Clear Sky Science · it
Apprendimento auto-supervisionato consapevole della semantica mediante regressione progressiva di sotto-azioni per la valutazione della qualità dell’azione
Osservare la performance attraverso una nuova lente
Quando guardiamo tuffatori olimpici o altri atleti d’élite, percepiamo istintivamente chi ha fatto meglio, ma trasformare quell’intuizione in numeri oggettivi è difficile. I sistemi video automatici odierni possono assegnare un “punteggio” complessivo a un’azione, ma raramente spiegano perché un tuffo è buono o cattivo, o quale parte necessita di miglioramento. Questo articolo presenta un nuovo modo per i computer di analizzare azioni complesse nei video, scomporle in parti comprensibili e valutare ciascuna parte separatamente — offrendo un feedback più vicino a quello che darebbe un allenatore umano.

Spezzare un movimento complesso in pezzi gestibili
Molti strumenti attuali per la valutazione della qualità trattano un intero tuffo o movimento come un unico blocco, producendo un solo punteggio complessivo. Questo nasconde dettagli cruciali: un tuffatore può effettuare una partenza perfetta e poi entrare in acqua male, e un singolo numero non può rivelarlo. Gli autori affrontano il problema insegnando al computer a dividere ogni video in fasi significative, o sotto-azioni, come avvio, distacco, volo e entrata. Importante, questa suddivisione è effettuata automaticamente, senza marcature umane su dove finisca una fase e inizi la successiva. Un metodo di clustering non supervisionato raggruppa i fotogrammi vicini che “si comportano” in modo simile nel tempo, fornendo al sistema una storyboard approssimativa ma affidabile della performance.
Lasciare che il sistema impari da sé cosa conta
Una volta che il video è diviso in fasi, il sistema deve capire come appare ciascuna fase quando è eseguita bene o male. Invece di affidarsi a etichette dense e fatte a mano, gli autori utilizzano l’apprendimento auto-supervisionato: al modello vengono mostrate molte versioni della stessa sotto-azione in cui porzioni di fotogrammi sono deliberatamente rimosse o “mascherate”. Il sistema deve comunque produrre descrizioni interne simili sia per i clip completi sia per quelli parzialmente mancanti. Imparando a ignorare queste lacune artificiali, il modello diventa robusto a problemi del mondo reale come brevi occlusioni, fotogrammi persi o confini di fase leggermente imprecisi, e impara a concentrarsi sui pattern essenziali di movimento e postura che definiscono la qualità.
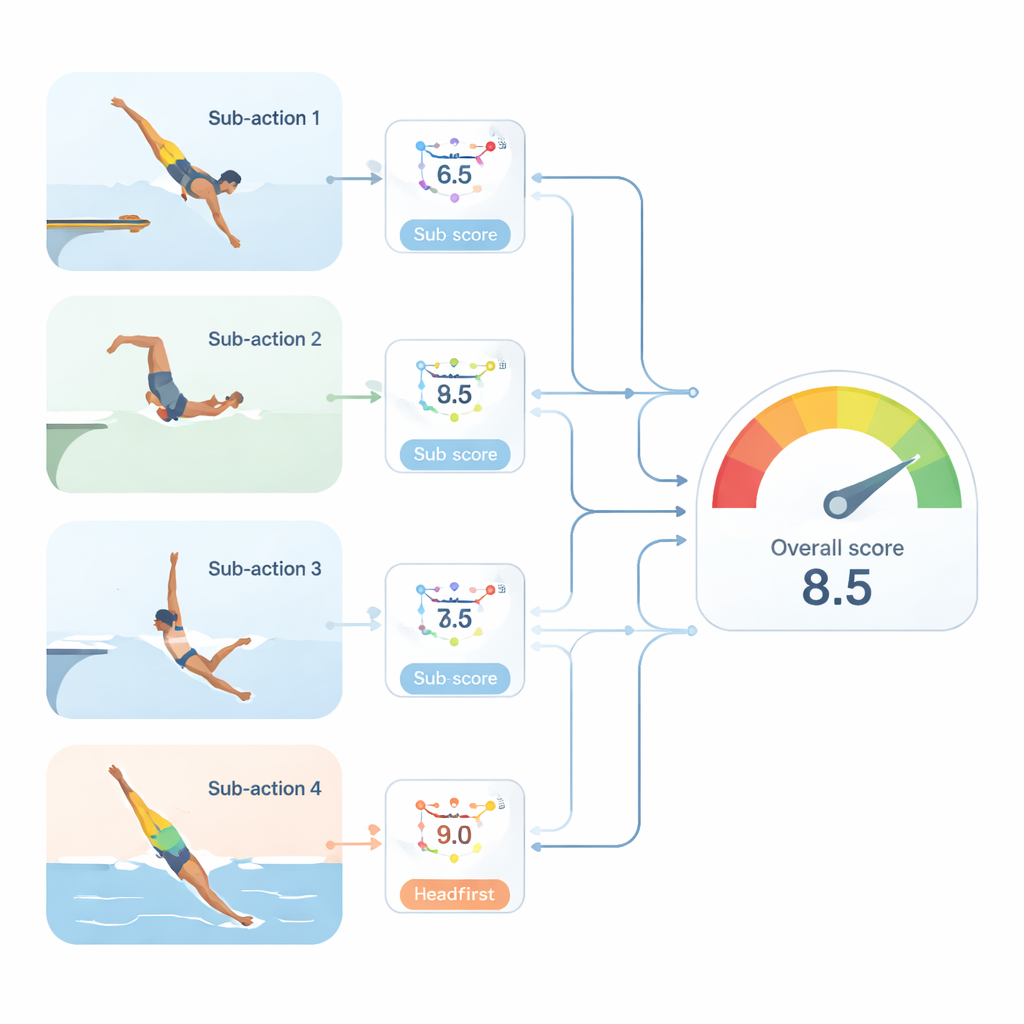
Da un punteggio globale a molti sotto-punteggi utili
