Clear Sky Science · it
Una pipeline ad alte prestazioni, senza addestramento, per la caratterizzazione robusta dei segnali telegrafici casuali tramite denoising adattivo basato su wavelet e metodi bayesiani di digitalizzazione
Perché contano i piccoli sfarfallii del segnale
All’interno dell’elettronica moderna e persino nelle cellule viventi, eventi importanti possono apparire come piccoli clic nel tempo: un segnale salta improvvisamente verso l’alto, rimane lì per un po’, poi ricade. Questi salti, noti come segnali telegrafici casuali, possono rivelare quando un singolo difetto in un circuito intrappola un elettrone o quando una macchina molecolare in biologia cambia stato. Ma nelle misure reali questi salti sono sepolti sotto il fruscio e il ronzio di molte altre sorgenti di rumore. Questo articolo presenta una pipeline d’analisi veloce, senza necessità di addestramento, che può pulire automaticamente questi dati, recuperare i modelli di salto nascosti e farlo in modo sufficientemente affidabile per tecnologie future come i dispositivi quantistici e i sensori di nuova generazione.
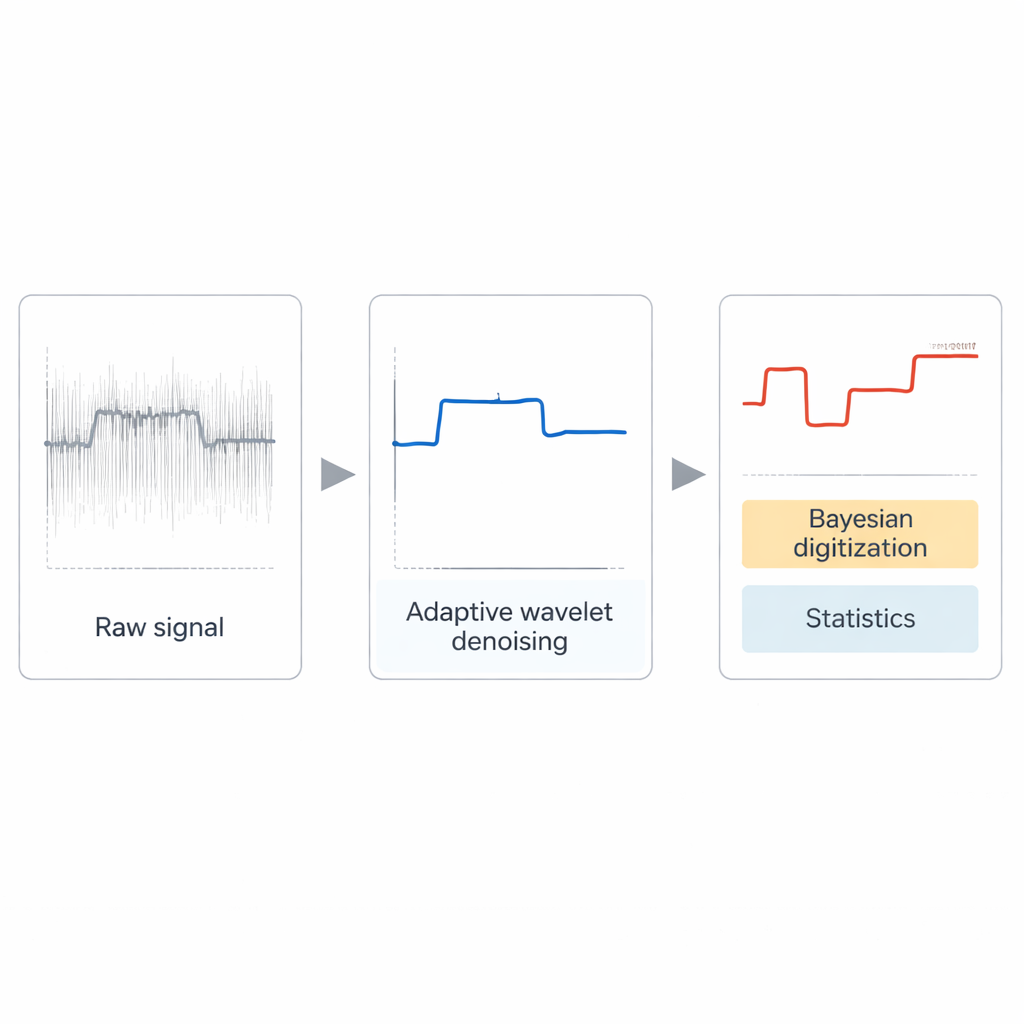
Vedere i salti in un mare di rumore
Un segnale telegrafico casuale è come una luce che si alterna casualmente tra due o più livelli di luminosità. Da questi schemi di alternanza, i ricercatori possono dedurre quanto a lungo un difetto o un sito molecolare tende a rimanere “acceso” o “spento” e quanto è intensa la sua influenza. Queste informazioni, a loro volta, parlano direttamente dell’affidabilità dei transistor su scala nanometrica, dei sensori d’immagine e dei bit quantistici. La sfida è che i segnali reali raramente sono puliti: sono mescolati con rumore “bianco”, che si distribuisce uniformemente su tutte le frequenze, e rumore “rosa” o 1/f, che deriva lentamente e può nascondere completamente i gradini sottostanti. Man mano che i dispositivi si riducono e li monitoriamo a risoluzioni temporali sempre più fini, queste sorgenti di rumore diventano più rilevanti, rendendo più difficile distinguere eventi fisici genuini dal disordine di fondo.
