Clear Sky Science · it
Un metodo di disambiguazione delle entità in testi brevi basato sul modello BERT e sull’algoritmo del percorso più breve
Perché è importante risolvere i nomi ambigui
Ogni giorno cerchiamo, scorriamo e chattiamo usando frammenti di testo brevi e spesso disordinati—tweet, query di ricerca, messaggi di chat. Questi frammenti sono pieni di nomi di persone, luoghi, aziende e oggetti che possono avere più significati, come “Apple” il frutto o “Apple” l’azienda. I computer devono indovinare quale significato intendiamo e, quando sbagliano, i risultati di ricerca, le raccomandazioni e i servizi online diventano molto meno utili. Questo articolo presenta un nuovo modo per aiutare le macchine a interpretare correttamente nomi ambigui in testi brevi, in particolare nei social media e nelle ricerche in cinese, combinando modelli linguistici moderni con un astuto algoritmo su grafi.
Da testi brevi e disordinati a obiettivi chiari
I testi brevi sono sorprendentemente difficili da comprendere per i computer. A differenza di lunghi articoli, contengono pochissimo contesto e sono pieni di gergo, abbreviazioni e frasi incomplete. I metodi tradizionali cercavano di far corrispondere un nome nel testo a voci di una base di conoscenza, oppure usavano regole manuali e modelli di apprendimento automatico più semplici. Questi approcci spesso trattano ogni parola come avente un significato unico e fisso, il che fallisce vistosamente quando la stessa parola può rappresentare un titolo professionale, un’azienda o una canzone, a seconda dell’uso. Il risultato è una confusione frequente su quale entità del mondo reale una parola in un tweet o in una query si riferisca effettivamente.
Insegnare al sistema a individuare nomi ambigui
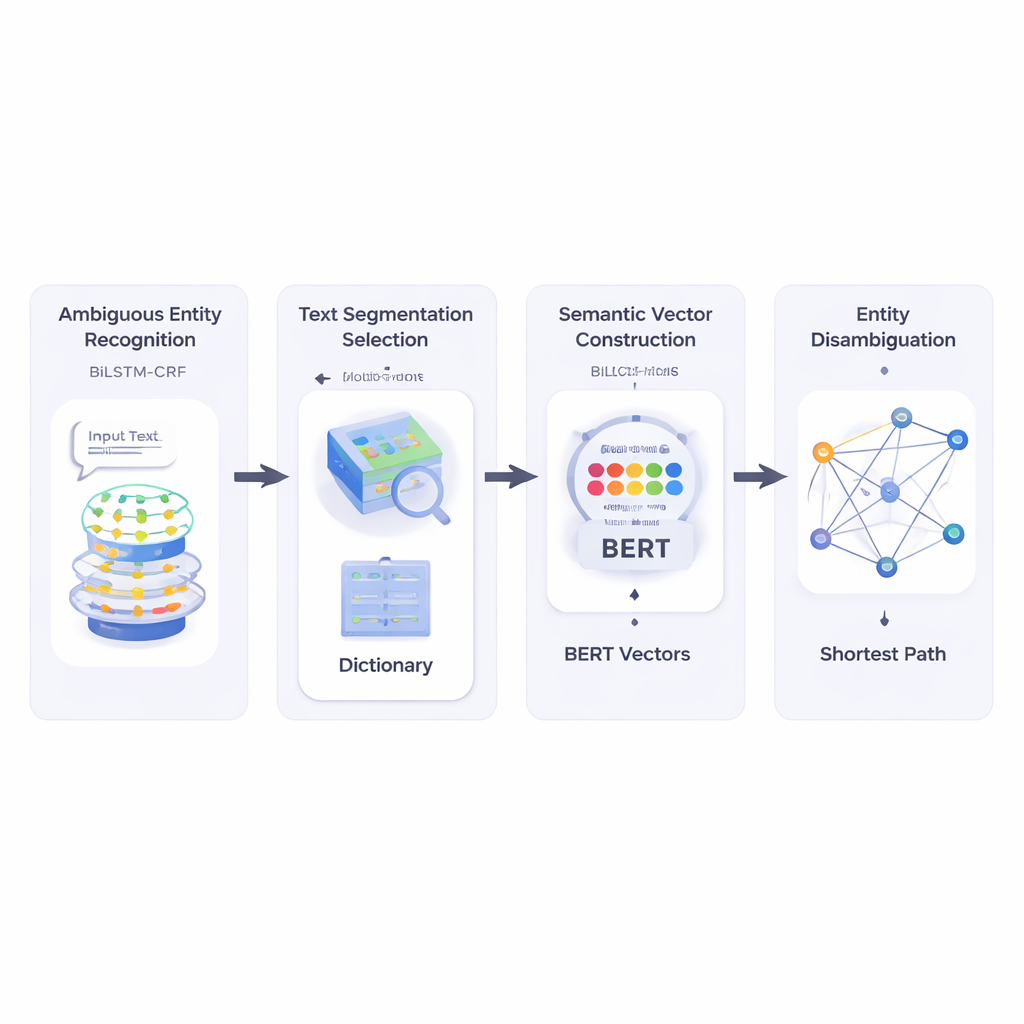
