Clear Sky Science · it
Analisi delle prestazioni di una rete a cascata con attenzione ottimizzata e shuffle per dipendenze a lungo termine nell’apprendimento adattivo tra professionisti IT
Formazione online più intelligente per professionisti tech che lavorano
Per molti professionisti dell’informatica, i corsi online sono ormai il principale mezzo per aggiornare le competenze. Tuttavia la maggior parte delle piattaforme di formazione valuta ancora le persone con strumenti grezzi come il totale dei quiz o i badge di completamento. Questo studio presenta un modo più intelligente di leggere le “impronte” digitali che gli apprendenti lasciano e trasformarle in intuizioni precise e in tempo reale su quanto ciascuno stia effettivamente imparando.
Perché i corsi online uguali per tutti non bastano
L’e‑learning convenzionale tratta la maggior parte degli studenti allo stesso modo: tutti vedono gli stessi moduli, svolgono gli stessi quiz e vengono giudicati con gli stessi test fissi. Questo approccio ignora quanto i professionisti possano progredire in modo diverso, soprattutto in ambiti in rapida evoluzione come la cybersecurity o il cloud computing. Ricerche precedenti hanno provato a risolvere il problema con il machine learning—combinando punteggi dei quiz, tempo impiegato e dati di clic per prevedere il successo—ma molti modelli hanno faticato con dati rumorosi o incompleti, non sono riusciti a scalare a piattaforme realistiche o non hanno seguito come l’apprendimento si sviluppa nel corso di settimane e mesi. Il risultato è spesso un feedback ritardato e grossolano che non guida facilmente contenuti personalizzati o interventi tempestivi.
Trasformare i log grezzi del corso in dati puliti e equi
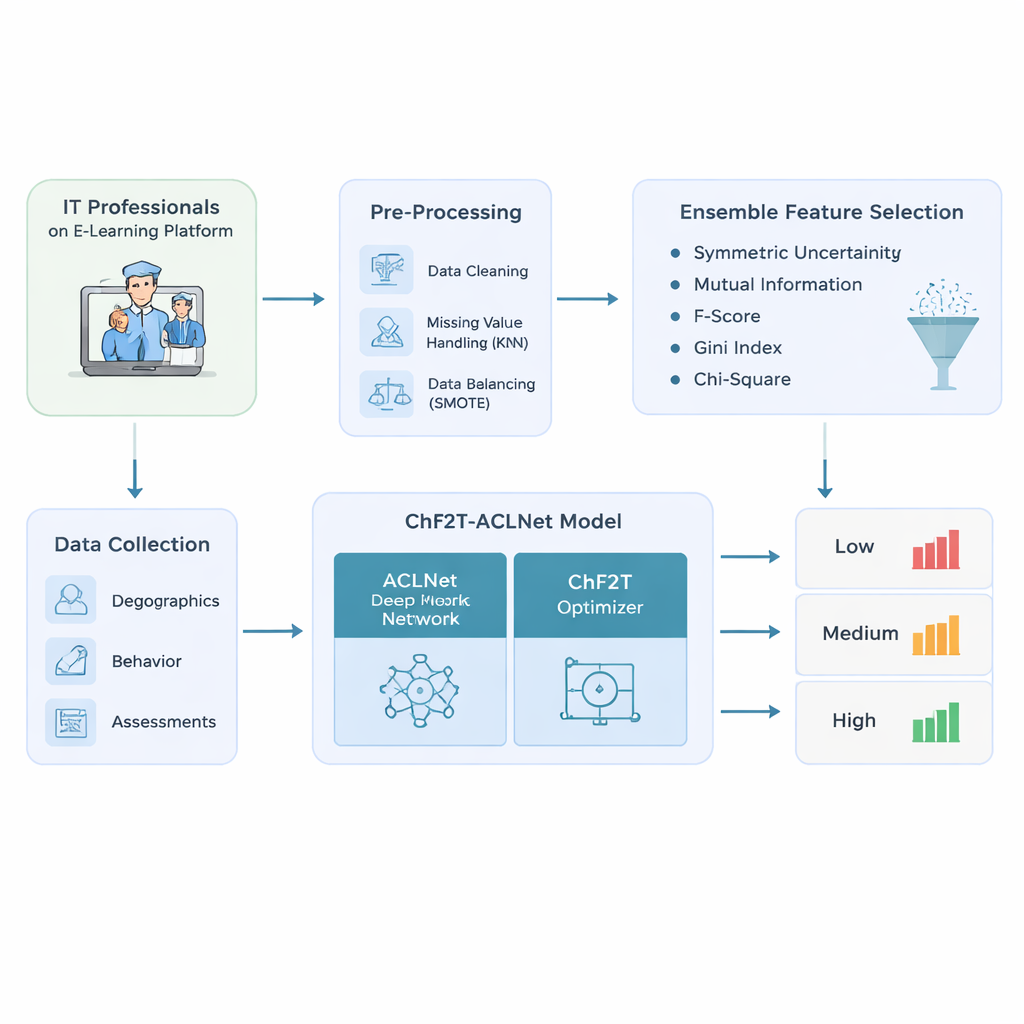
Gli autori iniziano progettando una pipeline di dati accurata per professionisti IT che usano piattaforme di e‑learning adattivo. Raccolgono un mix ricco di informazioni: dettagli di profilo di base come età e ruolo lavorativo; tracce comportamentali come tempo speso, date di accesso e giorni attivi; e indicatori di prestazione inclusi punteggi dei quiz, tentativi, certificati e valutazioni del feedback. Prima di qualsiasi modellazione, ripuliscono i dati—rimuovendo record duplicati, stimando i valori mancanti osservando apprendenti simili e correggendo distribuzioni di classe sbilanciate in modo che i performer bassi, medi e alti siano rappresentati più equamente. Questo passaggio di bilanciamento evita modelli che risultano eccessivamente sicuri solo per gli apprendenti “medi” più comuni e ciechi verso chi fatica o eccelle.
