Clear Sky Science · it
Framework di apprendimento per rinforzo per il testing adattivo computerizzato usando un approccio multi-armed bandit
Test più intelligenti per l’aula digitale
Chiunque abbia sostenuto un lungo esame uguale per tutti sa quanto possa risultare noioso e ingiusto. Alcune domande sono fin troppo semplici, altre impossibili, e il punteggio finale potrebbe non riflettere davvero ciò che si sa. Questo articolo presenta un nuovo modo di costruire test al computer che si adattano, in tempo reale, alle risposte di ciascuno. Prendendo in prestito idee dall’intelligenza artificiale moderna, gli autori puntano a rendere gli esami più brevi, più accurati e migliori nel rispecchiare la reale abilità di ogni candidato.
Perché i test fissi non bastano
Gli esami tradizionali propongono a tutti gli studenti lo stesso insieme di domande. Questo semplifica la costruzione del test, ma spreca informazioni: gli studenti più bravi si trascinano attraverso molte voci facili, mentre quelli in difficoltà vengono rapidamente sopraffatti. Il testing adattivo computerizzato cerca di correggere questo scegliendo ogni nuova domanda in base alle risposte precedenti, ma la maggior parte dei sistemi attuali si basa ancora su modelli statistici e regole artigianali di decenni fa. Questi approcci più datati faticano a catturare schemi di risposta complessi e spesso non riescono a tenere pienamente conto delle ampie differenze tra gli apprendenti negli ambienti online moderni e su larga scala.
Portare l’IA moderna nel testing
Gli autori propongono un nuovo framework che combina deep learning e apprendimento per rinforzo per guidare i test adattivi dall’inizio alla fine. Il sistema opera in cicli ripetuti. Prima, una rete neurale convoluzionale unidimensionale (1D-CNN) analizza le risposte recenti della persona, la difficoltà delle domande e altre statistiche riassuntive. Da questo