Clear Sky Science · it
Super-risoluzione a scala continua per immagini di telerilevamento cross-domain tramite meta-weight learning
Visioni più nitide dallo spazio
Le immagini satellitari guidano tutto, dalla pianificazione urbana alla gestione delle emergenze, ma molte foto risultano più sfocate di quanto vorremmo a causa dei limiti dell'hardware delle camere e della trasmissione dei dati. Questo articolo presenta un nuovo metodo per trasformare foto satellitari sfocate in immagini più nitide a qualsiasi livello di ingrandimento scelto, usando una strategia di apprendimento in grado di adattarsi al carattere particolare delle immagini aeree senza dover essere riaddestrata per ogni singola situazione.
Perché immagini satellitari più nitide sono importanti
Immagini di telerilevamento ad alta risoluzione sono cruciali per individuare piccoli oggetti, monitorare i cambiamenti sul terreno e mappare l'uso del suolo in dettaglio. Tuttavia i satelliti reali devono bilanciare risoluzione con costo, dimensione dei sensori e larghezza di banda, quindi molte immagini arrivano a una qualità inferiore rispetto a quella desiderata dagli analisti. Le tecniche tradizionali di “super-risoluzione” possono migliorare la nitidezza, ma sono solitamente addestrate per un ingrandimento fisso, come esattamente due o quattro volte. Ciò impone agli operatori di usare modelli separati per ogni livello di zoom, rendendo il workflow inefficiente e poco flessibile quando si gestiscono molti satelliti e compiti vari.
Oltre lo zoom unico per tutti
Ricerche recenti hanno sviluppato la super-risoluzione “a scala continua”, che tratta l'immagine come un segnale liscio e può generare output nitidi a qualsiasi fattore di ingrandimento con un singolo modello. La maggior parte di questi metodi è stata costruita e testata su foto ordinarie, non su dati satellitari. In genere decidono come mescolare le informazioni dei pixel vicini usando regole geometriche fisse—praticamente pesando i vicini in base alla distanza. Questo funziona abbastanza bene per scene naturali come volti o paesaggi, ma le immagini satellitari contengono edifici densi, texture ripetitive e bordi netti che non seguono gli stessi schemi. Quando modelli addestrati su foto naturali vengono applicati a viste satellitari, le loro assunzioni falliscono e dettagli come tetti, strade e veicoli non vengono ricostruiti fedelmente.