Una pipeline più intelligente per pulire e contare
Gli autori propongono una pipeline modulare in tre fasi che funziona senza alcun addestramento di machine learning. Primo, uno strumento avanzato basato su wavelet, la trasformata complessa dual-tree, denoising adattivamente il segnale grezzo. Le sue impostazioni sono scelte automaticamente a partire da proprietà semplici dei dati, così gli utenti non devono tarare manualmente i parametri. Questa fase è particolarmente efficace nell’eliminare il rumore bianco veloce preservando i bordi netti dei salti reali. Poi, il segnale ripulito viene analizzato statisticamente per trovare i livelli di ampiezza più comuni, come identificare i pioli più frequentemente calpestati di una scala. Infine, un passaggio bayesiano leggero traduce il segnale smussato in un registro digitale di quale livello è attivo in ogni momento e calcola quanto a lungo ciascuno stato tende a durare.
Mettere il metodo alla prova
Per valutare l’efficacia della pipeline, il team ha costruito grandi set di dati sintetici nei quali i veri schemi di salto sono noti a priori. Hanno generato migliaia di segnali telegrafici casuali con uno, due o tre “trappole” indipendenti, quindi hanno miscelato quantità controllate di rumore bianco o rosa. Questo ha permesso di verificare quanto accuratamente diversi metodi recuperano grandezze chiave: il numero di trappole attive, l’entità di ciascun salto, la frazione di tempo in cui ogni stato è attivo e quanto a lungo il segnale permane in ciascuno stato prima di cambiare. Hanno confrontato quattro workflow completi: filtraggio con media mobile semplice, filtraggio nel dominio della frequenza, un potente denoiser basato su rete neurale e la nuova pipeline wavelet più bayesiana. Mentre la rete neurale ha raggiunto il punteggio più alto su una misura basilare segnale-rumore, il nuovo metodo ha identificato in modo più coerente il numero corretto di trappole, stimato con maggiore accuratezza le ampiezze dei salti e si è mantenuto robusto anche con livelli di rumore molto elevati o quando il rumore rosa era dominante.
