Clear Sky Science · it
Apprendimento di gruppo nei sistemi di raccomandazione: verso una modellazione di gruppo adattiva e implicita
Perché i gruppi più intelligenti contano online
Dalle serate cinema tra amici alle vacanze in famiglia, molte delle nostre scelte vengono prese in gruppo. Eppure la maggior parte delle piattaforme online pensa ancora in termini di individui. Questo articolo pone una domanda semplice ma di grande portata: cosa succederebbe se i nostri servizi di streaming, le app di shopping e i portali di viaggio potessero scoprire e adattarsi in modo discreto a gruppi naturali di persone e oggetti da soli, invece di affidarsi a liste di gruppo fisse e create a mano? Gli autori propongono un nuovo modo per i sistemi di raccomandazione di apprendere automaticamente questi gruppi, al fine di produrre suggerimenti che risultino equi e soddisfacenti per tutti i partecipanti.
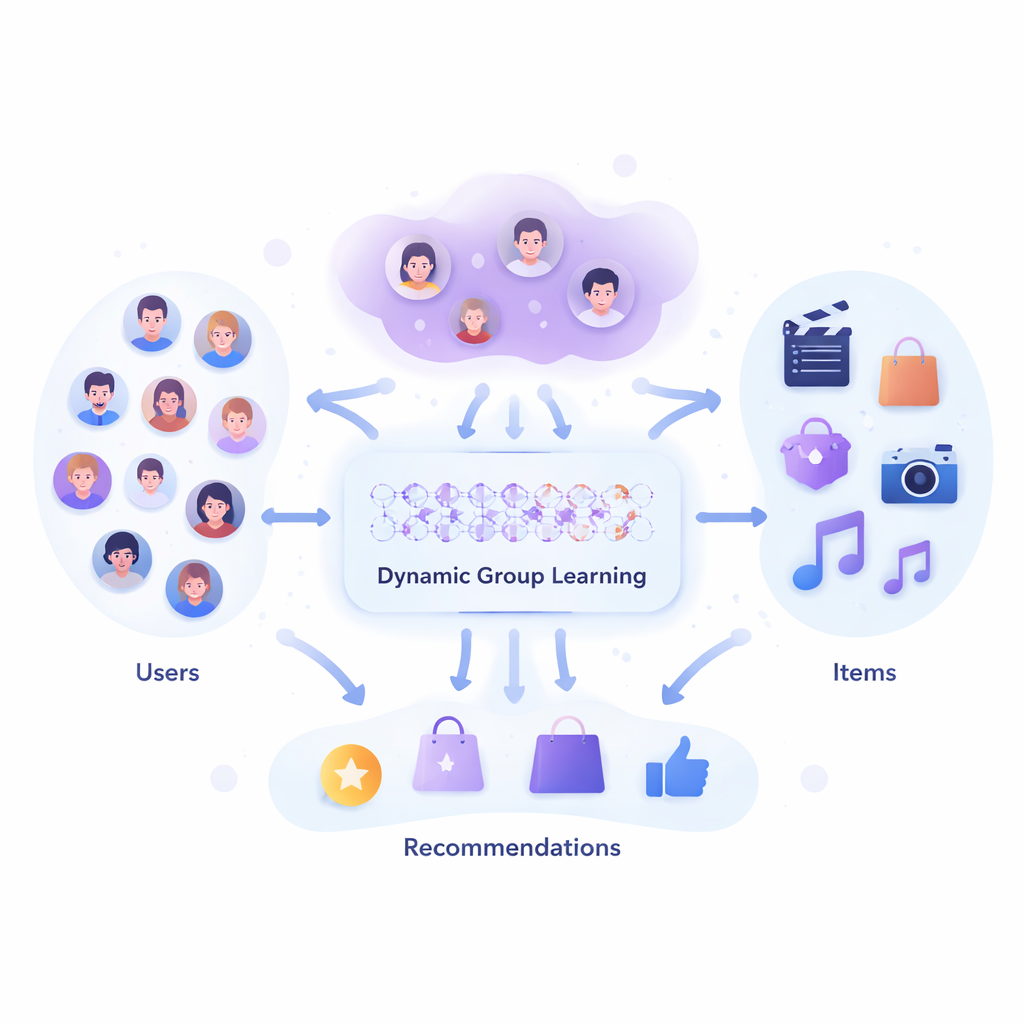
Da team fissi a folle flessibili
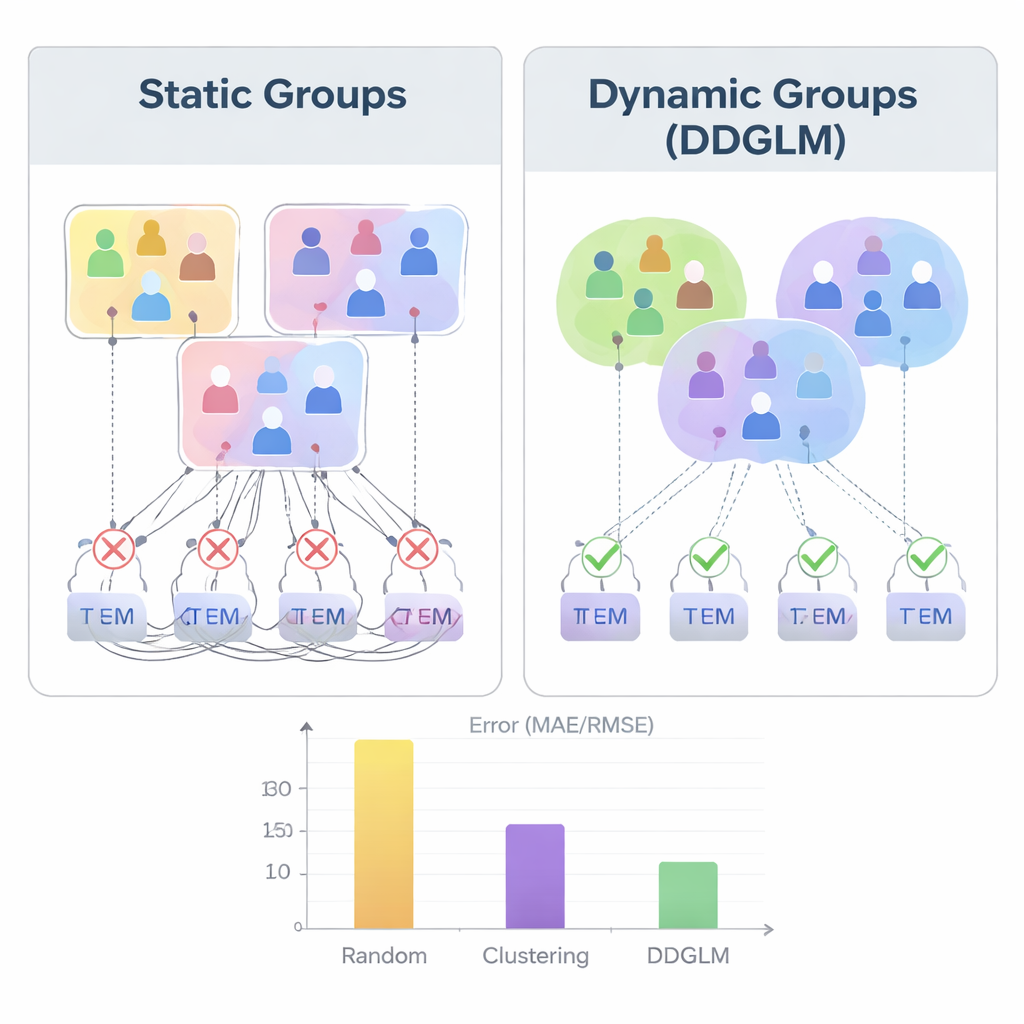
Gli strumenti odierni per le raccomandazioni di gruppo solitamente partono da un’idea rigida di chi stia insieme: un cerchio prefissato di amici, una classe, o cluster costruiti una tantum con uno strumento statistico. Il sistema quindi cerca un elemento “abbastanza buono” per quel gruppo congelato. Ma la vita reale è più disordinata. Il gruppo di persone che sceglie un film stasera può essere diverso da quello che pianifica una vacanza il mese prossimo, e gli stessi oggetti possono raggrupparsi naturalmente in pacchetti, come playlist o pacchetti viaggio. L’articolo sostiene che, invece di trattare la formazione dei gruppi come un passo separato e una tantum, questa dovrebbe essere integrata nel cuore di come il raccomandatore apprende dai dati.
