Clear Sky Science · it
Riconoscimento intelligente dei comportamenti degli studenti per ambienti di apprendimento smart
Perché le aule più intelligenti devono capire cosa fanno gli studenti
In molte aule gli insegnanti devono indovinare chi sta seguendo la lezione, chi è perso e chi è discretamente distratto. Questo articolo esplora come l’intelligenza artificiale possa riconoscere automaticamente cosa fanno gli studenti—come leggere, scrivere o alzare la mano—a partire da foto ordinarie in classe. Trasformando immagini grezze in misure affidabili dell’attività in aula, il sistema mira a fornire agli insegnanti un feedback in tempo reale sull’impegno degli studenti senza ricorrere a osservazioni che richiedono tempo o a monitoraggi invasivi.
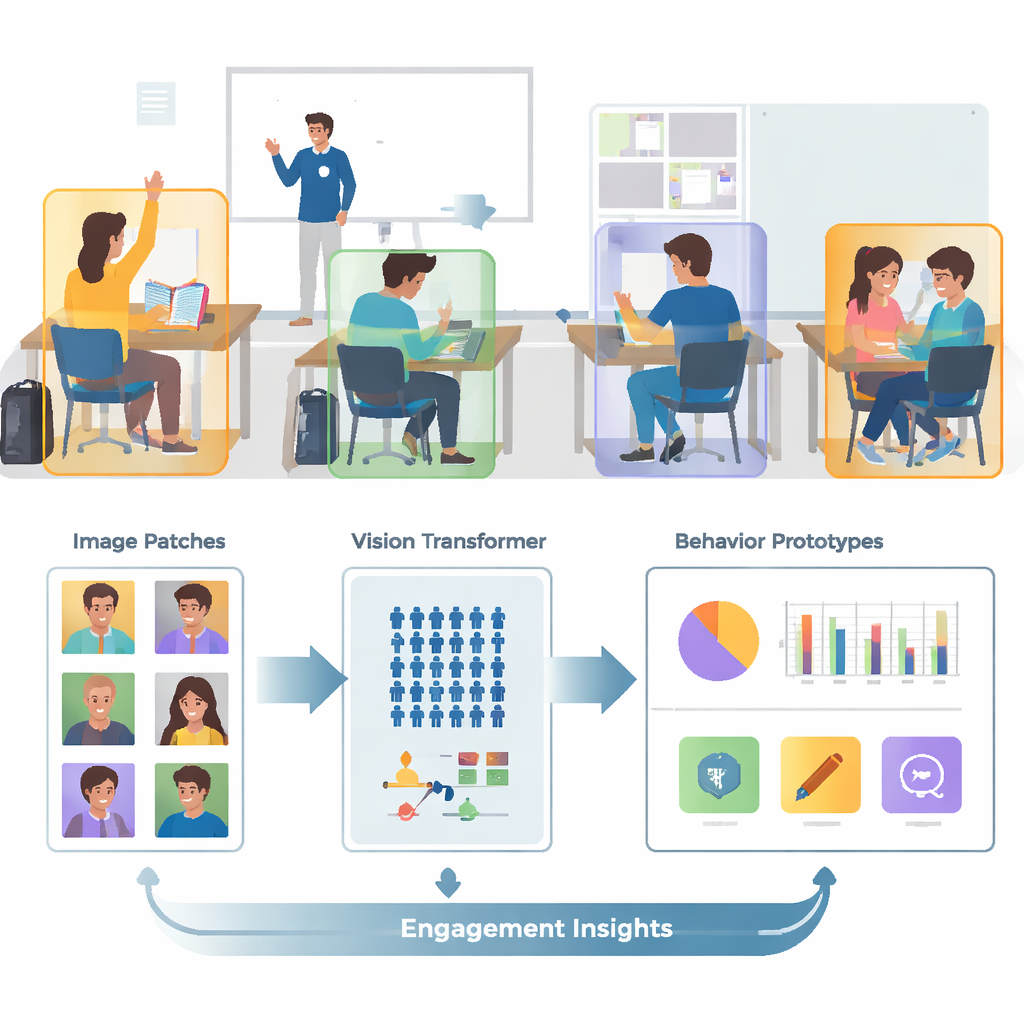
Da foto disordinate a istantanee focalizzate
Le aule reali sono affollate, caotiche e visivamente confuse. Una singola immagine può contenere decine di studenti, corpi sovrapposti e dettagli di sfondo distraenti come pareti, schermi e poster. Gli autori si basano su una raccolta pubblica di immagini chiamata SCB‑05, che contiene migliaia di foto d’aula etichettate con comportamenti specifici—come alzare la mano, leggere, scrivere, stare in piedi, parlare o interagire alla lavagna. Invece di fornire all’algoritmo l’intera scena, il sistema usa prima i file di annotazione per ritagliare solo le regioni intorno a ciascun studente o insegnante. Questo passaggio di pre-elaborazione elimina gran parte dell’ingombro visivo, così il modello può concentrarsi su postura, posizione delle mani e altri indizi che distinguono un comportamento dall’altro.
