Clear Sky Science · it
Un modello ibrido ResNet50-vision transformer con un meccanismo di attenzione per la classificazione di immagini aeree
Perché occhi più intelligenti nel cielo contano
Le foto aeree riprese da droni e satelliti guidano oggi la risposta ai disastri, la pianificazione urbana, l'agricoltura e persino il controllo del traffico. Ma insegnare ai computer a comprendere queste viste complesse e affollate dall'alto è ancora difficile. Questo studio presenta due nuovi modelli di intelligenza artificiale che combinano diversi modi di “vedere” le immagini per riconoscere dieci tipi di oggetti nelle foto da drone — come edifici, auto, alberi e strade — con una precisione migliore rispetto ai metodi precedenti. L'approccio potrebbe rendere il monitoraggio automatizzato dall'alto più veloce, più affidabile e più semplice da implementare in contesti reali.
Sfide nel guardare il mondo dall'alto
Le immagini aeree differiscono dalle foto quotidiane che scattiamo con i nostri telefoni. Gli oggetti sono più piccoli, possono apparire a angolazioni insolite e spesso sono ravvicinati. Un'auto parzialmente nascosta da un albero, un sentiero stretto o cumuli di detriti dopo una frana possono essere difficili da individuare rapidamente anche per gli esseri umani. Eppure governi, squadre di emergenza e agenzie ambientali si affidano sempre più alle viste da droni e satelliti per monitorare alluvioni, incendi boschivi, crescita urbana e danni alle infrastrutture. Con migliaia di satelliti in orbita e un mercato dell'imaging aereo in espansione, il volume dei dati cresce troppo velocemente perché le persone possano ispezionarli manualmente, aumentando la necessità di una classificazione automatica più accurata ed efficiente.
Fondere due modi in cui le macchine imparano a vedere
La maggior parte dei sistemi di riconoscimento delle immagini di successo oggi si basa sul deep learning. Una famiglia, le reti neurali convoluzionali, eccelle nell'individuare pattern locali come bordi, texture e piccole forme. Un'altra, più recente, chiamata vision transformer tratta un'immagine come una sequenza di patch ed è particolarmente efficace nel catturare relazioni a lungo raggio, ad esempio come una strada, un gruppo di tetti e un campo vicino si combinano in una scena. Questo lavoro combina entrambe: un noto modello convoluzionale chiamato ResNet-50 e un vision transformer. Ciascuno elabora la stessa immagine aerea ed estrae il proprio set di caratteristiche numeriche — sintesi compatte di ciò che la rete ha appreso sulla scena. Questi due flussi di informazione vengono quindi uniti e passati a un modulo di “attenzione” che impara quali caratteristiche sono più rilevanti per decidere tra le dieci classi target.
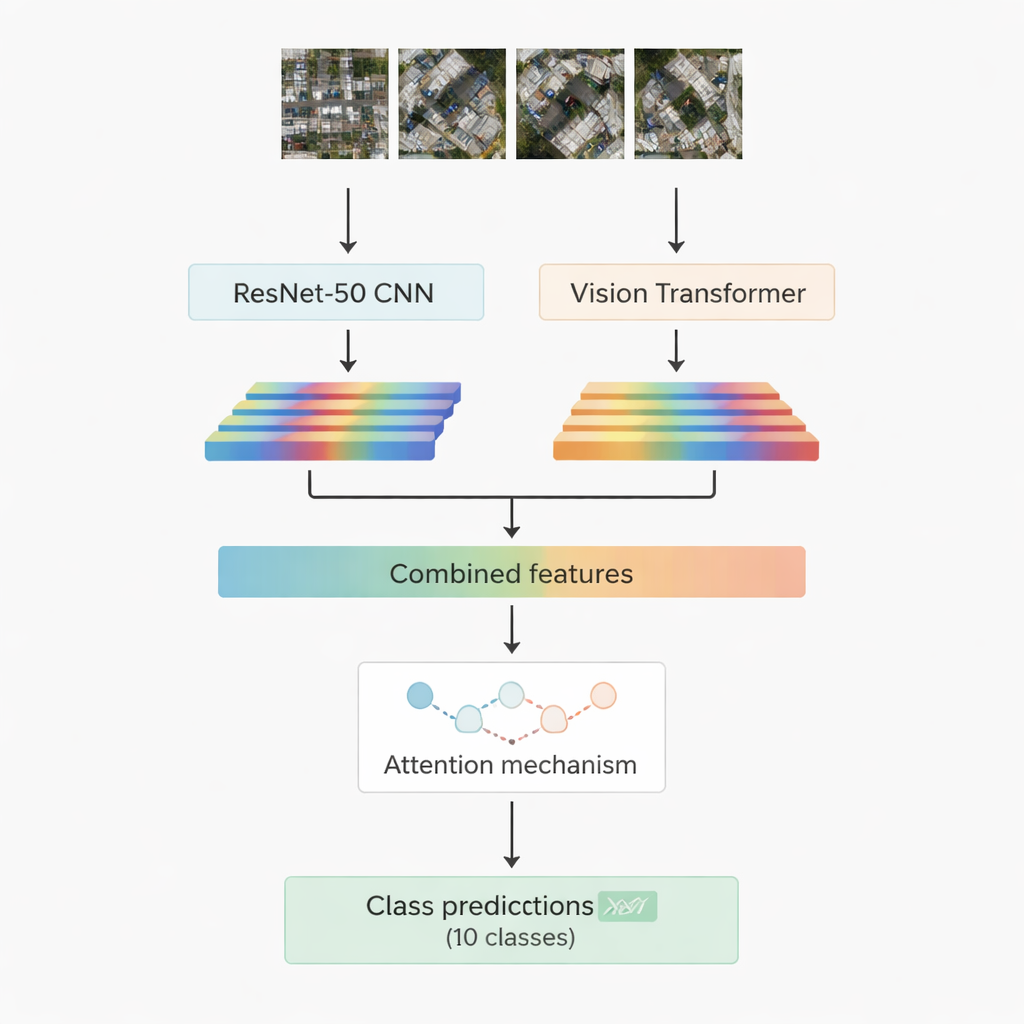
Due strategie di attenzione per concentrarsi su ciò che conta
