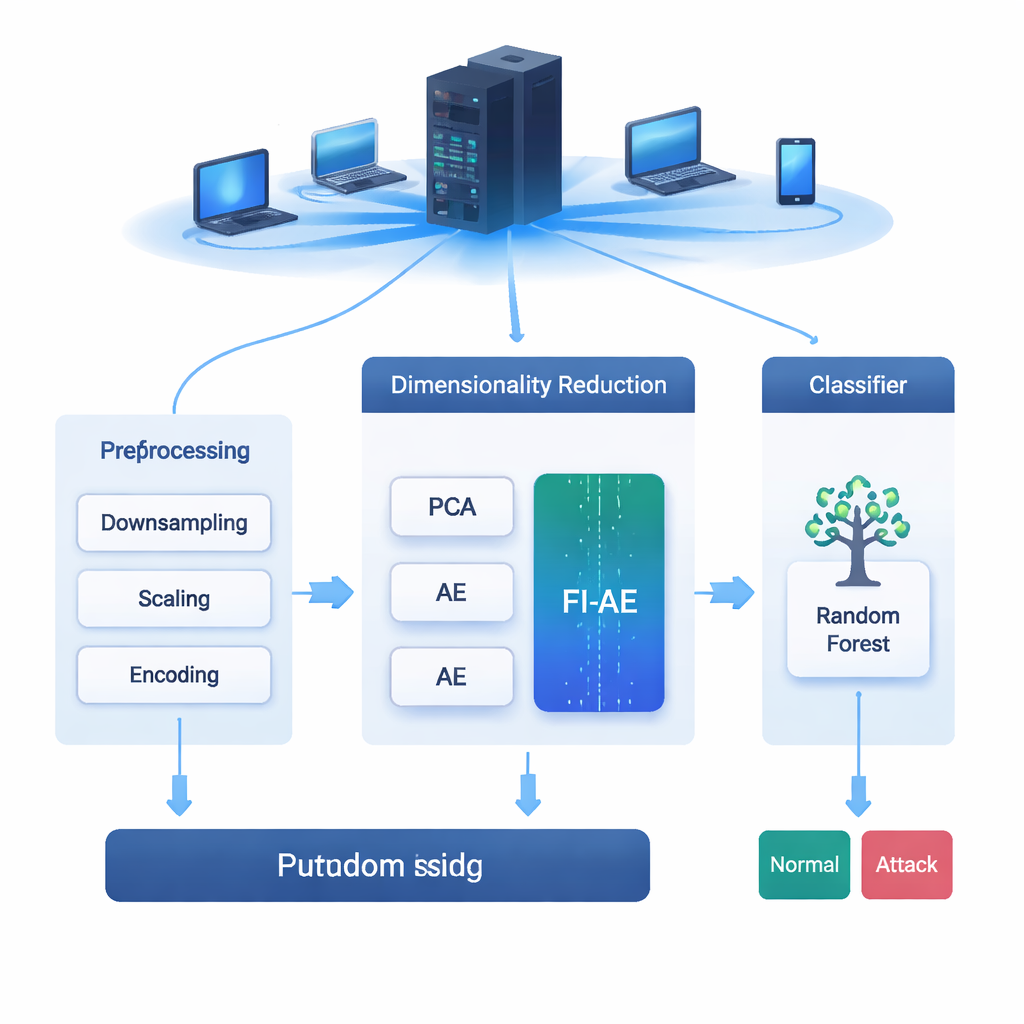
Il problema di avere troppi dati di rete
I record del traffico di rete contengono dalle decine alle centinaia di misure per ogni connessione — come durata, numero di byte e tassi di errore. I modelli IDS basati su machine learning si affidano a queste misure per decidere se il traffico è normale o dannoso. Tuttavia, usarle tutte può rallentare il rilevamento e a volte perfino peggiorare l’accuratezza, specialmente quando alcuni attacchi sono molto più rari di altri. Metodi comuni di riduzione della dimensionalità, come l’Analisi delle Componenti Principali (PCA) e gli autoencoder standard, comprimono i dati ma si concentrano principalmente nel ricostruire il traffico complessivo. Ciò significa che possono dare più attenzione alla maggioranza delle connessioni quotidiane e trascurare i pattern deboli e distintivi che segnalano tipi di attacco minoritari.
