Clear Sky Science · it
Valutazione dettagliata dei grandi modelli linguistici in medicina mediante modellazione diagnostica cognitiva non parametrica
Perché questo conta per le visite mediche future
I sistemi di intelligenza artificiale che parlano e scrivono, noti come grandi modelli linguistici, stanno rapidamente passando dai laboratori di ricerca agli ospedali. Possono già aiutare i medici a leggere cartelle complesse, suggerire trattamenti e rispondere a domande mediche. Ma la maggior parte dei test su questi sistemi fornisce un solo punteggio complessivo, simile a un voto finale, che può nascondere punti ciechi pericolosi. Questo studio mostra un nuovo modo di analizzare quei punteggi e rivelare esattamente in quali aree della medicina questi modelli comprendono davvero—e dove potrebbero ancora mettere a rischio i pazienti.
Oltre il singolo punteggio d’esame
Oggi la maggior parte delle IA mediche viene giudicata in base a quante domande risponde correttamente in esami modellati sui test di abilitazione dei medici. Questo approccio è semplice ma rozzo. Un modello potrebbe ottenere un punteggio complessivo elevato pur essendo debole in un campo critico come l’analisi del ritmo cardiaco o le malattie del fegato. Nelle cliniche reali tali lacune possono avere conseguenze di vita o di morte. Gli autori sostengono che un uso sicuro dell’IA in medicina richiede una valutazione più profonda e dettagliata—capace di tracciare un profilo di competenze dettagliato invece di assegnare un unico voto potenzialmente fuorviante.

Un modo più intelligente per testare le competenze mediche
Per ottenerlo, i ricercatori adottano strumenti dalla psicologia dell’educazione chiamati valutazioni diagnostiche cognitive. Invece di trattare ogni domanda d’esame come se misurasse la stessa abilità generica, questo metodo scompone le conoscenze mediche in blocchi di competenze specifiche, come cardiologia, radiologia o pronto soccorso. Ogni domanda a scelta multipla viene etichettata con il preciso mix di abilità richieste. Usando una tecnica statistica non parametrica, il team confronta come un modello risponde a migliaia di tali domande con i pattern di risposta ideali. Da questo inferiscono se il modello ha “padroneggiato” ciascuna abilità sottostante, proprio come un pagellino dettagliato mostra punti di forza e debolezze nelle materie scolastiche.
Mettere alla prova 41 modelli di IA con un esame medico
Il team ha testato 41 modelli linguistici ampiamente usati, includendo sia sistemi commerciali sia modelli open source, su 2.809 domande accuratamente selezionate tratte da una banca domande di un esame medico nazionale cinese. Queste domande coprono 22 sotto-discipline mediche e sono pensate per studenti sull’orlo dell’esame di abilitazione a medico. Ogni domanda ha una risposta corretta ed è etichettata da esperti per indicare quali specialità coinvolge. Usando il loro metodo diagnostico, i ricercatori hanno stimato, per ciascun modello, quante di queste 22 caratteristiche mediche esso ha effettivamente padroneggiato, non solo quante domande ha indovinato per caso.
Buone conoscenze generali, ma netti punti ciechi
I risultati sono allo stesso tempo impressionanti e preoccupanti. I modelli con le migliori prestazioni, come diversi sistemi commerciali di punta, hanno risposto correttamente alla maggior parte delle domande e mostrato la padronanza di 20 delle 22 aree mediche. Complessivamente, le prestazioni sono state ottime in molte specialità comuni, raggiungendo la padronanza completa in 15 ambiti tra cui cardiologia, dermatologia ed endocrinologia. Eppure l’analisi dettagliata ha messo in luce lacune marcate in altri campi. La radiologia è rimasta indietro con tassi di padronanza molto più bassi, e due sotto-discipline—ECG & ipertensione & lipidi e disturbi del fegato—non sono state padroneggiate da nessun modello. È importante notare che alcuni modelli più piccoli condividevano le stesse competenze padroneggiate di modelli molto più grandi, rivelando che la sola dimensione non garantisce una conoscenza medica ampia e affidabile.
