Clear Sky Science · it
Elaborazione dei dati di cristallografia seriale a femtosecondi presso il centro hub dati scientifici globale di KISTI
Perché i cristalli minuscoli hanno bisogno di grandi computer
I moderni laser a raggi X possono realizzare “film molecolari” di proteine e altre molecole sparando impulsi ultra‑brevi e ultra‑intensi su innumerevoli cristalli minuscoli. Questo approccio, chiamato cristallografia seriale a femtosecondi, genera un flusso di immagini che rivelano l’aspetto e il movimento delle molecole a temperatura ambiente. C’è però un problema: un singolo esperimento può produrre terabyte di dati, molto più di quanto un tipico computer di laboratorio possa gestire rapidamente. Questo articolo spiega come il centro nazionale dati della Corea, GSDC presso KISTI, sia stato progettato e testato per elaborare efficientemente questi enormi insiemi di dati e quali lezioni pratiche gli scienziati possono adottare per passare dalle immagini grezze alle strutture 3D senza lunghi ritardi. 
Dai lampi del laser agli scatti strutturali
Nella cristallografia seriale a femtosecondi, un laser a elettrone libero a raggi X (XFEL) spara impulsi rapidi su flussi o matrici di cristalli microscopici. Ogni cristallo viene colpito una sola volta, producendo un unico pattern di diffrazione “istantaneo” prima di essere distrutto. Per ricostruire la struttura tridimensionale completa della molecola, gli scienziati devono combinare centinaia di migliaia fino a milioni di questi scatti. Molte immagini sono inutili: alcune non contengono segnale, altre mostrano più cristalli sovrapposti. Le immagini utili (i cosiddetti “hit”) devono essere rilevate, ordinate e convertite in dati di intensità che possano essere fusi in una struttura di alta qualità. Eseguire tutto ciò in tempo quasi reale richiede calcolo ad alte prestazioni, specialmente quando il laser funziona a decine di impulsi al secondo.
Un hub dati nazionale per esperimenti a raggi X
Il Global Science Data hub Center (GSDC) presso KISTI è stato creato come struttura su scala nazionale per servire le scienze a elevata intensità di dati, dalla fisica delle particelle alla genomica. Per la cristallografia seriale presso l’XFEL del Pohang Accelerator Laboratory (PAL‑XFEL), il GSDC gestisce tre server dedicati dotati di decine di core CPU, centinaia di gigabyte di memoria e un sistema di storage parallelo ad alta velocità. Durante gli esperimenti alla stazione di nanocristallografia del PAL‑XFEL, le immagini di diffrazione vengono raccolte da un rivelatore X‑ray veloce e trasmesse al GSDC tramite un collegamento a 10 gigabit al secondo. Un singolo esperimento di 12–24 ore può generare da alcuni fino a quasi dieci terabyte di dati. Al GSDC gli utenti si connettono da remoto, filtrano i frame non utili ed eseguono software specializzati — come CrystFEL e i programmi di indicizzazione associati — per trasformare le immagini grezze in dati strutturali raffinati. 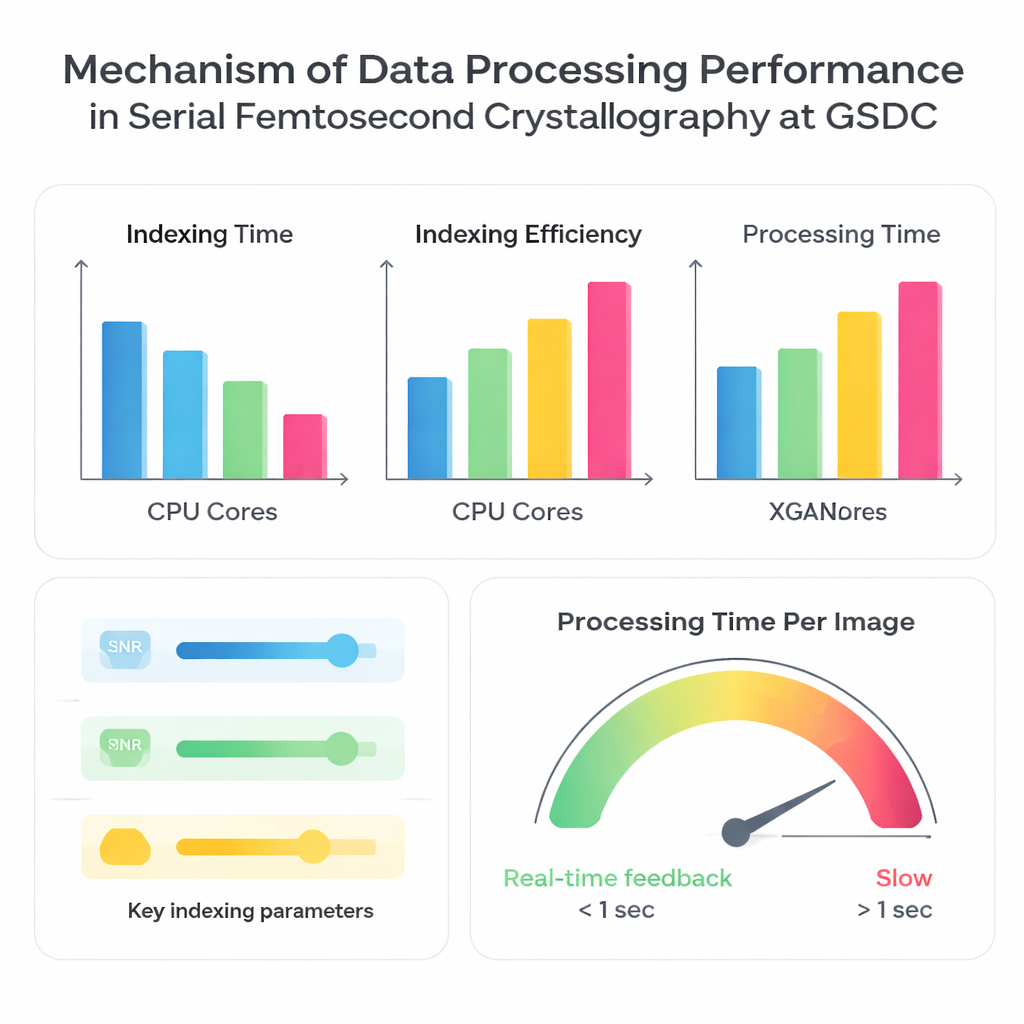
Quanti processori aiutano, e quando