Selezionare solo i segnali più rivelatori
Dal dataset pulito, il sistema non si limita a inserire ogni colonna disponibile in una scatola nera. Usa invece un ensemble di cinque metodi di ranking semplici per decidere quali caratteristiche contano davvero per predire gli esiti di apprendimento. Ogni metodo esamina la connessione tra una caratteristica candidata—come i tentativi di quiz o il tempo impiegato—e l’etichetta finale di prestazione. Combinando i loro ranking tramite uno score mediano, l’approccio filtra segnali rumorosi o ridondanti e mantiene soltanto quelli più informativi. Questo non solo riduce la quantità di calcolo necessaria al modello successivo, ma lo aiuta anche a concentrarsi su pattern che distinguono in modo significativo i performer bassi, medi e alti.
Una rete ibrida addestrata come una squadra sportiva
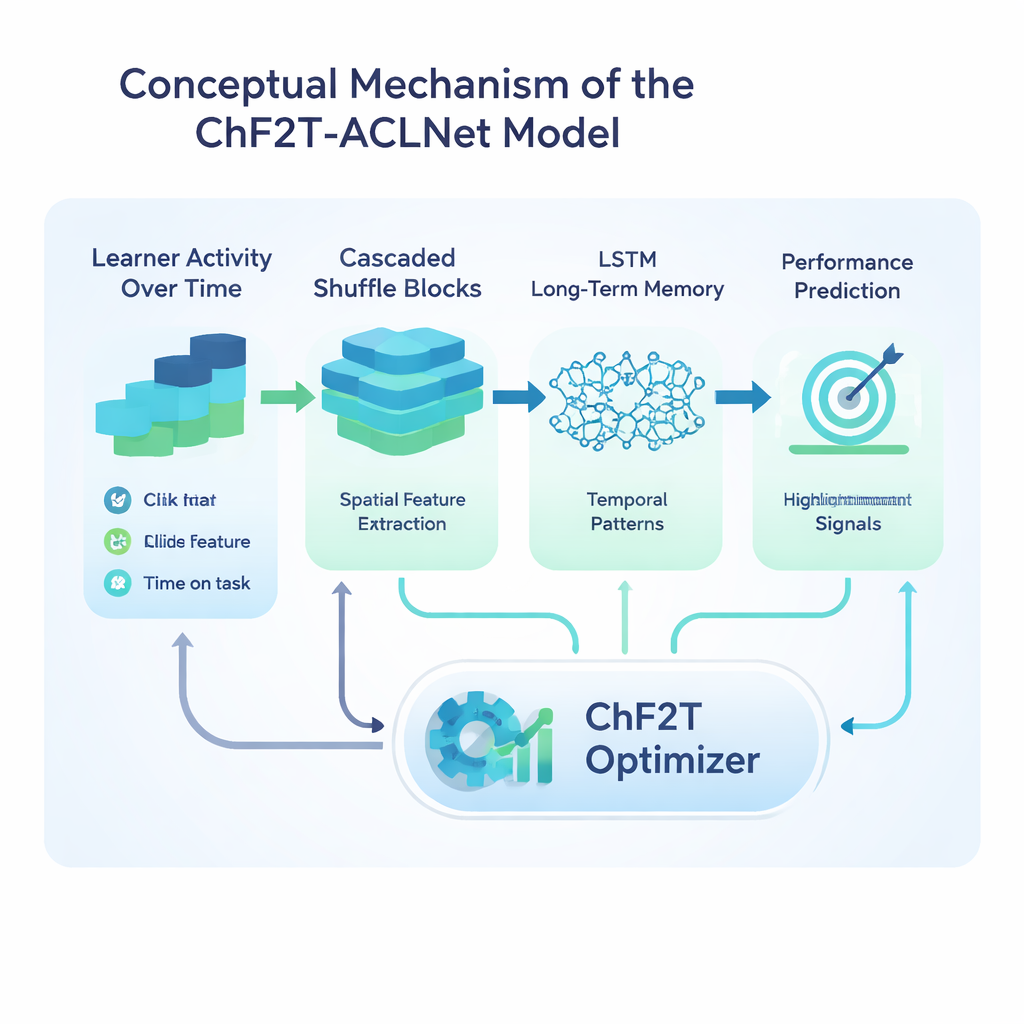
Il cuore dello studio è un modello di deep learning ibrido chiamato ACLNet, abbinato a una strategia di allenamento non convenzionale ispirata agli sport di squadra. ACLNet utilizza innanzitutto blocchi “shuffle” leggeri per comprimere e mescolare i segnali di input in modo efficiente, quindi li inoltra in un modulo di memoria che traccia come il comportamento di un apprendente cambia nel tempo. Uno strato di attenzione in cima mette in evidenza i canali più influenti—come cali repentini di attività o punteggi di quiz costantemente alti—prima di formulare la previsione finale della classe di prestazione dell’apprendente. Per calibrare i numerosi parametri interni di questa rete, gli autori introducono un algoritmo Chaotic Football Team Training (ChF2T). Qui, “giocatori” virtuali esplorano diverse impostazioni dei parametri, imitando i performanti, evitando i deboli e occasionalmente compiendo grandi salti caotici che aiutano la ricerca a sfuggire a scelte locali subottimali. Questa miscela di struttura e casualità controllata accelera la convergenza e riduce l’overfitting.
Quanto bene funziona il sistema nella pratica