flusso di dati produce un unico numero che rappresenta il livello di abilità corrente della persona su una scala normalizzata, simile a come le teorie tradizionali descrivono l’abilità ma appreso direttamente dai dati. Questa rete è addestrata a riconoscere schemi sottili, come successi costanti su domande più difficili o errori inattesi su quelle più semplici. 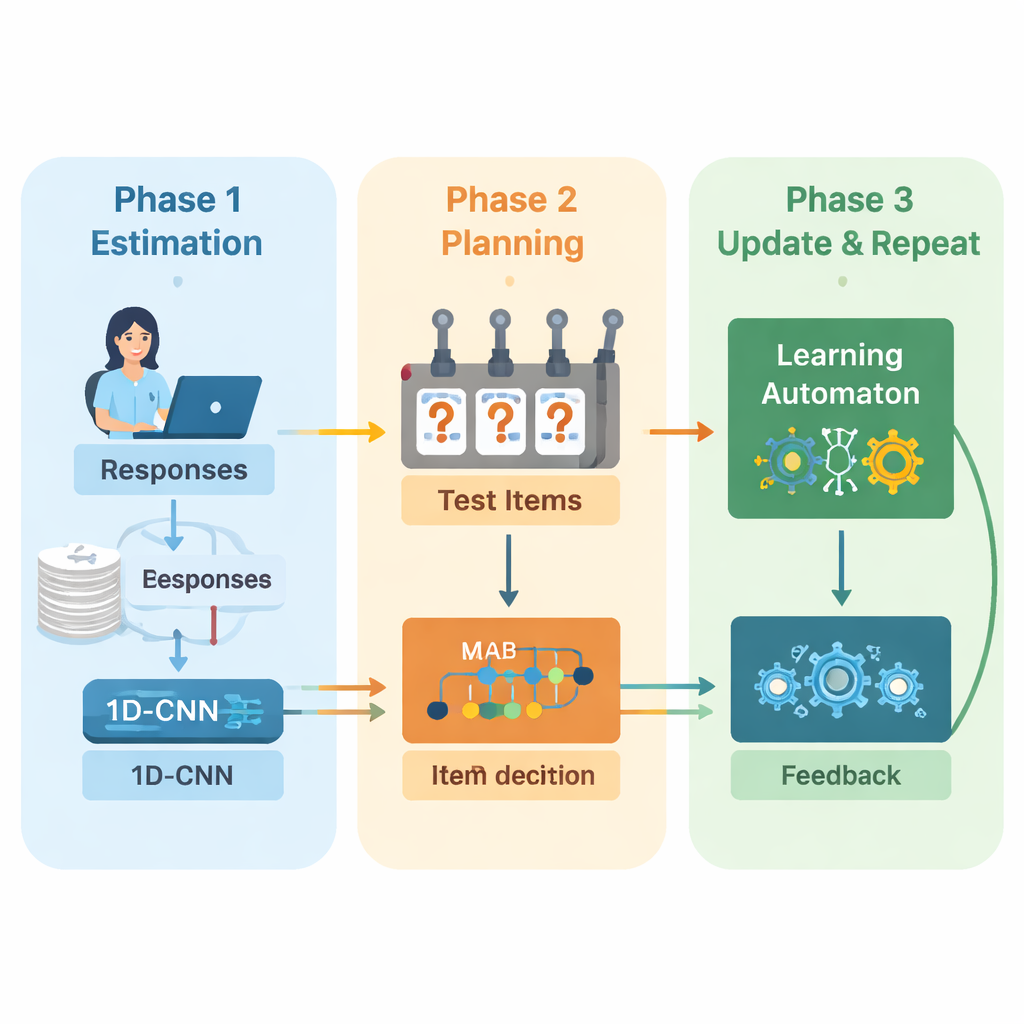
Scegliere la domanda giusta
Una volta che il sistema ha una stima aggiornata dell’abilità, deve decidere cosa chiedere dopo. Qui gli autori usano una strategia «multi-armed bandit», uno strumento classico della teoria delle decisioni in cui ogni azione possibile è trattata come la leva di una slot machine. In questo contesto, ogni domanda nella banca oggetti è un braccio. L’algoritmo esamina le domande la cui difficoltà corrisponde approssimativamente alla stima di abilità corrente e poi sceglie quelle che si prevede siano più informative. Equilibra due obiettivi: ottenere un buon abbinamento di difficoltà, così le risposte non sono né troppo facili né troppo difficili, e coprire il maggior numero possibile di aree di contenuto, così il test non ignora argomenti importanti. Un punteggio di ricompensa che mescola questi due obiettivi guida il processo di selezione.
Imparare dalle proprie decisioni
Per continuare a migliorare durante lo svolgimento del test, il sistema aggiunge un altro componente di apprendimento chiamato automa di apprendimento. Questo modulo osserva come la stima di abilità cambia tra i round e se la precisione della persona sta migliorando o peggiorando. Regola un piccolo insieme di probabilità che riassumono se il modello si aspetta che l’abilità aumenti, resti stabile o diminuisca. Queste probabilità vengono quindi reinserite come input aggiuntivo alla rete neurale nel round successivo. In questo modo il motore del test non solo impara sullo studente, ma impara anche sulle proprie decisioni passate—premiando tendenze che hanno portato a stime accurate e penalizzando quelle che non lo hanno fatto. 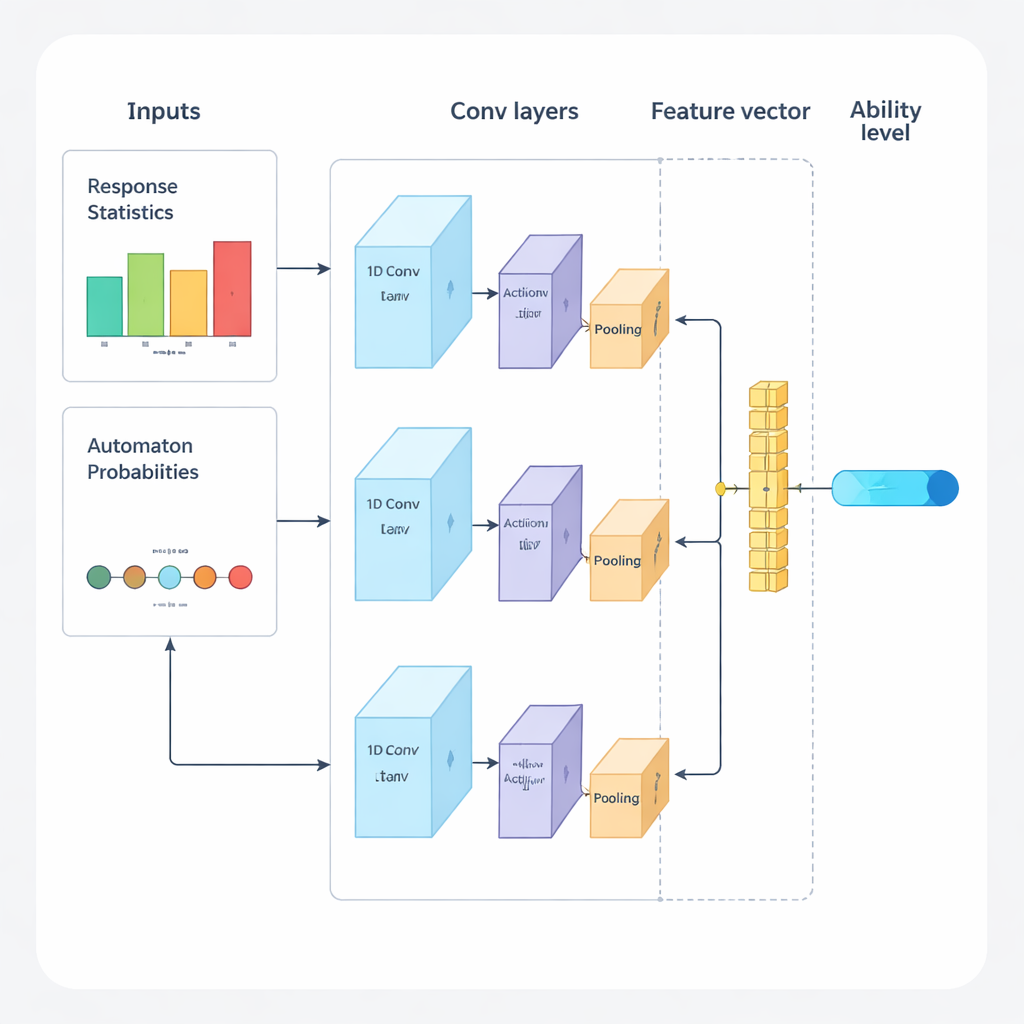
