Clear Sky Science · it
Identificazione dei fattori di rischio per grandi impianti di divertimento tramite mixture of experts e fusione di più modelli
Perché la sicurezza dei parchi a tema ha bisogno di una lettura più intelligente
Ogni anno, centinaia di milioni di persone salgono su montagne russe, torri di caduta e giostre rotanti, confidando che macchine complesse e operatori indaffarati li tengano al sicuro. Dietro le quinte, autorità e ingegneri producono enormi quantità di rapporti, registri di incidenti e reclami pubblici—ma gran parte di queste informazioni è in forma testuale e difficile da vagliare rapidamente. Questo studio esplora come l’intelligenza artificiale avanzata possa “leggere” questi documenti su larga scala, individuare prima i segnali di pericolo e fornire alle autorità un quadro più chiaro di dove le attrazioni sono più a rischio di guasti.
Da rapporti sparsi a un quadro unificato del rischio
La Cina ospita oggi più di 25.000 grandi attrazioni e oltre 700 milioni di visitatori all’anno. Nonostante i miglioramenti generali nella sicurezza, continuano a verificarsi incidenti rari ma gravi, spesso dopo che le ispezioni non hanno rilevato segnali di allarme precoci sepolti nelle descrizioni tecniche o nelle segnalazioni degli utenti. Gli autori sostengono che la supervisione tradizionale—basata su controlli manuali periodici, giudizio degli esperti e registri di manutenzione—sia troppo lenta e soggettiva per un contesto in rapido movimento. Hanno quindi assemblato una grande raccolta testuale del mondo reale che include rapporti di incidente, leggi e standard, registri di ispezione e manutenzione e reclami online relativi alle strutture di divertimento. Dopo accurata pulizia e filtraggio, questo corpus multisorgente diventa la materia prima per un sistema automatizzato di monitoraggio del rischio basato sui dati. 
Insegnare ai computer a comprendere il linguaggio del rischio
Per dare senso a questi testi frammentati, i ricercatori fanno affidamento su modelli linguistici moderni che convertono le frasi in vettori numerici che catturano il loro significato. Usano principalmente un modello cinese chiamato BGE, che rappresenta ciascun testo come un punto in uno spazio a 1.024 dimensioni, più un insieme compatto di 30 caratteristiche basate su parole chiave incentrate su termini come “manutenzione”, “ispezione” e “rettifica”. Questa doppia prospettiva—contesto semantico profondo più frasi di rischio selezionate a mano—aiuta il sistema a distinguere differenze sottili tra, per esempio, controlli di routine e guasti gravi. Il team sperimenta anche un altro modello di embedding all’avanguardia, Qwen3, per verificare se cambiare la base linguistica migliori le prestazioni; in pratica, BGE si dimostra leggermente migliore per questo compito di sicurezza.
Trovare schemi nascosti e punti deboli chiave
