Clear Sky Science · it
Pochi esempi e memoria adattiva tra episodi per la segmentazione semantica dei difetti su superfici metalliche
Occhi più intelligenti per i pavimenti di fabbrica
Le fabbriche moderne fanno affidamento su telecamere per individuare piccoli graffi, crateri e macchie su pezzi metallici molto prima che arrivino ai clienti. Ma insegnare ai computer a riconoscere ogni possibile tipo di difetto richiede in genere grandi raccolte di immagini accuratamente annotate che molte aziende semplicemente non possiedono. Questo articolo presenta un nuovo modo di addestrare i sistemi di ispezione che possono imparare da pochissimi esempi, rendendo il controllo qualità automatizzato ad alta precisione più praticabile e conveniente.
Perché pochi esempi sono sufficienti
I sistemi tradizionali di rilevamento dei difetti funzionano al meglio quando hanno visto migliaia di immagini etichettate per ogni tipo di difetto. Questo è un problema nella produzione reale, dove i difetti rari possono comparire poche volte soltanto, e annotare le immagini pixel per pixel è lento e costoso. L’approccio studiato qui appartiene a un campo chiamato “segmentazione semantica few-shot”. In questo contesto, al sistema vengono fornite solo poche immagini di supporto etichettate che mostrano un particolare difetto, e deve poi evidenziare lo stesso tipo di difetto in una nuova immagine di query. Ciò è particolarmente impegnativo sulle superfici metalliche, dove illuminazione, texture e motivi di sfondo possono facilmente confondere un modello addestrato su dati limitati.
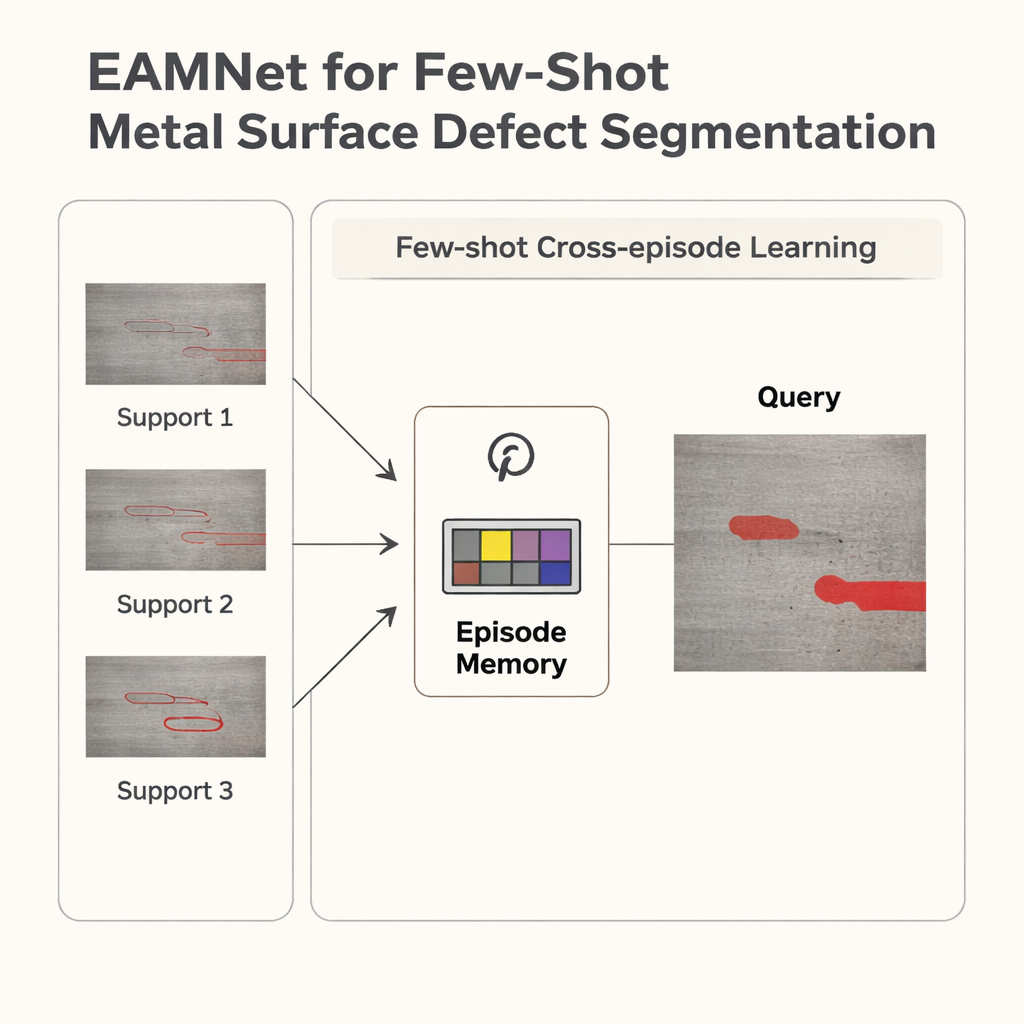
Imparare attraverso i compiti, non solo all’interno di uno