Come l’AI impara nuovi comportamenti da pochissimi esempi
Un ostacolo importante è che alcuni comportamenti in aula sono comuni nei dati (come leggere), mentre altri sono rari (come brevi interazioni sul palco). Raccogliere immagini etichettate a sufficienza per ogni comportamento possibile è costoso e solleva problemi di privacy. Per ovviare a questo problema, gli autori utilizzano una strategia chiamata “few-shot learning”, in cui il modello viene addestrato a riconoscere nuove classi a partire da una manciata di esempi. Organizzano l’addestramento come molti piccoli compiti, ciascuno contenente poche azioni e poche immagini campione per azione. Per ogni compito, il sistema crea un semplice “prototipo” per ogni comportamento mediando la sua rappresentazione interna di quegli esempi. Le nuove immagini vengono quindi classificate confrontando a quale prototipo sono più vicine, permettendo al modello di adattarsi rapidamente anche quando i dati sono scarsi.
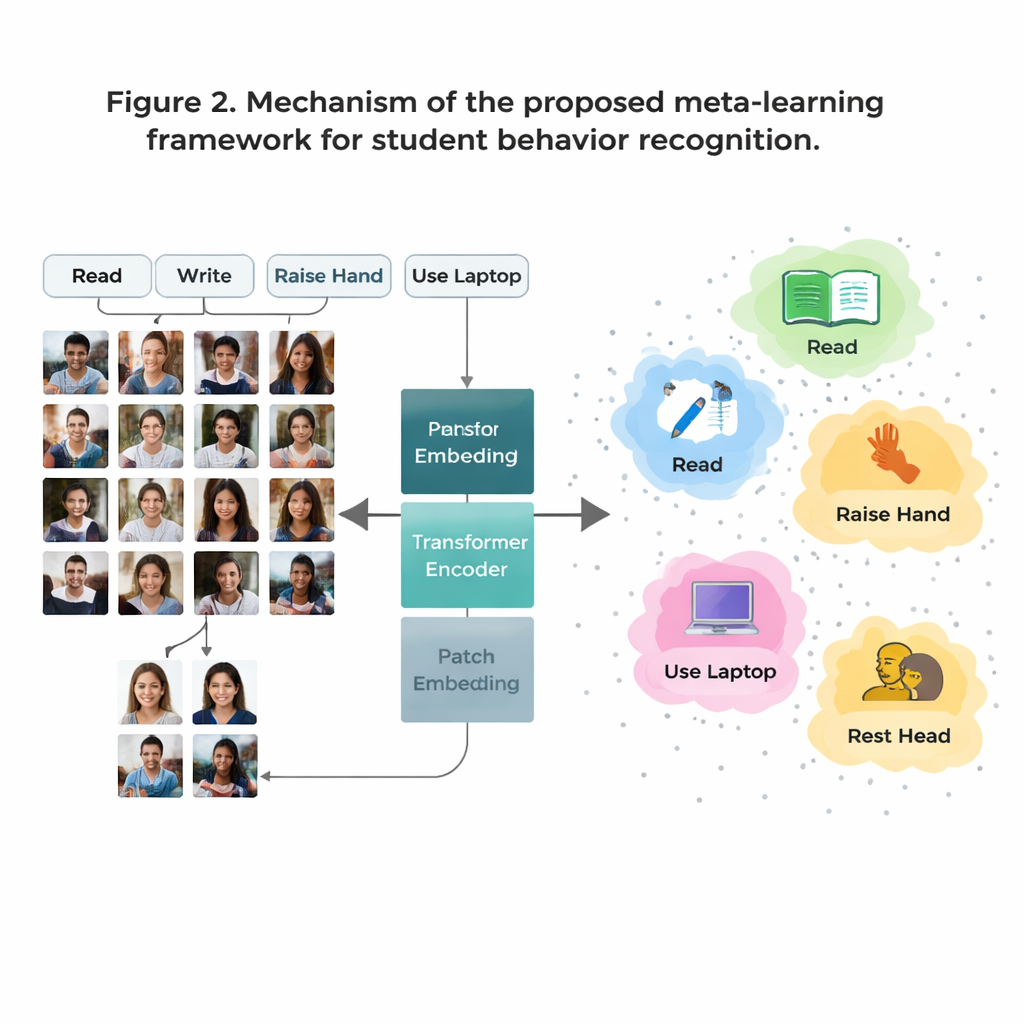
Vedere l’intera aula, non solo i dettagli locali
I sistemi di visione tradizionali basati su reti neurali convoluzionali tendono a concentrarsi su piccoli pattern locali, come bordi o texture. Questo può essere limitante quando due comportamenti, per esempio leggere e scrivere, appaiono molto simili da vicino. Questo lavoro sostituisce quelle reti con un Vision Transformer, un modello che suddivide ogni immagine in patch e impara come tutte le patch si relazionano tra loro. Questa visione globale aiuta il sistema a cogliere sottili differenze di postura e indizi a lunga distanza—come la relazione tra una mano sollevata e l’insegnante davanti alla classe. Il team affina ulteriormente il modello addestrandolo a raggruppare insieme le immagini dello stesso comportamento mentre separa casi simili ma diversi, con particolare attenzione ai casi «difficili» e fuorvianti. Ciò rende la mappa interna dei comportamenti più pulita e più facile da separare.
