Clear Sky Science · it
Rete neurale profonda Inception con connessioni residuali per il riconoscimento dei caratteri scritti a mano in tamil
Salvare la scrittura a mano nell’era digitale
Dai vecchi manoscritti su foglie di palma alle note quotidiane, gran parte del patrimonio scritto in tamil vive ancora su carta. Trasformare questa ricca raccolta di pagine manoscritte in testo digitale ricercabile è essenziale per preservare la cultura, sostenere l’istruzione e costruire migliori tecnologie linguistiche. Questo articolo presenta un nuovo sistema di visione artificiale, chiamato TamHNet, che legge la scrittura tamil con precisione quasi perfetta, anche quando le lettere appaiono molto simili tra loro.
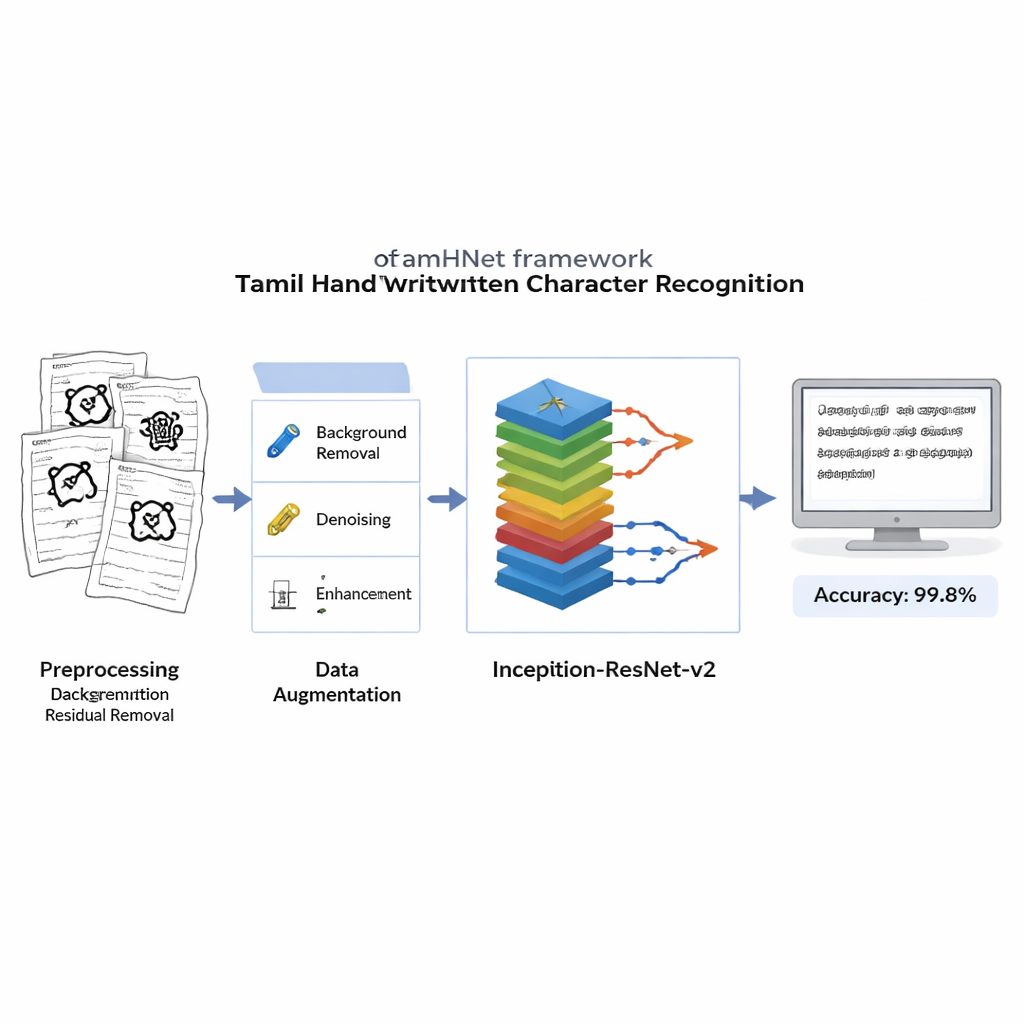
Perché le lettere tamil sono difficili per i computer
Il tamil è parlato da oltre 80 milioni di persone e usa un sistema di scrittura con 247 caratteri, comprensivo di vocali, consonanti e molte combinazioni. Molte lettere differiscono solo per piccole curve o tratti aggiuntivi, e gli autori variano molto nel modo di formare ciascun carattere. Coppie come எ/ஏ o ஒ/ஓ possono sembrare quasi identiche a colpo d’occhio, e caratteri come ல e வ possono essere facilmente confusi. I programmi informatici precedenti e persino molti sistemi di apprendimento automatico moderni spesso faticavano con queste sottigliezze, portando a parole errate e a una digitalizzazione inaffidabile dei documenti.