La maggior parte dei metodi few-shot precedenti tratta ogni compito di apprendimento, o “episodio”, in modo isolato: considerano le immagini di supporto e di query per un tipo di difetto, producono una previsione e poi passano oltre. Di conseguenza, tendono ad aggrapparsi a indizi superficiali come luminosità o texture locale invece di cogliere nozioni più profonde e riutilizzabili di cosa sia un difetto. Gli autori propongono una Episode Adaptive Memory Network (EAMNet) che fa l’opposto: ricordare. Un’unità di memoria dedicata traccia come le immagini di supporto e di query si relazionano attraverso molti episodi, distillando un “fattore adattivo” cross-task che guida il modello verso descrizioni più generali e stabili delle regioni difettose invece di sovradattarsi a un singolo compito alla volta.
Concentrarsi sui dettagli fini
Oltre a questa memoria tra episodi, EAMNet include componenti che affinano la capacità di cogliere dettagli sottili all’interno di ogni episodio. Un modulo di adattamento del contesto confronta caratteristiche più profonde delle immagini di supporto e di query per catturare come i pixel difettosi si differenziano dal metallo pulito sia nell’aspetto sia nell’intorno. Un secondo elemento, denominato global response mask average pooling, perfeziona il modo in cui il sistema sintetizza l’esempio di difetto di supporto, rendendo quel riassunto più sensibile ai segnali forti e affidabili e meno ai rumori di sfondo. Insieme, queste parti aiutano la rete a delineare forme di difetto precise invece che macchie approssimative, anche quando il difetto è piccolo o si fonde con l’ambiente circostante.
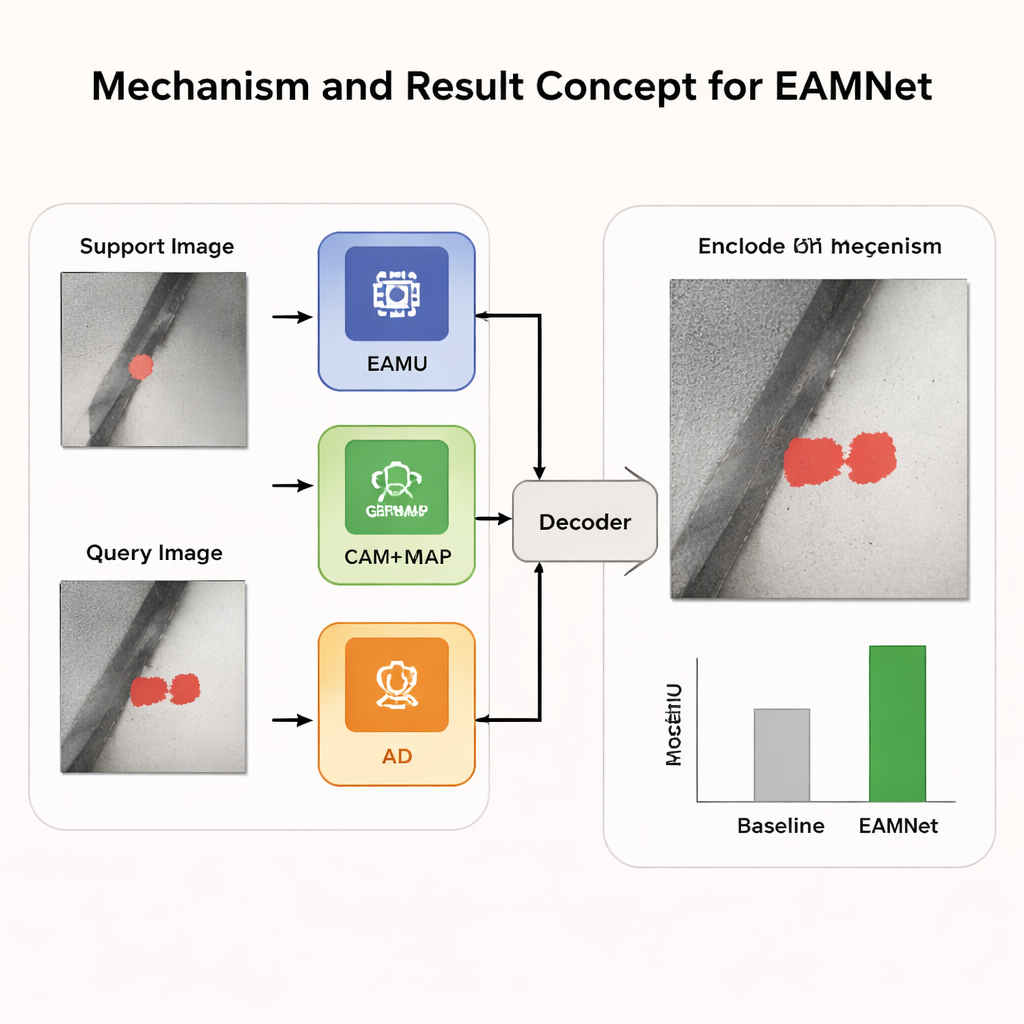
Insegnare alla rete a prestare maggiore attenzione