Gli autori costruiscono innanzitutto un sistema che legge un testo breve e identifica quali parti sono nomi di entità e quali di queste potrebbero essere ambigue. Usano una combinazione di reti neurali chiamata BiLSTM‑CRF, efficace nel marcare sequenze di parole guardando sia il contesto a sinistra sia a destra. Una volta segnate le potenziali entità, il sistema consulta una grande risorsa lessicale chiamata HowNet. Se HowNet elenca diversi significati per una parola, quella parola viene segnalata come ambigua; se c’è un solo significato, la parola è trattata come già chiara. Questo passaggio fornisce al sistema una lista mirata di nomi che richiedono davvero disambiguazione.
Trasformare i significati in punti nello spazio
Successivamente, il metodo suddivide il testo breve in segmenti di parole candidati e sceglie la migliore segmentazione verificando quanto ciascuna possibile divisione si allinei, in termini di significato, con parole di riferimento chiaramente comprese nella stessa frase. Per misurare questo, gli autori si affidano a BERT, un potente modello linguistico pre‑addestrato che produce un “vettore semantico” numerico per ogni occorrenza di una parola, catturandone il significato dipendente dal contesto. Calcolando la similitudine coseno tra questi vettori, il sistema trova la segmentazione i cui pezzi sono più semanticamente compatibili con i termini di riferimento non ambigui. Ciò consente al modello di rappresentare ogni possibile senso di ciascuna parola come un punto in uno spazio multidimensionale.
Trovare il percorso più breve verso il significato giusto
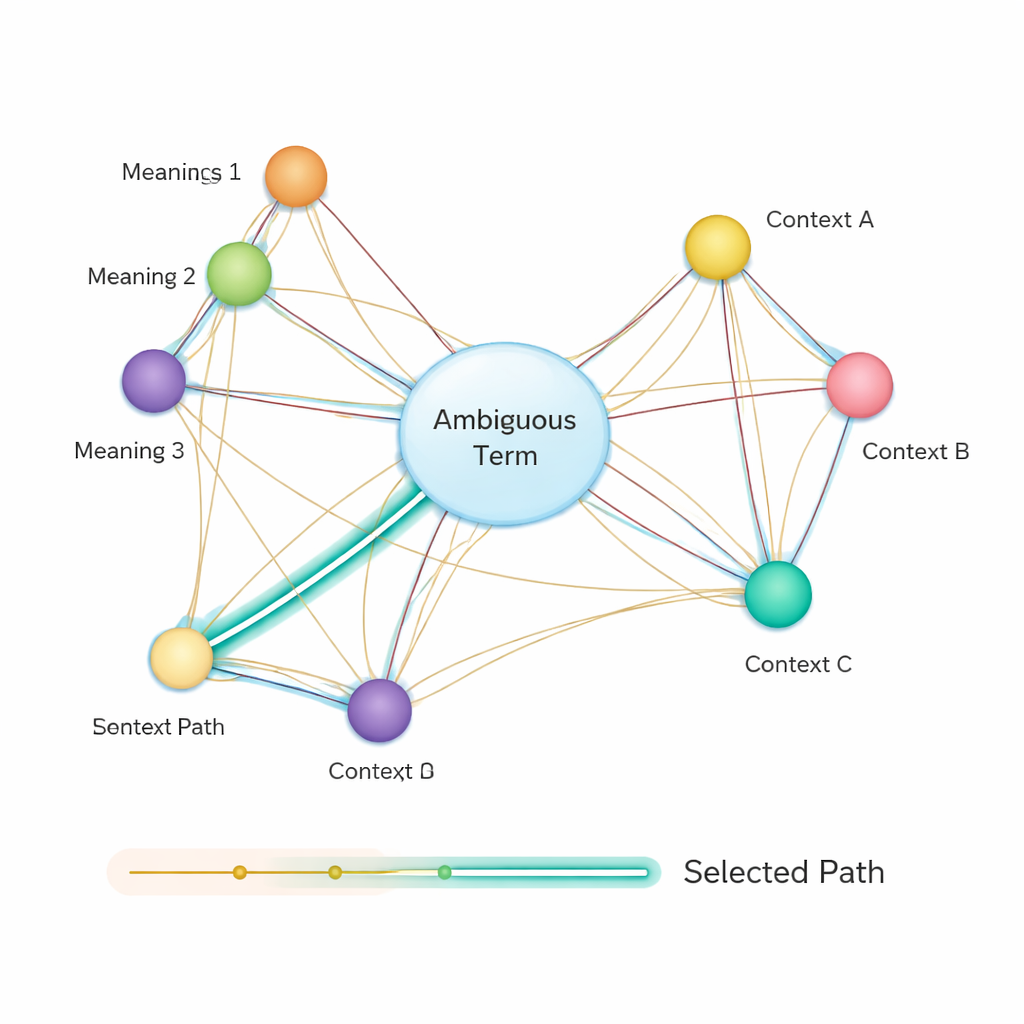
Dopo di che, il metodo costruisce una rete semantica: un grafo in cui ogni possibile significato di ciascun termine è un nodo, e gli archi collegano significati che potrebbero co‑occorre nella stessa frase. La forza di ogni arco si basa su quanto i significati siano simili, ancora una volta usando vettori basati su BERT. Per decidere quale senso di una parola ambigua si adatta meglio alla frase, gli autori applicano un algoritmo classico noto come algoritmo di Dijkstra per il percorso più breve. Intuitivamente, il sistema cerca il percorso attraverso questo grafo dei significati che mantiene la “distanza” semantica complessiva la più piccola possibile. Il percorso scelto corrisponde a un’interpretazione coerente di tutti i termini, e il senso dell’entità ambigua che giace su questo percorso viene selezionato come risposta finale.
