Clear Sky Science · it
Segmentazione della trombosi venosa profonda sensibile alla privacy usando un framework di apprendimento federato multi-modello con l'algoritmo di federated averaging
Perché i coaguli di sangue e la privacy dei dati sono importanti
I coaguli che si formano in profondità nelle vene delle gambe, noti come trombosi venosa profonda (TVP), possono viaggiare silenziosamente fino ai polmoni e causare emergenze potenzialmente letali. Le scansioni TC possono rivelare questi coaguli, ma trasformare migliaia di immagini in scala di grigi in rilevamenti automatici affidabili è un compito difficile per i computer. Allo stesso tempo, gli ospedali sono giustamente cauti nel condividere dati sensibili dei pazienti. Questo studio esplora come più ospedali possono collaborare per addestrare un potente sistema di intelligenza artificiale (IA) per individuare i coaguli—senza mai mettere in comune o esporre le loro scansioni raw dei pazienti.
Condividere cervelli, non corpi
Il fulcro del lavoro è una tecnica chiamata apprendimento federato, che permette a diverse istituzioni di addestrare modelli di IA in modo collaborativo mantenendo i dati in sede. Invece di inviare le immagini TC a un server centrale, ciascun ospedale addestra il proprio modello locale sulle proprie scansioni. Solo i parametri appresi del modello—essenzialmente ciò che ha "capito" sul riconoscimento dei coaguli—vengono inviati a un server centrale. Lì, un approccio chiamato federated averaging combina questi diversi insiemi di parametri in un unico modello globale migliorato, che viene poi rispedito a tutti gli ospedali. In questo modo, ogni sito beneficia dell'esperienza collettiva di tutti i partecipanti, mentre nessuna immagine del paziente lascia mai la sua istituzione d'origine. 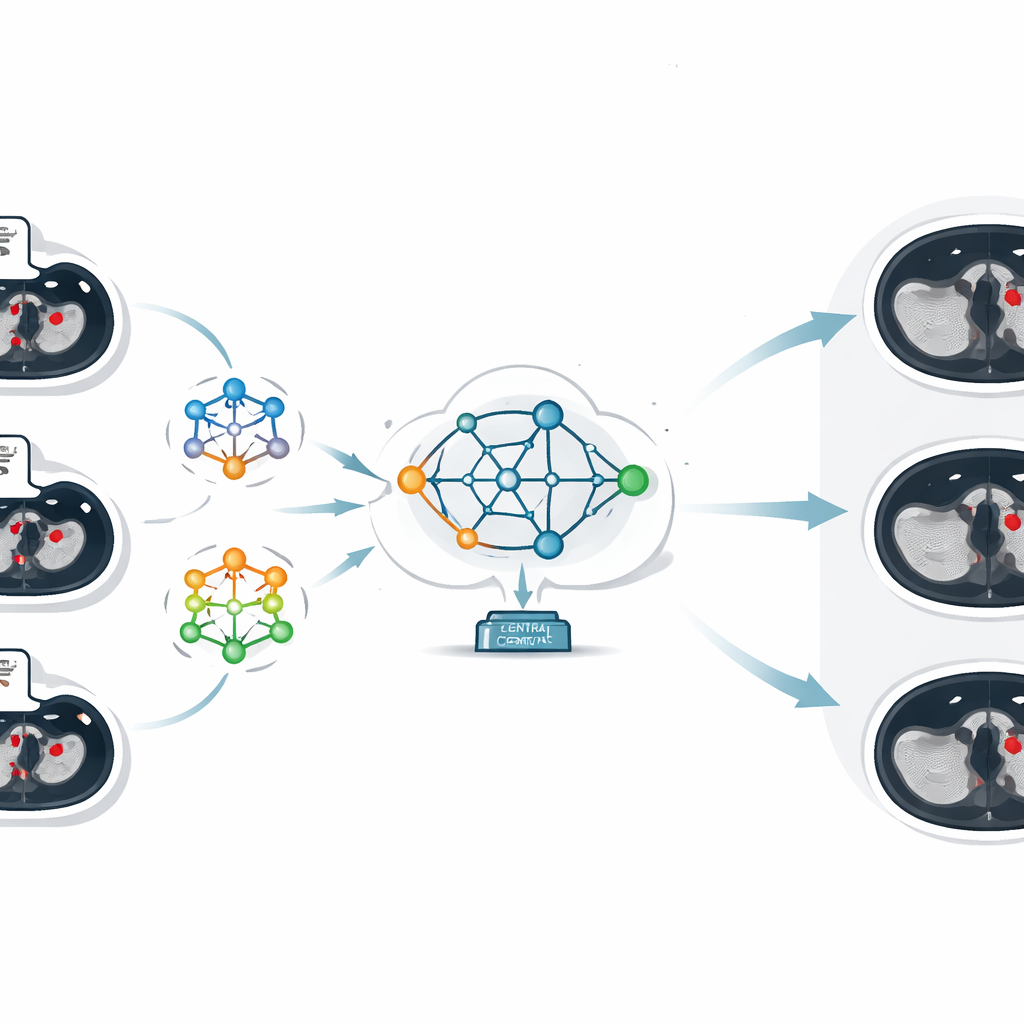
Molti tipi di IA che osservano le stesse vene
Un'innovazione chiave di questo studio è che i ricercatori non si sono affidati a un solo tipo di rete neurale. Hanno assemblato sette diversi design di modello, ognuno abile a cogliere aspetti diversi delle immagini TC. Modelli più semplici, come reti convoluzionali di base e modelli sequenziali, sono più veloci e facili da eseguire su hardware limitato. Architetture più avanzate, tra cui U‑Net, VGG‑19 e due reti personalizzate con blocchi residual, inception, attention e di elaborazione multi‑scala, sono migliori nel tracciare i confini fini dei vasi, individuare piccoli coaguli e gestire immagini rumorose. Consentendo a ogni ospedale di usare il modello che meglio si adatta ai propri dati e alla capacità di calcolo, il sistema rispecchia la realtà disomogenea degli ambienti clinici reali invece di presumere che ogni sito sia uguale.