Un nuovo modo per classificare ciò che conta davvero
Gli autori introducono uno schema di classificazione delle feature chiamato importanza delle feature one-versus-all (OVA) per affrontare questo squilibrio. Invece di chiedersi «Quali misure sono più utili in generale?», OVA pone la domanda separatamente per ciascun tipo di attacco. Per ogni classe (ad esempio traffico normale, denial-of-service o tentativi di indovinare password), viene addestrato un modello random forest per distinguere quella classe da tutte le altre. I punteggi di importanza incorporati nel modello rivelano allora quali misure sono particolarmente utili per quella classe specifica. Ripetendo questo processo per ogni classe e poi prendendo, per ciascuna misura, il valore di importanza massimo che raggiunge per una qualsiasi classe, il metodo costruisce un singolo vettore di pesi che mette in evidenza le feature rilevanti per almeno un tipo di attacco — anche se quel tipo è raro nei dati.
Insegnare a un autoencoder a concentrarsi sui segnali chiave
Per sfruttare questi pesi, i ricercatori progettano un autoencoder basato sull’importanza delle feature (FI-AE). Come un autoencoder convenzionale, il FI-AE comprime l’input in una rappresentazione a bassa dimensionalità (il «collo di bottiglia») e poi ricostruisce i dati originali. La novità sta nell’obiettivo di addestramento: invece di trattare tutti gli errori di ricostruzione allo stesso modo, il modello usa un errore quadratico medio pesato che moltiplica l’errore di ciascuna feature per la sua importanza basata su OVA. In termini semplici, il FI-AE viene penalizzato di più per aver rappresentato male misure cruciali per distinguere gli attacchi, e meno per dettagli meno informativi. L’architettura è compatta, comprimendo i record di rete in appena 16 numeri e utilizzando tecniche standard come batch normalization, dropout e l’ottimizzatore Adam per mantenere stabile l’addestramento.
Mettere il metodo alla prova
