Clear Sky Science · it
Confronto delle prestazioni di grandi modelli linguistici nella valutazione delle conoscenze sulla terapia di cattura neutronica del boro
Tutor intelligenti per un nuovo tipo di radioterapia oncologica
La terapia di cattura neutronica del boro, o BNCT, è una forma emergente di trattamento radioterapico che mira a distruggere i tumori risparmiando i tessuti sani circostanti. Mentre questa terapia complessa si trasferisce dai laboratori di ricerca agli ospedali, medici e tirocinanti devono padroneggiare una grande quantità di conoscenze specializzate. Questo studio pone una domanda di grande attualità: gli attuali chatbot di intelligenza artificiale possono aiutare a insegnare e supportare la BNCT e, in tal caso, quanto sono affidabili?
Che cosa rende la BNCT diversa dalla radioterapia tradizionale?
La BNCT funziona in modo molto diverso rispetto ai trattamenti standard a raggi X o protoni. I pazienti ricevono farmaci contenenti una forma speciale di boro che si accumula all’interno delle cellule tumorali. Quando queste cellule vengono poi esposte a un fascio di neutroni, gli atomi di boro subiscono una piccola reazione nucleare che rilascia particelle a corto raggio, uccidendo la cellula tumorale dall’interno e lasciando in gran parte indenni i tessuti vicini. Questo approccio altamente mirato è particolarmente promettente per i tumori difficili da trattare o poveri di ossigeno. Fino a poco tempo fa la BNCT dipendeva dai reattori nucleari come sorgenti di neutroni, limitandone l’uso clinico. L’approvazione di macchine BNCT basate su acceleratori in Giappone nel 2020 e l’apertura di nuovi centri in paesi come la Cina hanno reso la BNCT un’opzione realistica per più pazienti—e hanno creato un’urgenza di formazione e certificazione mirate.
Mettere alla prova quattro intelligenze artificiali di punta
Per verificare quanto bene i chatbot di uso generale gestiscono i temi BNCT, i ricercatori hanno costruito un test di 47 domande che copriva concetti di base, ricerche recenti, pratica clinica e compiti di calcolo e ragionamento. Le domande sono state redatte in cinese e in inglese e includevano fatti semplici (come definizioni) e problemi più impegnativi che richiedevano logica o lavoro numerico. Quattro famiglie principali di IA—rappresentate da sistemi ampiamente usati di diverse aziende—sono state testate ciascuna in cinque diverse finestre temporali, in due lingue e con due modalità di domanda (domande dirette e domande inserite in un breve scenario clinico). Specialisti umani in cure oncologiche hanno valutato ogni risposta rispetto a una chiave standard, e il gruppo ha anche monitorato quanto spesso le IA ammettessero incertezza dicendo cose come “Non lo so”.
Chi ha risposto meglio e su quali tipi di domande?
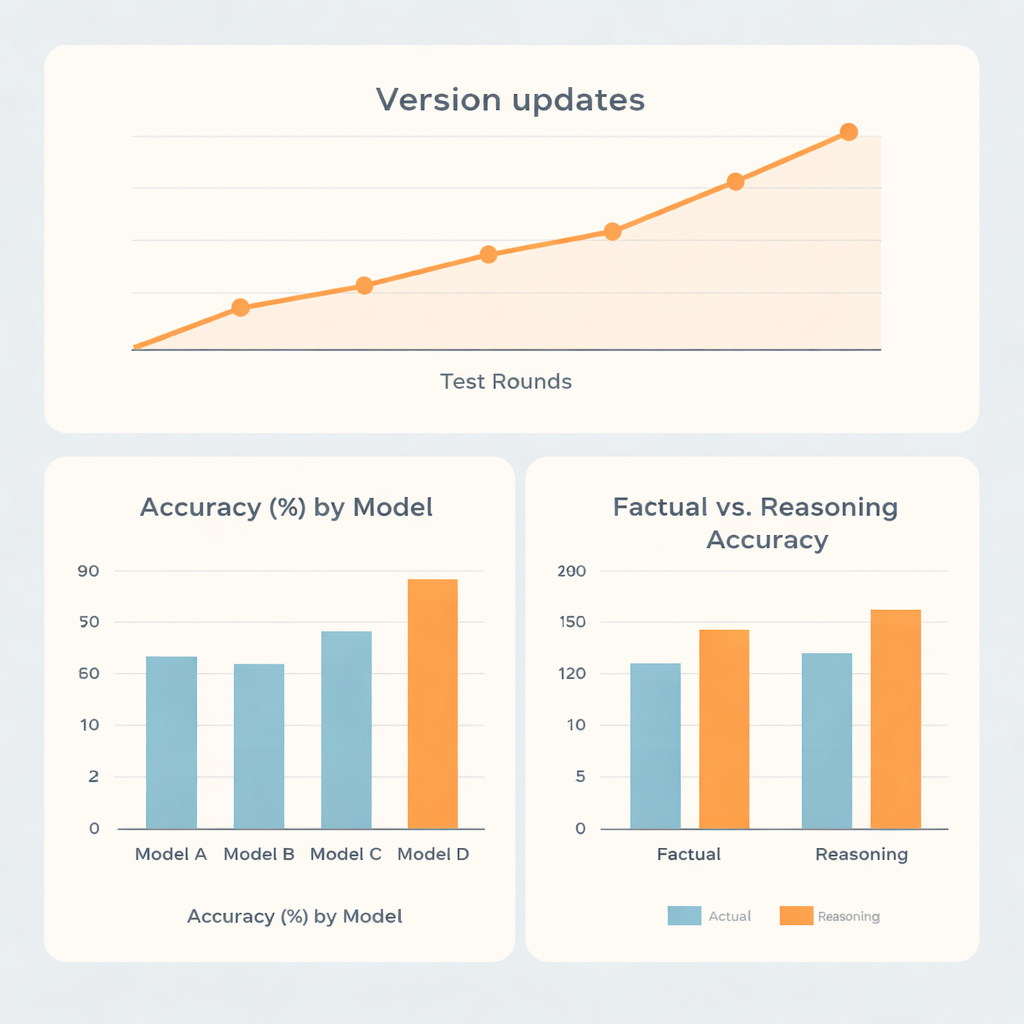
