Clear Sky Science · it
Apprendimento contrastivo linguaggio‑immagine guidato dall’oggetto per il riconoscimento zero‑shot dei bersagli
Occhi più intelligenti per cieli e mari affollati
I moderni sistemi di sicurezza e di risposta alle emergenze si affidano a telecamere in cielo e in mare per individuare velivoli, navi e altri oggetti critici. Ma insegnare ai computer a distinguere un caccia da un aereo di linea, o una nave da guerra da una mercantile, è sorprendentemente difficile quando le scene sono affollate, i dati scarsi e continuano a comparire nuovi modelli di equipaggiamento. Questo articolo presenta OG‑CLIP, un nuovo sistema di IA progettato per riconoscere bersagli militari e civili su cui non è mai stato esplicitamente addestrato, combinando conoscenze su larga scala con un focus visivo più netto sugli oggetti che contano davvero.
Perché l’IA tradizionale manca il bersaglio
La maggior parte dei sistemi di riconoscimento delle immagini impara da enormi raccolte di fotografie etichettate: ogni immagine è associata a una lista fissa di categorie, come “gatto” o “automobile”. Questo approccio fallisce in domini specializzati come la difesa e il telerilevamento, dove i dati sono sensibili, l’etichettatura richiede esperti e la varietà di equipaggiamenti è enorme. I modelli visione‑linguaggio più recenti, come CLIP, associano immagini a brevi didascalie raccolte sul web, permettendo di riconoscere nuovi concetti descritti a parole. Eppure nelle immagini militari questi modelli faticano ancora: le didascalie sono spesso vaghe, sfondi come nuvole e onde dominano i pixel e le loro rappresentazioni interne non sono abbastanza flessibili per funzionare efficientemente su tutto, dai piccoli droni ai server potenti. OG‑CLIP affronta frontalmente tutti e tre i problemi.
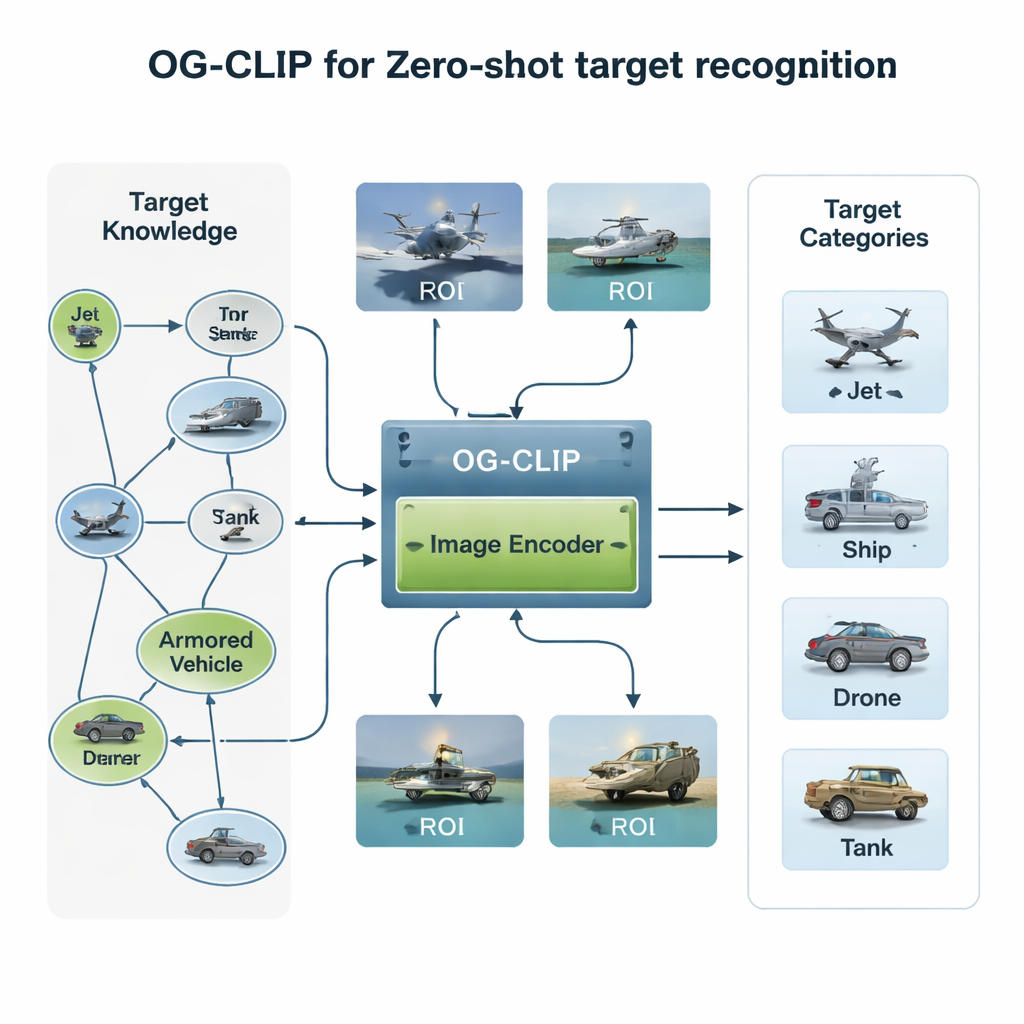
Costruire un mondo di addestramento ricco di conoscenza
Il primo ingrediente di OG‑CLIP è un universo di addestramento accuratamente progettato. Gli autori hanno assemblato un database di 5.000 tipi di bersagli—dai caccia e bombardieri alle navi da guerra e agli aerei civili—e li hanno organizzati in un dettagliato grafo della conoscenza. Ogni voce include fatti strutturati come autonomia, peso e configurazione d’armamento, tratti da riferimenti pubblici di difesa, enciclopedie e documenti tecnici. Hanno poi raccolto circa un milione di immagini usando dataset pubblici, ricerche sul web, archivi interni più datati e persino scene simulate da motori di gioco. Per mantenere i dati affidabili, hanno raggruppato le immagini con un modello esistente per individuare outlier, seguito da revisioni di esperti e filtraggio delle etichette errate. Infine, hanno impiegato strumenti avanzati linguaggio‑visione per trasformare il grafo della conoscenza in descrizioni in linguaggio naturale ricche per ogni immagine, così il sistema impara non solo “questo è un jet”, ma “un aeromobile a corridoio singolo con winglet rivolte verso l’alto” o “un bombardiere stealth con forma a ala volante”.