Prima di classificare i testi in categorie di rischio concrete, gli autori utilizzano metodi non supervisionati per scoprire raggruppamenti naturali. Applicano il clustering k-means agli embedding e usano un metodo di visualizzazione chiamato UMAP per mostrare che i rapporti ricadono in diversi cluster tematici chiari. Quindi costruiscono un grafo semantico in cui ogni nodo è una parola chiave legata alla sicurezza e i collegamenti indicano forte co-occorrenza e somiglianza semantica. Un algoritmo di rilevamento delle comunità raggruppa questi nodi in cluster corrispondenti a temi ampi come sicurezza delle attrezzature e strutturale, operazioni e manutenzione quotidiana, risposta alle emergenze e gestione e supervisione. All’interno di questa rete, alcune parole—come “manutenzione”, “ispezione” e “responsabilità”—agiscono da ponti tra i cluster, mettendo in luce debolezze trasversali che possono innescare incidenti in modi diversi. Da questa struttura estraggono 31 fattori di rischio principali che coprono quattro dimensioni principali, dal monitoraggio in tempo reale delle attrezzature alla chiarezza delle responsabilità lavorative. 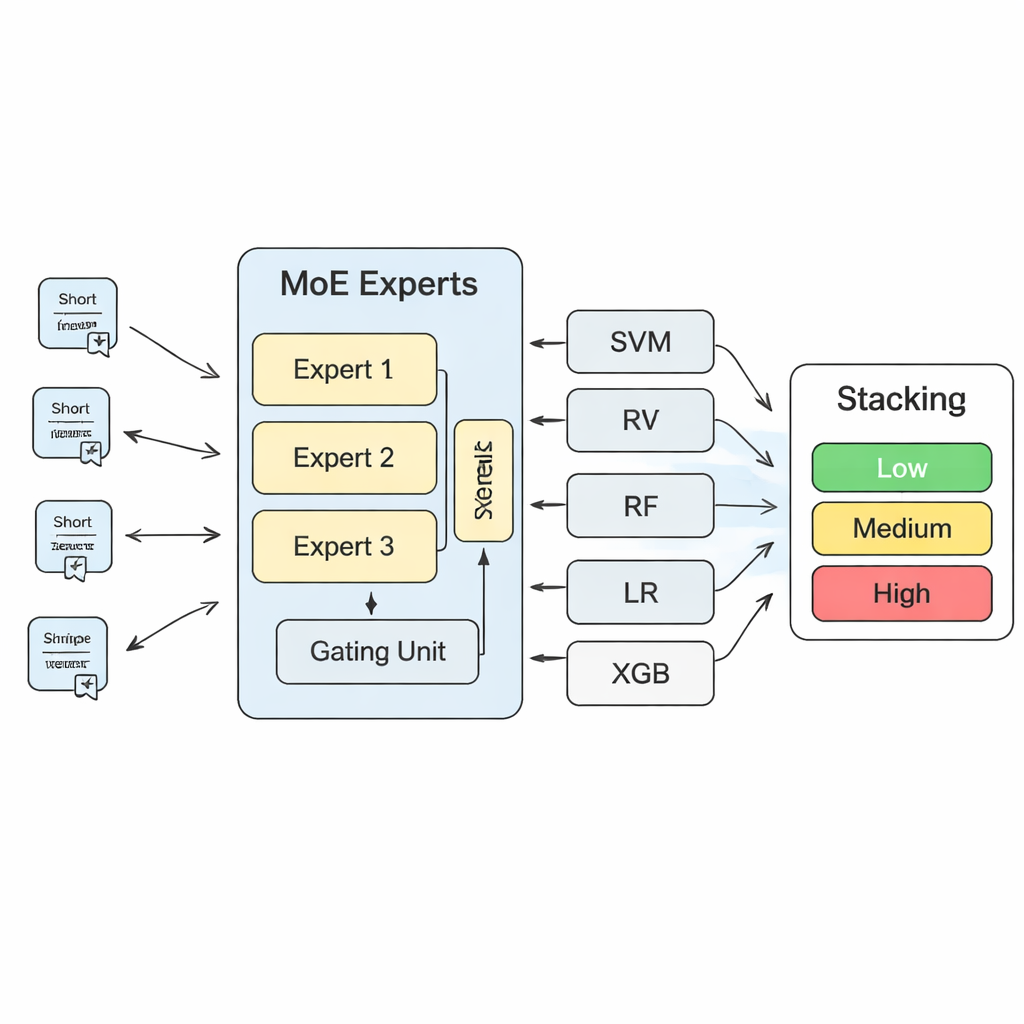
Fondere molti modelli in un giudice della sicurezza più robusto
Per trasformare queste intuizioni in predizioni di rischio concrete, lo studio costruisce un sistema a strati di apprendimento automatico. Al centro c’è un modello “mixture of experts” (MoE): diverse reti neurali, o esperti, imparano ciascuna a specializzarsi in diversi tipi di pattern di rischio, mentre un componente di gating decide quali esperti fidarsi di più per ogni nuovo testo. Le uscite di questo modello MoE vengono poi combinate con le predizioni di algoritmi più tradizionali, come support vector machines, random forest, regressione logistica e gradient-boosted trees. Uno strato finale di “Stacking”—un altro modello di apprendimento automatico—impara a pesare tutte queste opinioni per arrivare a una decisione finale. Attraverso una estesa cross-validazione, gli autori constatano che usare tre esperti nello strato MoE offre il miglior compromesso tra capacità del modello e stabilità.
Cosa significano i miglioramenti per la supervisione nel mondo reale
Rispetto a qualsiasi singolo modello, il sistema MoE più Stacking migliora sostanzialmente accuratezza, precisione, richiamo e una misura di affidabilità chiamata LogLoss. In termini pratici, ciò si traduce in meno avvisi mancati e meno falsi allarmi quando si analizzano grandi volumi di testo sulla sicurezza. Il modello può girare su una workstation ordinaria e fornire valutazioni di rischio rapide per nuovi rapporti di ispezione o reclami, rendendolo adatto come strumento di supporto alle decisioni piuttosto che come sostituto del giudizio umano. Gli autori sottolineano che il loro approccio potrebbe essere adattato oltre le attrazioni aeree ad altre attrezzature speciali come ascensori o funivie. Per i lettori non specialisti, la conclusione chiave è che insegnando ai computer a leggere il linguaggio della sicurezza—attraverso documenti tecnici, regolamenti e reclami quotidiani—le autorità possono rilevare prima i pattern di pericolo, mirare le ispezioni in modo più intelligente e rendere una giornata al parco un po’ più sicura per tutti.
Citazione: Hao, S., Xing, L. & Zhang, M. Risk factor identification for large scale amusement facilities using mixture of experts and fusion of multiple models. Sci Rep 16, 6804 (2026). https://doi.org/10.1038/s41598-026-36377-6
Parole chiave: sicurezza delle attrazioni, analisi testuale del rischio, apprendimento automatico, mixture of experts, monitoraggio della sicurezza pubblica