Gli autori hanno messo alla prova il sistema GSDC utilizzando tre dataset precedentemente raccolti da proteine diverse. Prima hanno valutato quanto migliora la velocità di elaborazione usando più core CPU in parallelo. Come previsto, l’impiego di più processori ha ridotto il tempo totale necessario per indicizzare le immagini, ma non in modo perfettamente proporzionale. Passare da 10 a circa 30–40 core CPU ha dato forti guadagni, dopo i quali i benefici si sono attenuati. Oltre quel punto, l’aggiunta di core ha introdotto overhead ed è stata limitata da fattori come la larghezza di banda della memoria, la velocità di input/output nella lettura di molti file piccoli e la coordinazione tra numerosi task paralleli. Questo mostra chiaramente che “più core” non è sempre meglio; esiste un punto ottimale in cui l’hardware viene utilizzato in modo efficiente senza diventare un collo di bottiglia.
Il compromesso tra velocità e completezza
Successivamente il team ha confrontato quattro algoritmi di indicizzazione ampiamente usati — XDS, DirAx, MOSFLM e XGANDALF — sulla stessa piattaforma di calcolo. Alcuni metodi, come XDS e DirAx, sono risultati complessivamente più veloci ma hanno identificato una frazione minore di immagini che potevano essere trasformate con successo in pattern di diffrazione utili. Altri, come MOSFLM e XGANDALF, erano più lenti ma convertivano un maggior numero di immagini in dati utilizzabili e in genere producevano migliore qualità statistica nel dataset finale unificato. Gli autori hanno anche esplorato come semplici scelte di input influenzino sia la velocità sia il tasso di successo: innalzare la soglia segnale‑rumore o disattivare l’indicizzazione multi‑cristallo rendeva l’elaborazione più veloce ma riduceva il numero di immagini utilizzabili; abbassare la soglia o abilitare la gestione multi‑cristallo aveva l’effetto opposto. In modo cruciale, anche piccoli errori nella geometria del rivelatore — come la distanza tra rivelatore e campione — causavano un fallimento più frequente dell’indicizzazione e rallentavano drasticamente l’elaborazione, perché il software continuava a tentare soluzioni errate e a rifiutarle.
Cosa significa per gli esperimenti futuri
Misurando sistematicamente come le scelte hardware, gli algoritmi software e le impostazioni controllate dall’utente influenzano le prestazioni, questo studio trasforma una complessa sfida di gestione dei dati in una serie di linee guida pratiche. Per gli scienziati che pianificano esperimenti al PAL‑XFEL, mostra quando il processamento parallelo è più efficace, quali programmi di indicizzazione sono migliori per un feedback rapido rispetto alla massima qualità dei dati e perché la calibrazione accurata della geometria del rivelatore è così importante. Gli autori concludono che il GSDC già consente un’elaborazione efficiente e, in alcuni casi, un feedback in tempo reale durante la raccolta dei dati, ma che sarà necessaria un’ulteriore espansione delle risorse di calcolo man mano che aumenteranno le frequenze di ripetizione e le dimensioni dei dataset. Per i non esperti, il messaggio chiave è che realizzare "film" delle molecole non è solo un trionfo di laser e rivelatori avanzati: dipende in modo critico anche da centri di calcolo ben progettati in grado di sostenere l’ondata di dati.
Citazione: Nam, K.H., Na, SH. Serial femtosecond crystallography data processing at the global science data hub center at KISTI. Sci Rep 16, 6786 (2026). https://doi.org/10.1038/s41598-026-36540-z
Parole chiave: cristallografia seriale a femtosecondi, laser a elettrone libero a raggi X, calcolo ad alte prestazioni, elaborazione dei dati, struttura delle proteine