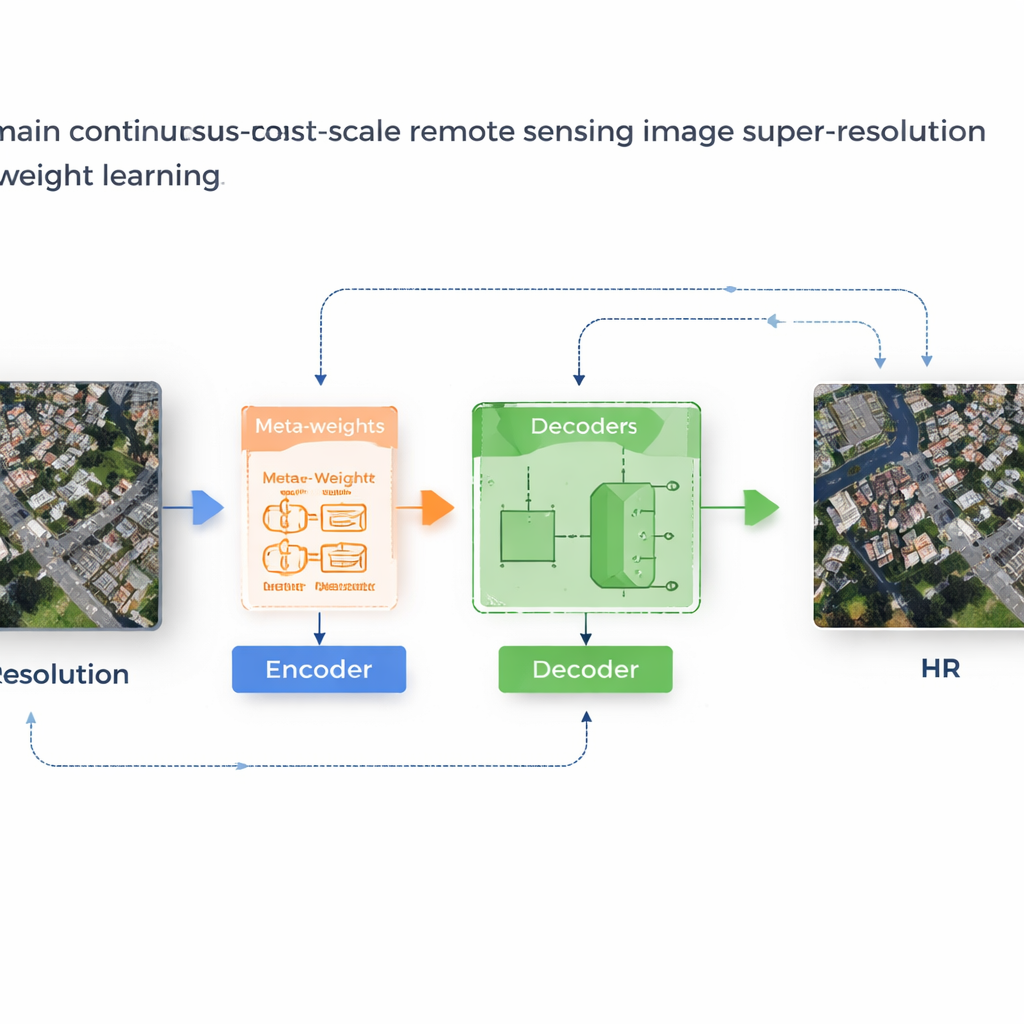
Un sistema di apprendimento che adatta le proprie regole
Gli autori propongono un framework chiamato MLIN (Meta-Learning-based Implicit Neural Network) per affrontare questo problema cross-domain. Invece di definire a mano come combinare le caratteristiche dei pixel vicini, MLIN apprende queste regole di combinazione dai dati. Mantiene un potente encoder di immagini originariamente addestrato su foto naturali completamente congelato, così da continuare a estrarre pattern visivi ricchi senza essere distorto dai più piccoli dataset satellitari. Sopra questo, MLIN aggiunge un nuovo “decoder implicito” dotato di un modulo di meta-learning. Per ogni punto dell'immagine ad alta risoluzione che il modello vuole ricostruire, questo modulo osserva le caratteristiche circostanti e le loro posizioni precise e quindi prevede un insieme di pesi soft che indicano al decoder quanto utilizzare ogni vicino. In altre parole, il sistema non presume più che conti solo la distanza; lascia che il contenuto locale—come texture di tetti, campi o acqua—plasmi la ricostruzione.
Da blocchi sfocati a strutture nitide
Dal punto di vista tecnico, il metodo funziona campionando un piccolo intorno 2×2 di feature nascoste attorno a ogni posizione target nell'immagine di output. Una meta-rete combina poi informazioni su queste feature, le loro coordinate relative e il fattore di zoom richiesto per scegliere pesi che sommano a uno. Il decoder usa questi pesi per fondere le previsioni di ogni vicino, producendo un valore di colore finale in quella posizione. Poiché questa ponderazione è appresa, MLIN può trattare in modo molto diverso regioni complesse—come quartieri residenziali densi, porti con navi o aeroporti con piste—rispetto ad aree lisce come deserti o oceani. Esperimenti su due dataset satellitari largamente usati (WHU‑RS19 e UCMerced) mostrano che MLIN fornisce costantemente punteggi numerici di qualità più alti e dettagli visivamente più nitidi rispetto a diversi metodi leader per lo zoom continuo, sia a livelli di ingrandimento familiari sia a ingrandimenti estremi fino a dieci volte.
