Clear Sky Science · it
Rilevamento in tempo reale di fuoco e fumo mediante transformer visivi e apprendimento spazio-temporale
Perché gli avvisi più rapidi sugli incendi sono importanti
Gli incendi in abitazioni, impianti industriali e foreste possono diventare letali in pochi minuti. Oggi molti allarmi si affidano ancora a sensori di calore o fumo che reagiscono solo dopo che le fiamme sono ormai ben sviluppate. Questo articolo descrive un nuovo sistema di visione artificiale in grado di individuare segni di fuoco e fumo nei flussi video delle telecamere quasi istantaneamente, anche in condizioni difficili come scarsa illuminazione o fitta foschia. Combinando diverse tecniche avanzate di intelligenza artificiale in un unico modello, i ricercatori mirano a fornire ai vigili del fuoco, ai pianificatori urbani e alle agenzie ambientali un segnale di allerta molto più precoce—potenzialmente salvando vite, beni e ecosistemi.
La sfida crescente del riconoscimento delle fiamme
Le città moderne e le foreste sono sempre più sorvegliate da telecamere, ma insegnare ai computer a riconoscere in modo affidabile fuoco e fumo in immagini e video è complesso. Gli approcci tradizionali utilizzano reti neurali che funzionano bene su immagini statiche o brevi clip, ma spesso faticano nelle scene reali e disordinate. Un singolo scatto può mostrare qualcosa che assomiglia al fumo ma che è in realtà nebbia o scarico. I sistemi orientati al video possono tracciare come le forme si muovono nel tempo, ma tendono a essere lenti e pesanti in termini di risorse. Di conseguenza, i modelli precedenti spesso generano falsi allarmi o non rilevano segnali sottili e rapidamente mutevoli—soprattutto in condizioni di scarsa illuminazione, fumo denso o sfondi complessi.
Un "osservatore" ibrido per immagini e video
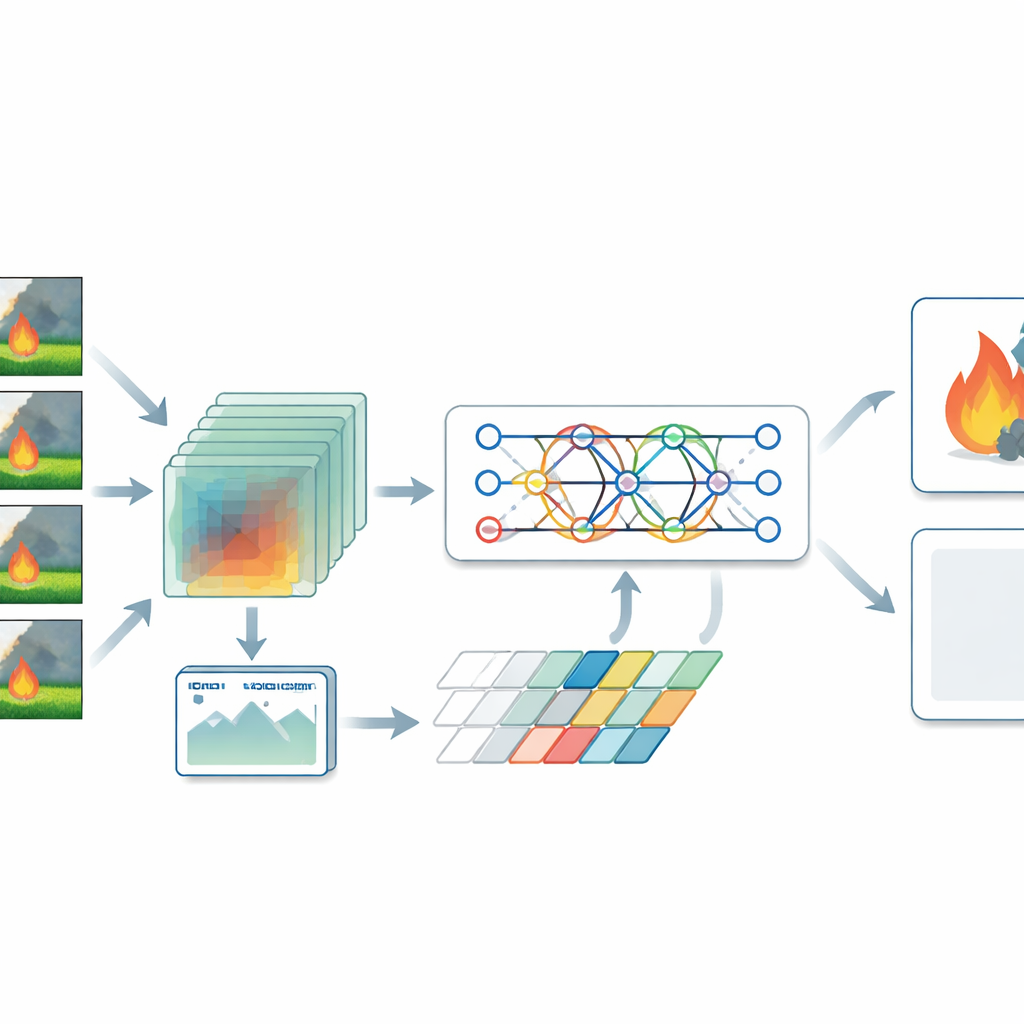
Gli autori propongono un modello ibrido che tratta il rilevamento degli incendi sia come problema spaziale che temporale. Per le immagini statiche usano un tipo di rete neurale chiamata vision transformer, che considera l’immagine come un mosaico di regioni e apprende come aree distanti siano correlate. Questo aiuta a cogliere pattern ampi, come filamenti di fumo che si estendono su una valle o focolai sparsi in una foresta. Per il video, il sistema si basa su una rete convoluzionale tridimensionale che elabora pile di fotogrammi contemporaneamente, catturando come fumo e fuoco evolvono nel tempo. Un encoder transformer esamina poi questi pattern temporali e concentra l’attenzione sui momenti e sulle regioni più probabili indicatrici di pericolo, invece di dare lo stesso peso a ogni fotogramma.
Combinare indizi e bilanciare i dati