Insegnare al modello a ignorare il rumore
La seconda innovazione riguarda dove il modello guarda. In molte immagini satellitari o aeree, la nave o il velivolo occupa solo una piccola porzione, circondata da cielo, mare o terreno distraenti. OG‑CLIP aggiunge un modulo di regione d’interesse (ROI) che imita come un umano fisserebbe l’oggetto chiave invece dell’intero fotogramma. Uno strumento di segmentazione all’avanguardia delinea automaticamente gli oggetti probabili nell’immagine, producendo maschere morbide che evidenziano il bersaglio e attenuano lo sfondo. Queste maschere vengono fornite, insieme all’immagine originale, al backbone visivo del modello, in modo che la sua attenzione si concentri naturalmente su caratteristiche distintive come la forma delle ali, la disposizione del ponte o la silhouette dello scafo. Questo design plug‑in può essere aggiunto a sistemi esistenti senza riscriverne l’architettura centrale, conferendo loro uno sguardo più “guidato dall’oggetto”.

Adattare il dettaglio all’hardware
Il terzo elemento affronta una questione pratica ma cruciale: non tutti i dispositivi possono permettersi lo stesso livello di dettaglio. Una stazione di terra satellitare potrebbe elaborare feature ricche e ad alta dimensionalità, mentre un piccolo drone necessita di calcoli più rapidi e leggeri. I metodi tradizionali fissano una singola dimensione delle feature o addestrano diversi modelli separati per varie dimensioni. OG‑CLIP invece usa una rappresentazione in stile “Matryoshka”, impacchettando informazioni a più livelli di dettaglio in un unico vettore, come bambole russe annidate. Il sistema può tagliare porzioni più corte o più lunghe di questo vettore—descrizioni più grossolane o più fini di ciò che c’è nell’immagine—senza ritrenare. Un meccanismo di ponderazione incoraggia ogni livello a conservare l’informazione più utile per la classificazione, e un termine di perdita aggiuntivo spinge i livelli a rimanere semanticamente coerenti tra loro.
Quanto funziona bene nella pratica?
Per testare OG‑CLIP, i ricercatori hanno costruito un set di valutazione impegnativo di 99 categorie di bersagli, includendo 51 tipi di velivoli militari, 29 tipi di navi da guerra e 19 bersagli civili o misti. Crucialmente, nessuna di queste categorie appare nei dati di addestramento, quindi il sistema deve fare affidamento sulla sua comprensione appresa del linguaggio e dei pattern visivi—un test “zero‑shot”. Rispetto a diversi solidi modelli di riferimento basati su CLIP, OG‑CLIP ha migliorato l’accuratezza media di oltre 11 punti percentuali, raggiungendo complessivamente il 84,28 percento. Ha ottenuto risultati particolarmente buoni in scene affollate e complesse e nelle distinzioni fini tra modelli simili, come diversi caccia, dove il modulo ROI e le descrizioni ricche di conoscenza gli hanno dato un chiaro vantaggio. Studi di ablation hanno mostrato che ogni componente—i dati del grafo della conoscenza, il focus ROI e le rappresentazioni adattative—ha contribuito con guadagni misurabili.
Cosa significa per il monitoraggio nel mondo reale
Per i non specialisti, il punto chiave è che OG‑CLIP rappresenta un passo verso sistemi di sicurezza e monitoraggio che possono riconoscere in modo più affidabile velivoli e navi non familiari da immagini del mondo reale, anche quando gli esempi etichettati sono scarsi. Combinando conoscenza esperta strutturata, focus automatico sull’oggetto d’interesse e livelli di dettaglio regolabili, l’approccio rende l’IA visione‑linguaggio allo stesso tempo più intelligente e più pratica. Oltre la difesa, idee simili potrebbero aiutare il monitoraggio ambientale, la risposta ai disastri e i sistemi di ispezione industriale a interpretare scene complesse pur funzionando su un’ampia gamma di hardware.
Citazione: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
Parole chiave: riconoscimento zero‑shot, modelli visione‑linguaggio, rilevamento oggetti, telerilevamento, grafi della conoscenza