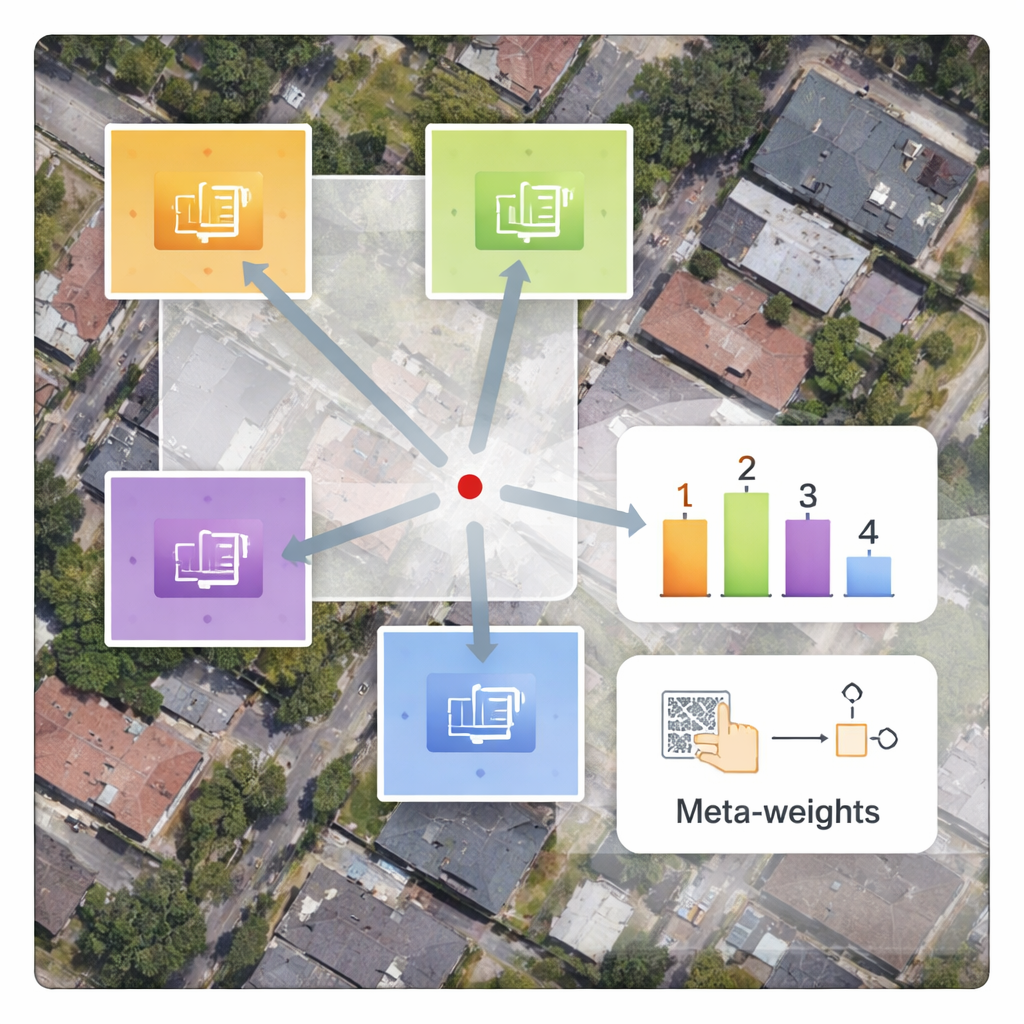
Allenamento più veloce senza ritardi aggiuntivi
Un vantaggio pratico del progetto è che vanno addestrati solo il nuovo decoder e la rete dei meta-pesi sulle immagini satellitari, mentre il grande encoder resta fissato. Questo riduce notevolmente il tempo di addestramento rispetto a metodi che riaddestrano tutti i parametri da zero. Anche se la meta-rete introduce calcoli aggiuntivi, le moderne GPU gestiscono queste operazioni in modo efficiente, quindi il tempo per processare una singola immagine resta quasi lo stesso delle metodologie esistenti. Studi di ablation—test accurati in cui parti del sistema vengono rimosse o semplificate—confermano che la ponderazione sensibile al contenuto è l'ingrediente chiave che migliora sia la nitidezza dei bordi sia la continuità delle texture.
Occhi più chiari sulla Terra
In termini semplici, questo lavoro mostra come riutilizzare potenti modelli di immagini addestrati su foto quotidiane e adattarli in modo intelligente al mondo molto diverso delle immagini satellitari. Consentendo al sistema di imparare come bilanciare le informazioni dai pixel vicini in base a ciò che è effettivamente presente nella scena, MLIN produce immagini satellitari più chiare e più affidabili a qualsiasi livello di zoom con un unico modello. Questo significa strumenti migliori per scienziati, pianificatori e soccorritori che dipendono da viste dettagliate del nostro pianeta, mantenendo al contempo gestibili i requisiti di calcolo e archivio.
Citazione: Zhang, Q., Ma, S., Tang, Y. et al. Cross-domain continuous-scale remote sensing image super-resolution via meta-weight learning. Sci Rep 16, 6073 (2026). https://doi.org/10.1038/s41598-026-36632-w
Parole chiave: super-risoluzione satellitare, immagini di telerilevamento, meta-learning, zoom a scala arbitraria, miglioramento delle immagini