Il gruppo valuta il FI-AE su tre dataset largamente usati per il rilevamento delle intrusioni: NSL-KDD, UNSW-NB15 e CIC-IDS2017, che insieme coprono milioni di connessioni e una vasta gamma di tipi di attacco. Prima dell’addestramento, i dati vengono ripuliti bilanciando distribuzioni di classe estremamente sbilanciate, scalando le feature numeriche e codificando le categorie in modo che la loro relazione con le etichette target sia preservata. Confrontano poi tre pipeline che terminano tutte con un classificatore random forest: una che usa la PCA, una che usa un autoencoder standard e una che usa FI-AE per la riduzione della dimensionalità. Su tutti e tre i dataset, FI-AE fornisce costantemente migliori valori di accuratezza e F1-score, con guadagni particolarmente evidenti sugli attacchi minoritari e rari, dove i metodi tradizionali tendono a faticare. 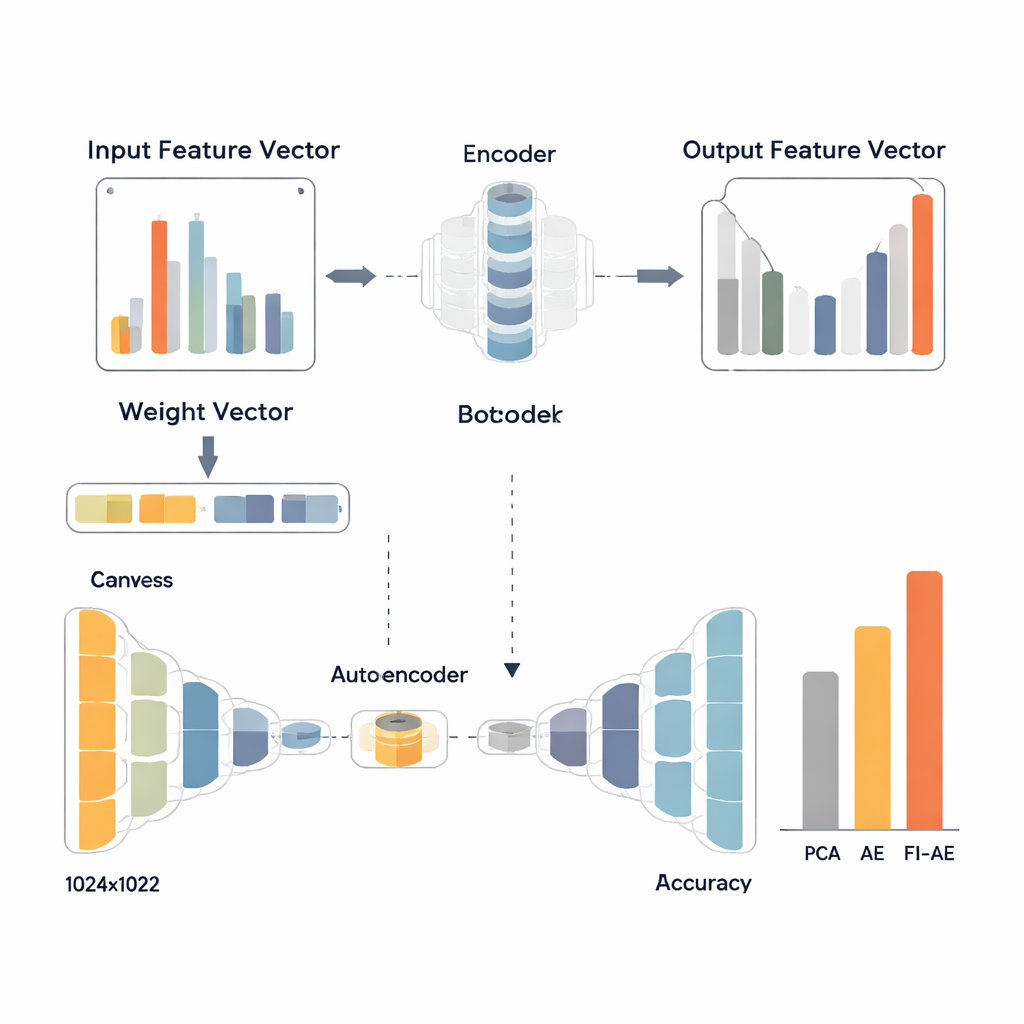
Cosa significa questo per la sicurezza quotidiana
Per i non specialisti, il messaggio chiave è che questo lavoro offre una lente più discriminante per il monitoraggio di rete. Piuttosto che limitarsi a comprimere i dati per renderli più piccoli, il FI-AE impara a preservare le misure che contano davvero per individuare diversi tipi di attacco, inclusi quelli rari che possono essere i più dannosi. Con appena 16 feature distillate, i sistemi di rilevamento delle intrusioni basati su questo approccio possono funzionare in modo più efficiente pur raggiungendo o superando l’accuratezza di rilevamento allo stato dell’arte. In pratica, ciò significa che gli strumenti di sicurezza possono analizzare più traffico, reagire più rapidamente e offrire una protezione migliore per i servizi digitali di cui le persone dipendono ogni giorno.
Citazione: Abdel-Rahman, M.A., Alluhaidan, A.S., El-Rahman, S.A. et al. Feature importance guided autoencoder for dimensionality reduction in intrusion detection systems. Sci Rep 16, 5013 (2026). https://doi.org/10.1038/s41598-026-36695-9
Parole chiave: rilevamento delle intrusioni, sicurezza di rete, riduzione della dimensionalità, autoencoder, importanza delle feature