I dataset reali di solito contengono solo un singolo punteggio complessivo per ogni tuffo, non valutazioni separate per ciascuna fase. Per superare questo limite, gli autori introducono una strategia progressiva di “pseudo-sotto-punteggio”. Prima, fondono il punteggio globale con le caratteristiche recentemente apprese per ogni sotto-azione e addestrano piccole reti a indovinare un punteggio provvisorio per ciascuna fase. Poi affinano queste stime permettendo al flusso di informazione di propagarsi lungo la sequenza: le caratteristiche di ogni fase vengono aggiornate usando i punteggi delle fasi precedenti, catturando come un piccolo errore al distacco possa riverberarsi durante il volo e l’entrata. In una variante, ogni fase ha accesso a tutti i punteggi delle fasi precedenti, modellando cause ed effetti a lungo raggio lungo tutta l’azione. Infine, una rete di regressione compatta combina i punteggi di fase raffinati in una previsione complessiva, ora senza bisogno di vedere il punteggio reale in ingresso.
Test su competizioni di tuffi reali
I ricercatori hanno valutato il loro framework su due esigenti dataset di tuffi registrati in importanti competizioni internazionali. Queste raccolte forniscono punteggi complessivi da giudici umani e, in alcuni casi, tempistiche approssimative delle fasi, ma non etichette di qualità a livello di fase. Il nuovo metodo ha raggiunto una correlazione di ordine all’avanguardia, cioè l’ordinamento degli atleti è molto vicino a quello dei giudici esperti, riducendo al contempo gli errori numerici nelle previsioni dei punteggi. Attenti test di “ablation” hanno mostrato che entrambe le idee principali — il raffinamento delle feature auto-supervisionato e la modellazione progressiva dei pseudo-sotto-punteggi — contribuiscono con miglioramenti sostanziali. Notevolmente, l’uso di confini di fase automatici ha performato quasi quanto l’uso di annotazioni umane meticolose, indicando che il sistema è resistente a una segmentazione imperfetta.
Trasformare i numeri in consigli di coaching illuminanti
Oltre all’accuratezza, questo approccio rende la valutazione automatica più interpretabile. Assegnando un punteggio separato a ciascuna fase di un tuffo, il sistema può evidenziare, per esempio, che due tuffatori hanno distacchi e fasi di volo simili ma differiscono nettamente all’entrata, dove uno crea uno schizzo maggiore. L’analisi di molti campioni conferma che questi punteggi di fase seguono le stesse priorità dei giudici umani, con la fase di entrata spesso più influente. In termini pratici, il metodo può indicare ad atleti e allenatori la parte esatta della performance che va migliorata, pur lavorando su dati di addestramento relativamente semplici. Pur essendo dimostrato sui tuffi, il concetto è sufficientemente flessibile da estendersi ad altri compiti multi-fase — dalle procedure chirurgiche agli esercizi di riabilitazione — dove capire come ogni segmento contribuisca alla qualità complessiva è fondamentale.
Citazione: Mazruei, M., Fazl-Ersi, E., Vahedian, A. et al. Semantic-aware self-supervised learning using progressive sub-action regression for action quality assessment. Sci Rep 16, 6670 (2026). https://doi.org/10.1038/s41598-026-36668-y
Parole chiave: valutazione della qualità dell’azione, analisi video sportiva, apprendimento auto-supervisionato, valutazione del movimento umano, deep learning per l’allenamento