Costruire un dataset di scrittura reale
Per addestrare e testare il sistema in condizioni realistiche, i ricercatori hanno creato un nuovo Tamil Isolated Character Dataset usando campioni manoscritti provenienti da 1.000 studenti universitari. Invece di affidarsi a immagini sintetiche o generate al computer, hanno raccolto caratteri reali tracciati su carta che coprono 12 vocali, 18 consonanti e 214 combinazioni comuni. Il team ha etichettato con cura questi campioni e ha reso il dataset pubblicamente disponibile in modo che altri gruppi possano confrontare i metodi e sviluppare ulteriormente il lavoro. Organizzando lo script in 104 simboli base che rappresentano tutti i 247 caratteri, hanno ridotto la ridondanza pur mantenendo la rappresentazione dell’intera gamma di forme che appaiono nella scrittura reale.
Pulire, deformare e insegnare alle immagini
Prima di qualsiasi apprendimento, ogni immagine scannerizzata viene pulita per rimuovere sfondi rumorosi, macchie e illuminazione irregolare, preservando però i tratti delicati che definiscono ogni lettera. Le immagini sono convertite in nitidi bianco e nero e ridimensionate a un formato standard in modo che il computer veda ogni esempio nello stesso modo. Per rendere il sistema robusto alle diverse abitudini di scrittura, gli autori usano quindi distorsioni controllate: spostano leggermente punti chiave nell’immagine e applicano deformazioni morbide, generando nuove versioni di ciascun carattere che agli occhi umani appaiono ancora come la stessa lettera. Questo set di addestramento ampliato aiuta il modello a riconoscere i caratteri anche quando sono inclinati, compressi o scritti con proporzioni insolite.
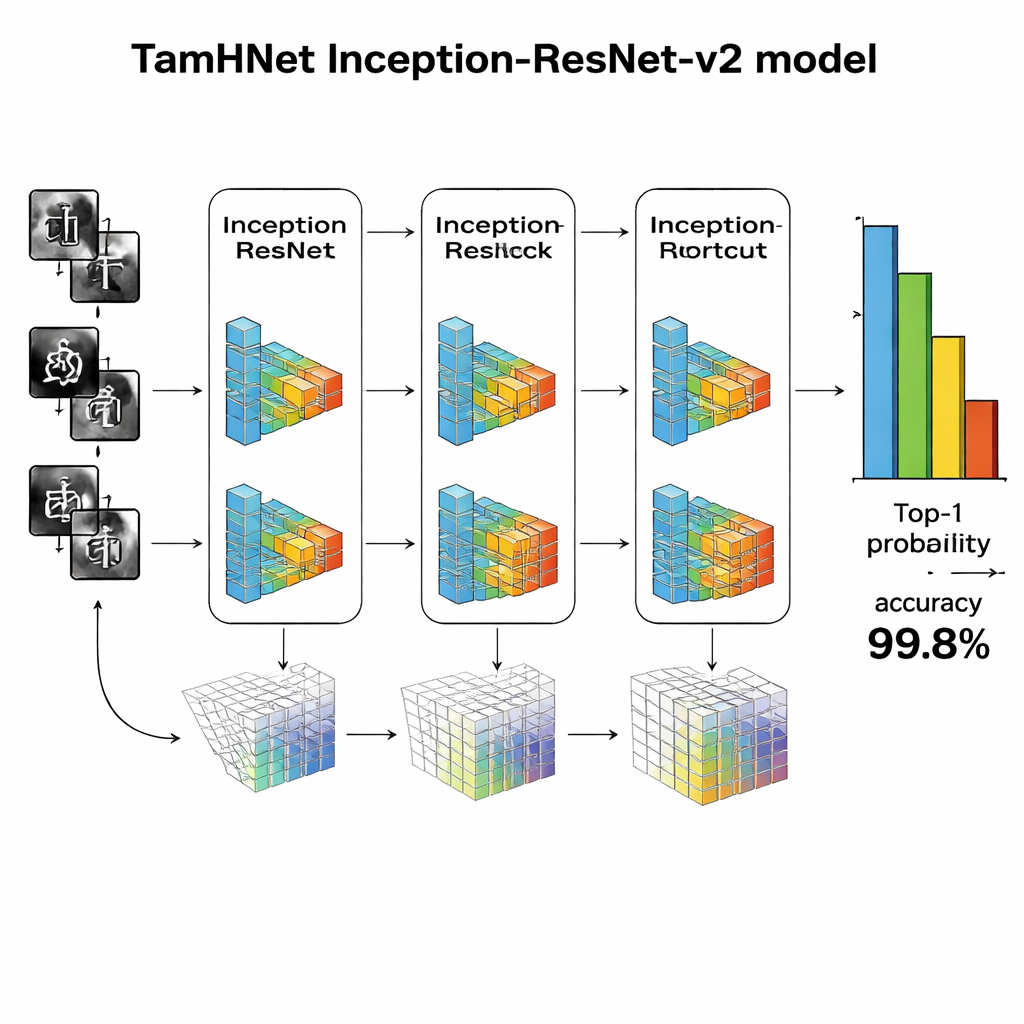
Una rete profonda che apprende le differenze sottili
Al centro di TamHNet c’è una potente architettura di deep learning chiamata Inception-ResNet-v2, originariamente progettata per il riconoscimento generale di oggetti. Gli autori adattano e affinano questa rete specificamente per la scrittura tamil. Il modello elabora ogni immagine attraverso molti strati che trasformano gradualmente i pixel grezzi in pattern di livello superiore, come bordi, curve e parti di caratteri. Connessioni speciali a percorso breve, note come link residuali, stabilizzano l’addestramento e aiutano la rete a concentrarsi sulle piccole ma cruciali differenze