Imparare da dati disomogenei e imperfetti
In medicina, i dati di un ospedale raramente somigliano esattamente a quelli di un altro. Scanner, protocolli di imaging e popolazioni di pazienti differiscono, quindi lo studio ha lavorato deliberatamente con dati "non‑IID"—collezioni che sono disomogenee e non distribuite in modo identico. Questo normalmente rende l'addestramento più instabile. Qui, gli autori hanno abbracciato quella diversità e hanno mostrato che mettere in comune le conoscenze attraverso più modelli strutturati in modo diverso in realtà ha migliorato la capacità del sistema globale di generalizzare. Hanno eseguito tre fasi sperimentali, prima con tre client, poi cinque e infine sette, usando dataset di 1.000, 2.000 e 3.000 immagini TC. Ad ogni passo hanno monitorato non solo quanto spesso il modello globale segmentava correttamente i coaguli, ma anche quanta comunicazione era necessaria, quanto tempo richiedeva l'addestramento, quanto erano diversi i dati di ciascun client e quanto efficaci fossero le protezioni della privacy.
Rilevamento dei coaguli migliore, a un costo computazionale
In tutte le fasi, il modello globale combinato ha costantemente superato qualsiasi singolo modello locale. All'aumentare del numero di immagini e con l'ingresso di modelli più sofisticati nella federazione, l'accuratezza di segmentazione è salita da circa il 91% a oltre il 96%, e una misura di qualità bilanciata chiamata F1‑score è passata da circa 0,89 a 0,95. Allo stesso tempo, una misura di perdita focalizzata sugli errori è scesa di più della metà, indicando contorni dei coaguli più puliti e affidabili. Questi miglioramenti non sono però gratuiti: la comunicazione tra client e server è aumentata da poche decine di megabyte a diversi gigabyte, e il tempo medio di addestramento è passato da secondi a molte ore man mano che l'architettura si è evoluta. Nonostante ciò, il sistema ha mantenuto una forte garanzia formale di privacy, indicando che gli aggiornamenti condivisi trapelano pochissime informazioni su ciascun paziente.
Cosa significa questo per pazienti e ospedali
Per un non esperto, il risultato principale è che questo lavoro dimostra come gli ospedali possano addestrare congiuntamente un'IA condivisa per individuare i pericolosi coaguli di sangue con maggiore accuratezza, senza cedere il controllo dei loro dati sensibili. Combinando diversi design di modello complementari e aggregando con cura ciò che ciascuno impara, gli autori costruiscono un sistema di segmentazione dei coaguli sia potente sia rispettoso della privacy. Sebbene l'approccio richieda risorse di calcolo e banda di rete considerevoli, indica una direzione verso un futuro in cui i centri medici collaborano di routine su strumenti diagnostici più intelligenti, migliorando la cura dei pazienti a rischio di TVP e condizioni correlate mantenendo le loro scansioni personali al sicuro dietro le mura istituzionali.
Citazione: B, P.L., S, V. Privacy-aware deep vein thrombosis segmentation using a multi-model federated learning framework with the federated averaging algorithm. Sci Rep 16, 11333 (2026). https://doi.org/10.1038/s41598-026-36432-2
Parole chiave: trombosi venosa profonda, apprendimento federato, segmentazione di immagini mediche, IA che preserva la privacy, imaging TC