Nel complesso, due famiglie di modelli hanno mostrato prestazioni chiaramente superiori rispetto alle altre due. Il sistema più forte ha raggiunto circa il 73% di accuratezza, il secondo circa il 70%, mentre i modelli restanti si sono attestati intorno al 62% e al 56%. È interessante che i migliori non eccellessero soltanto sui fatti memorizzati. Si sono dimostrati nettamente migliori nelle domande che richiedevano ragionamento rispetto al semplice richiamo, suggerendo che questi sistemi sono relativamente forti nei compiti di pensiero a più fasi, come i calcoli di dosi o problemi di tipo pianificativo, in questo ambito medico ristretto. Un modello ha mostrato punteggi quasi identici tra item di fatto e di ragionamento, mentre un altro è rimasto indietro complessivamente nonostante avesse rendimenti superiori nel ragionamento rispetto ai fatti.
Aggiornamenti, lingue e disponibilità ad ammettere “Non lo so”
Poiché i sistemi di IA vengono aggiornati frequentemente, i ricercatori hanno anche esaminato come le prestazioni siano cambiate in cinque round di test distribuiti dalla fine del 2023 alla metà del 2025. I grandi aggiornamenti di versione tendevano a portare salti evidenti nell’accuratezza, mentre le piccole modifiche all’interno della stessa versione facevano poca differenza. Una famiglia è salita da meno del 60% a oltre l’80% di accuratezza nel tempo, evidenziando la rapidità dei progressi tecnologici. Sorprendentemente, il fatto che le domande fossero poste in cinese o in inglese, o dirette rispetto a incapsulate in un prompt di role‑playing, ha avuto effetti minori rispetto ai punti di forza intrinseci di ciascun modello. Più rilevanti sono state le differenze nel modo in cui i sistemi esprimevano la propria incertezza quando sbagliavano. Alcuni modelli hanno ammesso l’incertezza in quasi una risposta sbagliata su cinque, mentre un altro raramente lo faceva, offrendo spesso risposte sicure ma errate.
Cosa significa per medici, studenti e pazienti
Lo studio conclude che i migliori chatbot di uso generale di oggi possono già fornire spiegazioni abbastanza accurate e domande di esercitazione sulla BNCT, rendendoli assistenti promettenti per l’educazione e l’autoapprendimento. Tuttavia, nessuno dei sistemi è ancora affidabile per rispondere correttamente a tutte le domande sulla BNCT, e i loro modi di esprimere—o nascondere—l’incertezza differiscono in modi rilevanti per la sicurezza. Per ora questi strumenti vanno considerati assistenti intelligenti che possono supportare, ma non sostituire, il giudizio degli esperti. Gli autori sostengono che saranno necessari modelli di IA dedicati alla BNCT, insieme a standard chiari su come tali strumenti debbano essere utilizzati in clinica e a lezione, prima che l’IA possa assumere un ruolo di primo piano affidabile in questa forma altamente specializzata di cura oncologica.
Citazione: Shen, S., Wang, S., Gao, M. et al. Performance comparison of large language models in boron neutron capture therapy knowledge assessment. Sci Rep 16, 5321 (2026). https://doi.org/10.1038/s41598-026-36322-7
Parole chiave: terapia di cattura neutronica del boro, radioterapia oncologica, educazione medica, intelligenza artificiale, grandi modelli linguistici