tra lettere simili. Invece di modificare tutte le impostazioni interne in una volta, il team “scongela” selettivamente gli strati più utili e li ottimizza per questo compito. Usano una tecnica di ottimizzazione chiamata Adam, che adatta automaticamente la velocità di aggiornamento di ciascun parametro, permettendo alla rete di apprendere in modo efficiente da una scrittura complessa e talvolta disordinata.
Quanto bene il sistema legge la scrittura
I ricercatori valutano TamHNet sul nuovo dataset usando misure standard di qualità del riconoscimento. Il sistema raggiunge circa il 99,8% di accuratezza su 104 classi di caratteri, superando una vasta gamma di metodi precedenti basati su macchine a vettori di supporto, reti convoluzionali tradizionali e altri progetti avanzati di deep learning. Test dettagliati mostrano che anche lettere con forme estremamente simili vengono nella maggior parte dei casi correttamente distinte, e curve statistiche confermano che il modello raramente confonde un carattere con un altro. Rispetto al lavoro precedente, questo rappresenta un chiaro passo avanti nell’affidabilità del riconoscimento dei caratteri manoscritti in tamil.
Cosa significa per lettori e archivi
Per i non specialisti, la conclusione principale è che i computer stanno diventando drasticamente più bravi a leggere la scrittura tamil. Un sistema come TamHNet può alimentare strumenti che trasformano pile di quaderni, manoscritti storici e moduli scritti a mano in testo digitale ricercabile con correzioni umane minime. Sebbene il modello attuale non gestisca ancora alcuni simboli a punti e varianti di scrittura più antiche, gli autori delineano piani per estenderlo anche agli stili di scrittura antichi. In termini pratici, questa ricerca ci avvicina a una digitalizzazione su larga scala e accurata dei documenti tamil, aiutando a salvaguardare il patrimonio culturale e rendendo la conoscenza scritta più accessibile per le generazioni future.
Citazione: Periyasamy, H., Natarajan, S. & Amirtharajan, R. Deep inception neural network with residual connections for Tamil handwritten character recognition. Sci Rep 16, 6053 (2026). https://doi.org/10.1038/s41598-026-36330-7
Parole chiave: riconoscimento dei caratteri scritti a mano in tamil, riconoscimento ottico dei caratteri, apprendimento profondo, Inception-ResNet, conservazione digitale