Un passaggio chiave del sistema è uno strato di fusione che integra i dettagli delle immagini con i pattern di movimento tratti dal video. Combinando queste viste complementari, il modello distingue meglio i veri incendi da somiglianze innocue come il controluce del tramonto, la nebbia o le nuvole. I ricercatori hanno inoltre rilevato che molti dataset pubblici contengono molti più esempi di fuoco che di non-fuoco, il che può portare il modello a sovra-segnalare le fiamme. Per compensare ciò hanno generato una vasta gamma di scene non incendiarie realistiche tramite un’attenta augmentation dei dati—modificando luminosità, ritagliando e ribaltando le immagini e simulando situazioni come mattine nebbiose o interni poco illuminati. Hanno poi addestrato il modello con una funzione di perdita che bilancia esplicitamente gli errori su casi con e senza fuoco, migliorando l’affidabilità nell’uso quotidiano.
Mettere il sistema alla prova
Per valutare l’efficacia dell’approccio, gli autori lo hanno testato su due dataset ampiamente usati: uno di quasi mille immagini statiche dal NASA Space Apps Challenge e un altro di video relativi a incendi da Kaggle. Dopo il preprocessing e il bilanciamento, hanno addestrato e valutato il modello ibrido affiancandolo a baseline note come ResNet, VGG, LSTM, reti convoluzionali 3D pure e vari accoppiamenti ibridi di questi metodi più datati. Il nuovo sistema ha raggiunto circa il 99,2% di accuratezza sulle immagini NASA e il 98,3% sul dataset video, superando nettamente i modelli tradizionali, che tipicamente si attestavano tra la metà degli anni ’80 e la metà degli anni ’90. Ha inoltre funzionato abbastanza velocemente—decine di millisecondi per fotogramma—e con una dimensione di modello moderata, rendendolo adatto alla distribuzione su dispositivi edge come GPU di dimensioni ridotte e schede embedded.
Cosa significa questo per la sicurezza quotidiana
In termini pratici, questa ricerca dimostra che un’IA progettata con cura può monitorare i flussi video in tempo reale e rispondere in modo affidabile a una domanda semplice ma vitale: «C’è fuoco o fumo pericoloso qui adesso?» Integrando contesto visivo ampio, movimento nel tempo e attenzione mirata ai dettagli più rivelatori, il modello ibrido riduce drasticamente sia gli incendi non rilevati sia i falsi allarmi. Con ulteriori ottimizzazioni e l’esposizione a scene più varie—come città dense, spazi sotterranei e condizioni meteorologiche estreme—potrebbe diventare una spina dorsale pratica per sistemi di allarme più intelligenti, reti di monitoraggio degli incendi boschivi e strumenti di sicurezza industriale che reagiscono più rapidamente e con maggiore precisione rispetto a molte soluzioni odierne.
Citazione: Lilhore, U.K., Sharma, Y.K., Venkatachari, K. et al. Real time fire and smoke detection using vision transformers and spatiotemporal learning. Sci Rep 16, 8928 (2026). https://doi.org/10.1038/s41598-026-36687-9
Parole chiave: rilevamento incendi, rilevamento fumo, visione artificiale, modelli transformer, monitoraggio in tempo reale