Clear Sky Science · it
Ottimizzazione multitask e stabilità di convergenza con apprendimento gerarchico delle feature per ottimizzazione auto‑guidata
Un'IA più intelligente che sa gestire molti compiti contemporaneamente
Le applicazioni moderne si affidano sempre più a intelligenze artificiali chiamate a svolgere più attività in parallelo—per esempio comprendere immagini e testi insieme, supportare decisioni mediche o aiutare le auto a percepire la strada. Però quando un singolo modello impara troppe abilità insieme, l’addestramento può diventare instabile e le capacità possono interferire tra loro. Questo articolo presenta un nuovo framework di deep learning, chiamato Unified Multitask and Multiview Deep Architecture (UMDA), progettato per permettere a un unico modello di apprendere da molti tipi di dati e risolvere molteplici compiti senza confondersi o perdere stabilità.
Perché l’IA multi‑abilità odierna spesso fatica
La maggior parte dei sistemi attuali che apprendono più compiti (multitask learning) o combinano più tipi di dati, come immagini e testo (multiview learning), soffre di tre problemi principali. Primo, compiti diversi possono entrare in conflitto durante l’addestramento: migliorare le prestazioni su un compito può danneggiarne un altro, un fenomeno noto come trasferimento negativo. Secondo, il semplice impilamento o la media delle informazioni provenienti da fonti diverse spesso perde relazioni sottili ma importanti tra di esse. Terzo, il processo di addestramento stesso può diventare instabile, con grandi oscillazioni nella direzione degli aggiornamenti dei parametri del modello. Questi problemi sono particolarmente gravi in contesti reali come la diagnostica medica o l’ispezione industriale, dove i dati sono complessi e le decisioni devono essere affidabili.
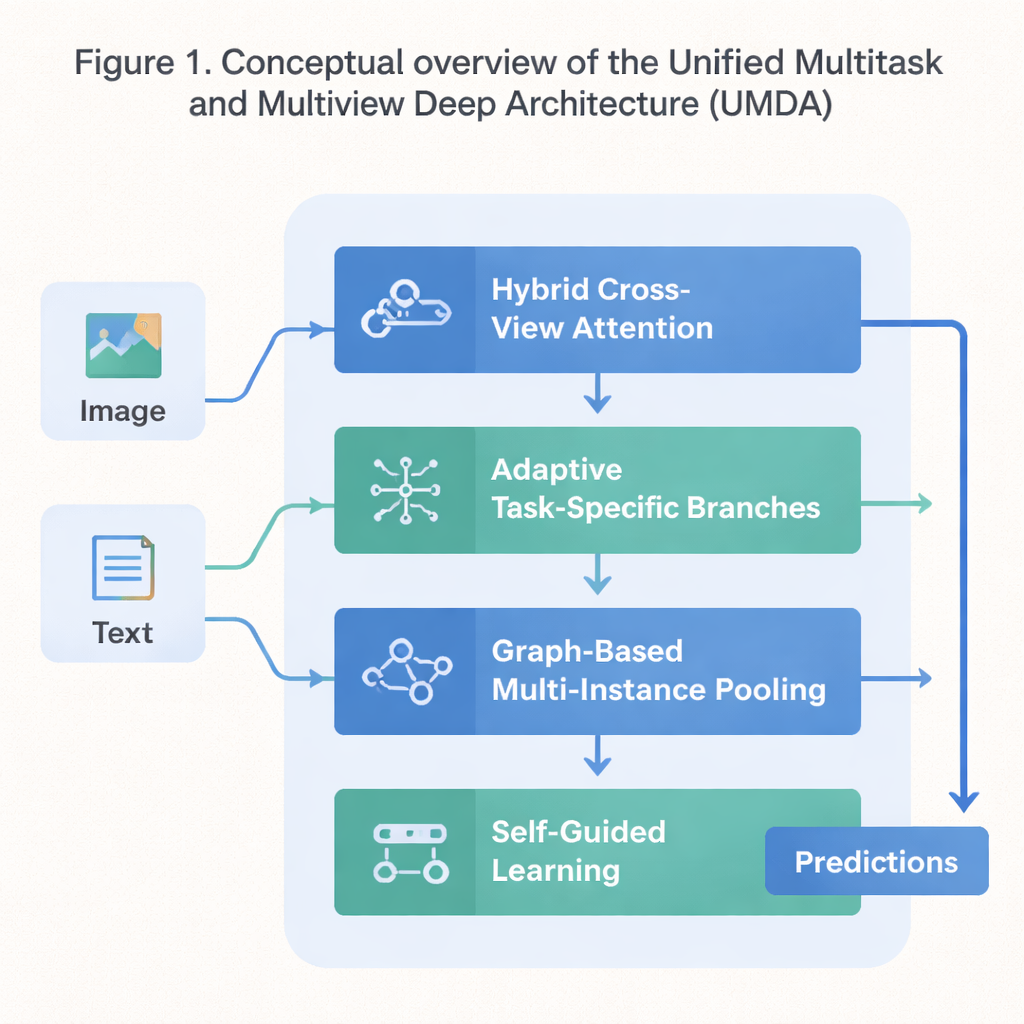
Un progetto in quattro parti per un apprendimento cooperativo
UMDA affronta queste debolezze suddividendo il processo di apprendimento in quattro parti strettamente connesse che condividono informazioni in modo controllato. La prima parte, chiamata Hybrid Cross‑View Attention, osserva diverse viste dello stesso dato—come testo e immagini che descrivono un film—and apprende quale vista dovrebbe influenzarne un’altra a ogni passo. Utilizza strumenti matematici che spingono il modello a non affidarsi eccessivamente a una singola vista, a mantenere ciascuna vista distintiva e, allo stesso tempo, a conservarne un accordo generale. In termini semplici, insegna al modello a ascoltare tutti i suoi “sensi” senza permettere a uno di sovrastare gli altri.