Quanto funziona nella pratica?
I ricercatori hanno valutato il loro framework usando un grande dataset di esami multilingue e migliaia di candidati simulati i cui veri livelli di abilità erano noti. Hanno confrontato il loro approccio con diversi metodi adattivi leader. Su una serie di misure di errore e correlazione, il nuovo sistema ha prodotto stime di abilità più accurate richiedendo nel contempo meno domande. I suoi errori—misurati con statistiche comuni come l’errore quadratico medio e l’errore assoluto medio—erano nettamente inferiori rispetto ai metodi concorrenti. Allo stesso tempo, ha distribuito l’uso delle domande in modo più uniforme attraverso la banca oggetti, riducendo il rischio che alcune domande fossero sovra-espresse e trapelate.
Cosa significa per gli esami futuri
In termini pratici, questo lavoro suggerisce che i futuri test al computer potrebbero somigliare più a una sessione di tutoraggio personalizzata che a un esame rigido. Le domande si concentrarebbero rapidamente sulla giusta difficoltà per ciascuna persona, esplorerebbero l’intera gamma di argomenti rilevanti e terminerebbero una volta che il sistema fosse sicuro del livello—spesso con meno voci rispetto ai test odierni. Pur dipendendo ancora da buoni dati di addestramento e potenza di calcolo, e pur essendo stato finora testato su un unico dataset, indica la strada verso una nuova generazione di valutazioni più intelligenti, più eque e più efficienti che si adattano naturalmente ai singoli apprendenti.
Citazione: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
Parole chiave: testing adattivo computerizzato, valutazione educativa, deep learning, apprendimento per rinforzo, multi-armed bandit