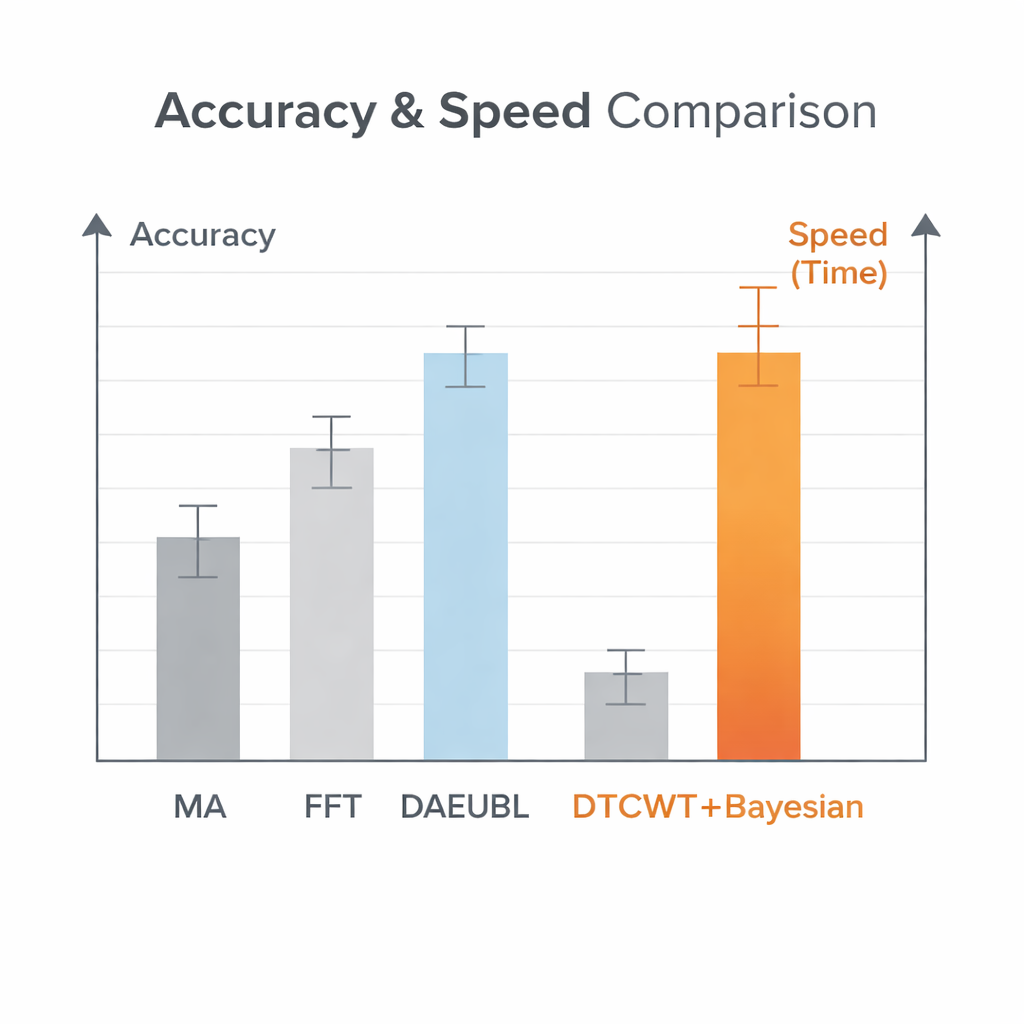
Abbastanza veloce per dispositivi in tempo reale
Oltre all’accuratezza, velocità e requisiti di memoria sono critici quando si trattano registrazioni molto lunghe. Una singola misura di cento secondi a risoluzione nanosecondo può contenere miliardi di punti dati, troppo grandi perché molti modelli di rete neurale li elaborino in tempi ragionevoli. La pipeline proposta elabora segnali lunghi fino a circa 83 volte più velocemente rispetto alla baseline neurale, al prezzo di usare fino a tre volte più memoria—un compromesso comunque pratico sull’hardware moderno. Gli autori applicano inoltre il loro metodo a dati reali provenienti da dispositivi a nanotubi di carbonio operati a basse temperature. Sebbene in questi esperimenti non esista una “verità a terra”, la pipeline produce schemi di gradini chiari e interpretabili e statistiche di stato ragionevoli senza alcun riaddestramento o taratura specifica del dispositivo, offrendo anche manopole per gli esperti che vogliano esplorare interpretazioni alternative.
Cosa implica per il futuro
In termini semplici, questo lavoro fornisce un affidabile “rilevatore di clic” per misure molto rumorose e ad alta velocità. Dimostra che con strumenti progettati con cura e senza addestramento, i ricercatori possono pulire automaticamente segnali telegrafici casuali complessi, contare correttamente quanti siti di commutazione indipendenti sono presenti e misurare con quale intensità e frequenza agiscono. Poiché il metodo è veloce, trasparente e facile da adattare, può costituire la base per banchi di prova automatizzati per la produzione di semiconduttori, generatori quantistici di numeri casuali e studi di segnali fluttuanti in chimica e biologia. Piuttosto che essere un trucco una tantum, la pipeline funge da fondamento su cui costruire moduli più specializzati o più intelligenti per dispositivi di complessità crescente.
Citazione: Bai, T., Kapoor, A. & Kim, N.Y. A high-performance training-free pipeline for robust random telegraph signal characterization via adaptive wavelet-based denoising and Bayesian digitization methods. Sci Rep 16, 7455 (2026). https://doi.org/10.1038/s41598-026-36656-2
Parole chiave: segnale telegrafico casuale, denoising del segnale, analisi bayesiana, rumore nei semiconduttori, serie temporali