Addestrare una rete del genere da zero può essere instabile, perché i livelli iniziali tendono a produrre feature sfocate e di bassa qualità quando i dati scarseggiano. Per contrastare questo, gli autori introducono una fase di “distillazione dell’attenzione” durante l’addestramento. In termini semplici, mappe di attenzione di livello più alto e meglio focalizzate sono usate come segnali di insegnamento morbidi per le parti di livello inferiore della rete. Questo incoraggia l’intero sistema a concordare sulle regioni importanti, accelerando l’apprendimento e migliorando la capacità di adattarsi a nuovi tipi di difetti senza ulteriori aggiustamenti in fase di test.
Cosa significano i risultati per l’industria
I ricercatori testano EAMNet su due dataset di riferimento dei difetti su superfici metalliche—uno generale e uno focalizzato sull’acciaio a nastro—and lo confrontano con diversi metodi di punta. Su entrambi i dataset e con diversi backbone di rete, il loro modello raggiunge costantemente maggiore accuratezza, migliorando spesso le misure standard di qualità di oltre dieci punti percentuali rispetto a una solida baseline. Per un non esperto, questo significa un sistema di ispezione basato su telecamere che può apprendere rapidamente nuovi tipi di difetti da pochissimi campioni etichettati, pur segnando le aree difettose con precisione fine. In pratica, un tale sistema potrebbe ridurre l’ispezione manuale, rilevare guasti sottili prima e rendere il controllo qualità avanzato accessibile anche quando i dati etichettati sono scarsi.
Citazione: Zhang, J., Ding, H., Peng, M. et al. Few-shot cross-episode adaptive memory for metal surface defect semantic segmentation. Sci Rep 16, 5660 (2026). https://doi.org/10.1038/s41598-026-36445-x
Parole chiave: difetti delle superfici metalliche, few-shot learning, segmentazione semantica, ispezione industriale, computer vision