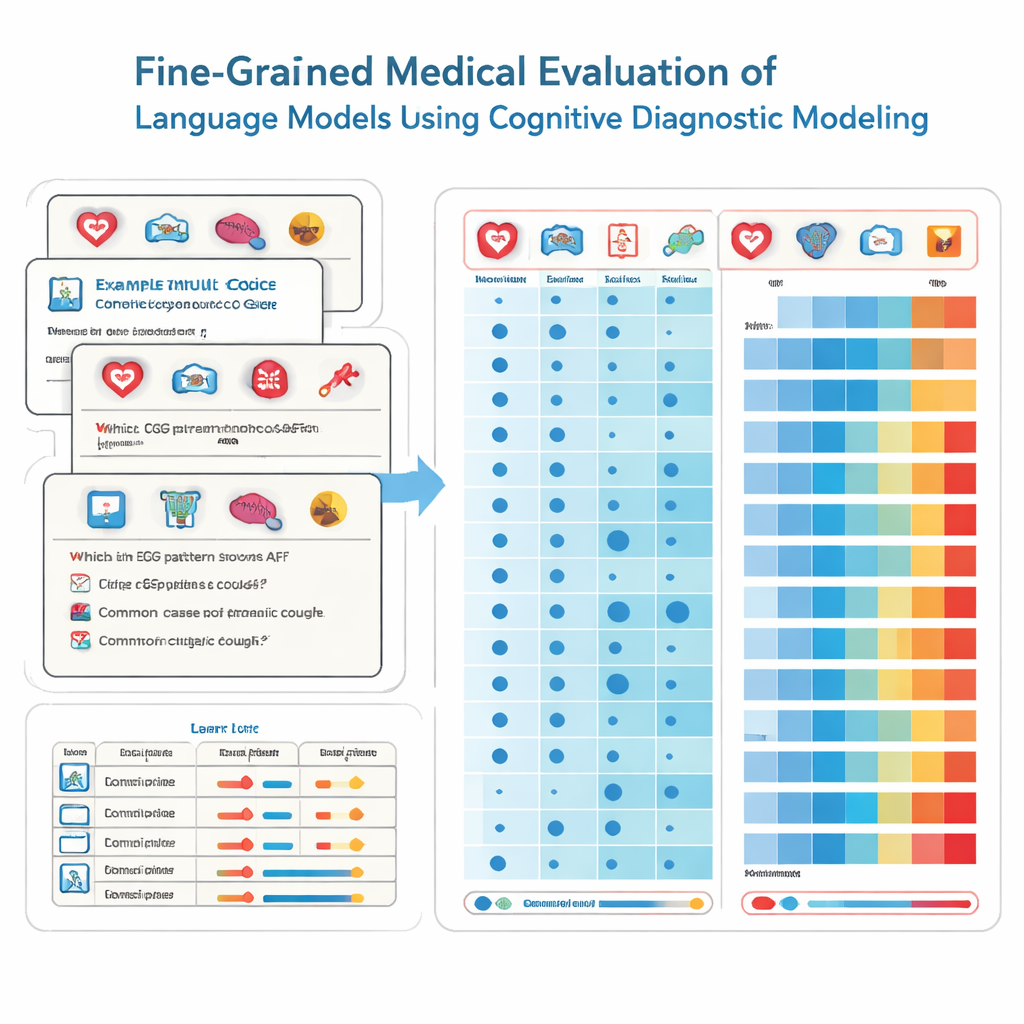
Scegliere lo strumento giusto per il compito giusto
Questi profili dettagliati sono importanti perché modelli con punteggi complessivi molto simili possono mostrare schemi di punti di forza e debolezza molto diversi. Un sistema potrebbe essere forte in neurologia ma debole in farmacologia, mentre un altro mostra il quadro opposto. Per i responsabili degli ospedali ciò significa che non si può scegliere in sicurezza un assistente IA basandosi solo sul suo punteggio d’esame principale o sul numero di parametri. Invece, servono risultati diagnostici come quelli di questo studio per abbinarе ogni modello a compiti clinici specifici, e per progettare flussi di lavoro in cui specialisti umani ricontrollino le uscite dell’IA nelle aree ad alto rischio dove il modello è noto per essere debole.
Cosa significa per pazienti e clinici
In parole semplici, lo studio conclude che un alto “voto” nei test medici non garantisce che un sistema di IA sia sicuro da usare in tutte le parti della medicina. Il nuovo approccio funziona più come un check-up accurato per l’IA stessa, rivelando quali “organi”—in questo caso, specialità mediche—sono sani e quali richiedono attenzione. Scoprendo gap nascosti in aree critiche come l’interpretazione dell’ECG e le malattie del fegato, il metodo offre a ospedali, regolatori e sviluppatori una tabella di marcia pratica: usare i modelli solo dove sono stati dimostrati forti, mantenere gli esseri umani saldamente nel processo nelle aree di debolezza, e concentrare la formazione futura sui punti ciechi più rischiosi. Questo tipo di valutazione fine-grained, sostengono gli autori, non è solo utile—è essenziale prima di affidare all’IA la cura dei pazienti.
Citazione: Zheng, T., Liu, J., Feng, S. et al. Fine-grained evaluation of large language models in medicine using non-parametric cognitive diagnostic modeling. Sci Rep 16, 6460 (2026). https://doi.org/10.1038/s41598-026-36627-7
Parole chiave: IA medica, grandi modelli linguistici, sicurezza clinica, valutazione dei modelli, test diagnostici