Mantenere i compiti distinti ma ancora cooperativi
La seconda parte, Adaptive Task‑Specific Branching, separa la conoscenza generica che molti compiti condividono dalla conoscenza speciale che ciascun compito richiede in modo univoco. Invece di costringere tutti i compiti a usare esattamente le stesse feature, UMDA costruisce “ramificazioni” separate per ogni compito che possono comunque comunicare tra loro tramite connessioni pesate con cura. Termini di penalità aggiuntivi nell’obiettivo di addestramento spingono queste ramificazioni a essere sufficientemente diverse da specializzarsi, ma non così diverse da allontanarsi e smettere di cooperare. Questo equilibrio aiuta a ridurre le interferenze dannose tra i compiti pur permettendo loro di beneficiare di quanto apprendono gli altri.
Vedere la struttura nelle collezioni di esempi
Molti dataset reali sono costituiti da collezioni di elementi correlati—per esempio più patch d’immagine da una singola vetrino medicale o molti frame di un video. La terza parte di UMDA, chiamata Graph‑Based Multi‑Instance Pooling, modella esplicitamente le relazioni tra questi elementi trattandoli come nodi di una rete. Connette elementi simili, permette il flusso di informazioni lungo queste connessioni e poi riassume l’intera collezione in una singola rappresentazione compatta. Una regolarizzazione aggiuntiva incoraggia gli elementi vicini ad accordarsi tra loro mantenendo però sufficiente diversità, consentendo al modello di catturare pattern strutturali che una semplice media perderebbe.
Addestramento auto‑tarato per un progresso stabile
L’ultima parte, Self‑Guided Learning, si concentra su come il modello viene addestrato piuttosto che sulla sua struttura interna. Misura continuamente quanto sono forti e quanto sono simili i segnali di addestramento di ciascun compito e poi regola automaticamente la velocità di apprendimento per ogni compito. Inoltre ammorbidisce e ripesa i gradienti—i segnali che indicano al modello come cambiare—così che compiti con obiettivi simili si rinforzino a vicenda e compiti che tirano in direzioni molto diverse non destabilizzino l’addestramento. Testato su un dataset standard che combina trame e poster di film, UMDA ha raggiunto una precisione media superiore rispetto a una dozzina di metodi all’avanguardia, ha mantenuto le relazioni tra le viste più coerenti e ha ridotto di oltre la metà una misura chiave di instabilità dell’addestramento.
Cosa significa questo per i sistemi IA nel mondo reale
Per i non specialisti, il messaggio chiave è che UMDA offre un modo per costruire modelli di IA singoli in grado di gestire più tipi di dati e obiettivi in modo più affidabile. Insegnando al modello quando condividere informazioni e quando mantenerle separate, e permettendogli di sintonizzare automaticamente il proprio apprendimento, il framework fornisce previsioni migliori, rappresentazioni interne più coerenti e un addestramento più regolare. Questo lo rende un elemento promettente per sistemi futuri in medicina, guida autonoma e altre applicazioni complesse dove l’IA deve interpretare molti segnali contemporaneamente senza perdere l’equilibrio.
Citazione: Mahmood, K., Althobaiti, M.M., Hassan, M.U. et al. Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization. Sci Rep 16, 6414 (2026). https://doi.org/10.1038/s41598-026-36622-y
Parole chiave: apprendimento multitask, IA multimodale, stabilità del deep learning, reti ad attenzione, reti neurali a grafo