Una mappa nascosta di persone e cose
Gli autori introducono un modello che chiamano Deep Dynamic Group Learning Model, o DDGLM. Al centro, il sistema costruisce una mappa nascosta in cui sia le persone sia gli oggetti sono rappresentati come punti in uno spazio matematico. Piuttosto che assegnare ogni persona o prodotto a un singolo gruppo fisso, il modello permette inizialmente loro di appartenere a diversi gruppi “soft” sovrapposti con gradi di appartenenza differenti. Un meccanismo di temperatura affina queste appartenenze man mano che l’apprendimento procede, così che quando il sistema viene impiegato nella pratica, ogni persona o oggetto risulti effettivamente collocato nel gruppo che meglio si adatta al compito. Questi gruppi appresi non si basano solo su tratti visibili come età o genere, ma su quanto aiutano il sistema a prevedere le valutazioni o le scelte che gli utenti effettivamente fanno.
Armonizzare individui e gruppi
DDGLM fa un passo ulteriore insistendo sul fatto che la rappresentazione di una persona come individuo e quella della stessa persona come membro di un gruppo devono concordare. Aggiunge un termine extra al processo di apprendimento che avvicina delicatamente le rappresentazioni individuali e di gruppo. Questo evita che i profili di gruppo deraghino in pattern irrealistici che nessun membro rappresenta realmente, pur permettendo al modello di catturare gusti condivisi. Utilizzando queste rappresentazioni, il sistema può gestire quattro situazioni comuni in modo unificato: raccomandare un singolo elemento a una persona, un elemento a un gruppo, un pacchetto di elementi a una persona, o un pacchetto a un gruppo. In ogni caso, le raccomandazioni si riducono a semplici confronti tra le persone e i gruppi di oggetti rilevanti all’interno della mappa nascosta.
Le categorie adattive aiutano davvero?
Per verificare l’efficacia dell’idea, gli autori hanno condotto esperimenti estesi su collezioni di valutazioni di film note come MovieLens-100K e MovieLens-1M. Hanno confrontato DDGLM con metodi che formano gruppi in modo casuale, tramite clustering tradizionale, o attraverso precedenti framework unificati di raccomandazione. In tutti e quattro gli scenari—individuale, di gruppo, pacchetto e pacchetto-a-gruppo—il modello dinamico ha prodotto previsioni di valutazione più accurate e suggerimenti migliori in cima alle classifiche. Si è mostrato particolarmente efficace quando erano coinvolti gruppi o pacchetti, dove gli approcci statici faticavano. Test statistici accurati hanno confermato che questi miglioramenti non sono dovuti al caso, e esperimenti di scalabilità hanno mostrato che il metodo cresce bene con l’aumentare del numero di utenti, oggetti e gruppi.
Cosa significa per gli utenti di tutti i giorni
Per i non specialisti, la conclusione è semplice: i sistemi di raccomandazione funzionano meglio quando possono scoprire raggruppamenti utili al volo, invece di essere vincolati a definizioni di gruppo rigide scelte a priori. Imparando quali persone e oggetti si muovono naturalmente insieme nei dati—e aggiornando costantemente questi pattern—DDGLM può generare suggerimenti che rispecchiano meglio i gusti condivisi, che si tratti di un film per una famiglia, di una playlist per una festa o di un pacchetto vacanze per un gruppo turistico. Lo studio mostra che trattare la formazione dei gruppi come qualcosa che il sistema può apprendere porta a raccomandazioni più precise, adattabili e potenzialmente più eque nei servizi digitali che usiamo ogni giorno.
Citazione: Busireddy, N.R., Kagita, V.R. & Kumar, V. Group learning in recommendation systems: towards adaptive and implicit group modeling. Sci Rep 16, 5918 (2026). https://doi.org/10.1038/s41598-026-36356-x
Parole chiave: sistemi di raccomandazione per gruppi, apprendimento dinamico di gruppi, raccomandazioni personalizzate, filtraggio collaborativo, deep learning