Quanto bene funziona e perché è importante
Sul benchmark SCB‑05 il metodo proposto raggiunge circa il 91% di accuratezza complessiva e punteggi solidi su misure più esigenti che tengono conto dei dati sbilanciati. I comportamenti comuni come la lettura e l’alzare la mano vengono riconosciuti particolarmente bene, mentre quelli più rari come la scrittura alla lavagna restano più impegnativi ma ottengono comunque prestazioni migliori rispetto ai sistemi precedenti. Ispezioni visive dei cluster interni del modello mostrano che i diversi comportamenti formano gruppi compatti e ben separati, indicando che l’AI ha appreso «firme» distinte delle azioni in aula. Quando testato su un diverso dataset di aule con angolazioni delle camere e layout nuovi, le prestazioni sono calate di poco, suggerendo che la rappresentazione appresa non è legata a una singola stanza o scuola.
Cosa significa per l’insegnamento e l’apprendimento
In termini pratici, lo studio dimostra che i computer possono individuare in modo affidabile molti comportamenti chiave degli studenti da immagini statiche, anche quando hanno visto solo pochi esempi di ciascuno. Piuttosto che sostituire gli insegnanti, questi sistemi potrebbero riassumere discretamente chi è coinvolto, chi chiede spesso aiuto o quali attività tendono a far perdere attenzione—tutto senza tracciare l’identità degli studenti. Con ulteriori interventi su privacy, equità e analisi video nel tempo, questo tipo di AI sensibile al comportamento potrebbe diventare un alleato potente per gli educatori che progettano ambienti di apprendimento più reattivi e inclusivi.
Citazione: Abozeid, A., Alrashdi, I. & Al-Makhlasawy, R.M. Intelligent recognition of students’ behavior for smart learning environments. Sci Rep 16, 5674 (2026). https://doi.org/10.1038/s41598-026-36633-9
Parole chiave: aule intelligenti, comportamento degli studenti, computer vision, few-shot learning, vision transformer