I ricercatori progettano e testano due versioni del loro sistema ibrido. Nella prima, semplicemente uniscono le caratteristiche di ResNet-50 e del transformer e le inviano a un modulo di attenzione multi-head. Questo meccanismo può essere pensato come molte piccole luci che osservano le caratteristiche da angolazioni leggermente diverse e poi combinano i risultati. Nella seconda versione usano la cross-attention: le caratteristiche della rete convoluzionale agiscono come query che chiedono alle caratteristiche del transformer dove guardare, permettendo a un flusso di guidare l'altro. In entrambi i casi, l'output dell'attenzione viene passato attraverso layer standard che infine assegnano la patch d'immagine a una delle dieci classi, tra cui edifici, auto, detriti, sentieri pedonali, strade metalliche, campi aperti, ombre, serbatoi, alberi e tetti.
Test su immagini reali da droni
Per valutare l'efficacia dei loro modelli, gli autori utilizzano un dataset pubblico dallo stato indiano del Sikkim, raccolto da un drone che volava a 60–120 metri di altezza. I dati coprono fiumi, foreste, colline e aree urbanizzate, suddivisi in piccole patch in modo che ogni immagine rientri in una delle dieci categorie. Il dataset è bilanciato, con un numero uguale di immagini per addestramento e test per ogni classe, rendendolo un banco di prova equo. I ricercatori addestrano entrambe le versioni ibride in condizioni identiche e poi confrontano le loro prestazioni usando misure ampiamente adottate: accuratezza, precisione, recall, F1-score, matrici di confusione e curve ROC. Confrontano inoltre i risultati con diverse reti note e con metodi più recenti basati sui transformer presenti in letteratura.

Classificazione più nitida e potenziale nel mondo reale
Entrambi i modelli ibridi superano i sistemi precedenti su questo dataset, raggiungendo accuratezze complessive del 95,52% e del 95,80%, con la versione a attenzione multi-head leggermente in vantaggio. Le loro prestazioni restano solide e stabili su tutte e dieci le tipologie di oggetto, e analisi dettagliate mostrano che anche le classi più deboli vengono riconosciute con tassi elevati. Ciò suggerisce che miscelare reti convoluzionali, vision transformer e meccanismi di attenzione è una ricetta potente per comprendere scene aeree complesse. Per il lettore non specialistico, il risultato principale è che i computer stanno diventando molto migliori nel rispondere a domande come “Dove sono le strade?” o “Quali patch mostrano detriti o edifici?” in grandi collezioni di immagini da drone. Man mano che questi modelli vengono perfezionati ed estesi a nuovi dataset, potrebbero supportare una risposta ai disastri più intelligente, il monitoraggio ambientale e i servizi per le smart city che dipendono da un'interpretazione rapida e affidabile delle immagini dall'alto.
Citazione: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
Parole chiave: classificazione di immagini aeree, immagini da droni, deep learning, vision transformer, telerilevamento