I ricercatori testano la loro pipeline su un dataset sintetico ma realistico di 1.200 professionisti IT, costruito per rispecchiare i record dei sistemi di gestione dell’apprendimento reali con distribuzioni di classe deliberatamente diseguali. Confrontano il loro modello ChF2T‑ACLNet con diversi solidi baseline, inclusi setup di federated learning, reti avanzate in stile immagine adattate all’educazione e altri modelli deep o ensemble. Su molteplici configurazioni di cross‑validation, il metodo proposto raggiunge circa il 98,9% di accuratezza, con precisione, recall e F‑score altrettanto elevati. Ottiene anche un punteggio di accordo quasi perfetto che corregge per caso e fornisce forti valori di area sotto la curva, il che significa che separa i livelli di prestazione in modo affidabile su molte soglie. Nonostante la complessità, il sistema gira più velocemente delle soluzioni concorrenti, grazie alla selezione attenta delle feature, a un design di rete efficiente e alla rapida convergenza dell’ottimizzatore.
Cosa significa questo per l’apprendimento online di tutti i giorni
In termini semplici, questo lavoro mostra che è possibile osservare come i professionisti navigano i corsi online e inferire, con alta confidenza, chi sta faticando, chi procede a rilento e chi sta padroneggiando il materiale—senza aspettare un esame finale. Un sistema del genere potrebbe attivare suggerimenti precoci, raccomandare esercizi diversi o avvisare i mentori molto prima che un apprendente resti indietro. Gli autori segnalano sfide rimaste aperte, tra cui la scalabilità a piattaforme molto grandi, l’adattamento a design dei corsi in rapido cambiamento e la semplificazione delle spiegazioni delle decisioni del modello. Tuttavia, il loro approccio rappresenta un passo avanti verso sistemi di e‑learning che si comportano più come coach personali attenti che come testi digitali statici.
Citazione: Yuvapriya, P., Subramanian, P. & Surendran, R. Optimized attention-based cascaded shuffle long-term dependent network based performance analysis of adaptive e-learning among IT professionals. Sci Rep 16, 6245 (2026). https://doi.org/10.1038/s41598-026-36470-w
Parole chiave: apprendimento adattivo, learning analytics, deep learning, formazione professionisti IT, predizione delle prestazioni degli studenti