Quanto migliora questo approccio?
I ricercatori hanno testato il loro metodo su un dataset pubblico cinese del benchmark CLUE, che simula scenari reali di testi brevi come post sui social e query. Hanno confrontato quattro approcci: versioni che usano embedding Word2Vec tradizionali, il modello linguistico ELMo, un sistema basato su BERT senza il passaggio del percorso più breve, e la loro pipeline completa BiLSTM‑CRF‑BERT‑SPA. Su migliaia di testi, il loro metodo completo ha migliorato accuratezza, richiamo e F1 di circa un quarto in media rispetto agli altri. In termini pratici, il sistema era sia più abile a individuare le entità corrette sia più coerente nel farlo su molte diverse dimensioni di dati.
Cosa significa questo per la tecnologia di tutti i giorni
Per i non specialisti, la conclusione è semplice: combinando un potente modello di comprensione del linguaggio (BERT) con una ricerca su grafo basata sul percorso più breve, gli autori forniscono ai computer un modo più affidabile per decidere a cosa si riferisce realmente un nome ambiguo in testi brevi e rumorosi. Questo può rendere i motori di ricerca più intelligenti, aiutare le piattaforme social a comprendere meglio i post e migliorare strumenti a valle come sistemi di raccomandazione e grafi di conoscenza. Sebbene il metodo sia attualmente orientato al cinese e abbia ancora margini di miglioramento in efficienza, dimostra come la fusione dell’IA moderna con algoritmi classici possa ridurre nettamente la confusione nell’interpretazione del nostro linguaggio quotidiano da parte delle macchine.
Citazione: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
Parole chiave: disambiguazione delle entità, testo breve, BERT, grafo di conoscenza, elaborazione del linguaggio naturale