Clear Sky Science · it
Trasformers di deep learning basati sulla percezione visiva per classificare dipinti e fotografie tramite estrazione di caratteristiche
Perché è importante per le immagini di tutti i giorni
In un'epoca in cui chiunque può generare un'immagine realistica con pochi clic, diventa sempre più difficile stabilire se un'immagine sia una fotografia reale, un dipinto tradizionale o qualcosa creato interamente da algoritmi. Questo studio esplora come l'intelligenza artificiale moderna possa distinguere automaticamente i dipinti realizzati da esseri umani dalle foto scattate con una macchina fotografica e persino dalle immagini generate dall'IA, aiutando a proteggere i mercati dell'arte, gli archivi e gli utenti online da confusione e falsificazioni.
Arte, foto e l'ascesa delle immagini create dalle macchine
Dipinti e fotografie possono sembrare simili a prima vista su uno schermo, ma portano con sé impronte visive molto diverse. I dipinti tendono a mostrare pennellate visibili, colori stilizzati e composizioni più astratte, mentre le fotografie di solito contengono dettagli più nitidi e illuminazione naturale. Allo stesso tempo, i nuovi generatori di immagini producono opere che imitano entrambi i media con crescente abilità. Musei, gallerie, collezionisti e piattaforme digitali hanno sempre più bisogno di strumenti che possano rapidamente e in modo affidabile identificare di che tipo di immagine si tratta, sia per autenticare le opere sia per gestire il flusso di contenuti sintetici.
Una nuova pipeline per insegnare alle macchine a vedere
I ricercatori hanno costruito una pipeline completa di analisi delle immagini basata su un Vision Transformer, un recente modello di deep learning originariamente sviluppato per l'elaborazione del linguaggio e ora adattato alle immagini. Hanno addestrato questo sistema su un dataset pubblico di Kaggle contenente 1.361 dipinti e 3.747 fotografie, che rappresentano una vasta varietà di scene e stili. Ogni immagine viene prima standardizzata: ridimensionata, ritagliata leggermente e poi aumentata tramite ribaltamenti, piccole rotazioni, variazioni di luminosità e rimozione del rumore affinché il modello sperimenti molte variazioni realistiche. Dopo questa preparazione, il Vision Transformer divide ogni immagine in piccole patch e apprende come le diverse parti dell'immagine si relazionano tra loro su tutto il fotogramma. 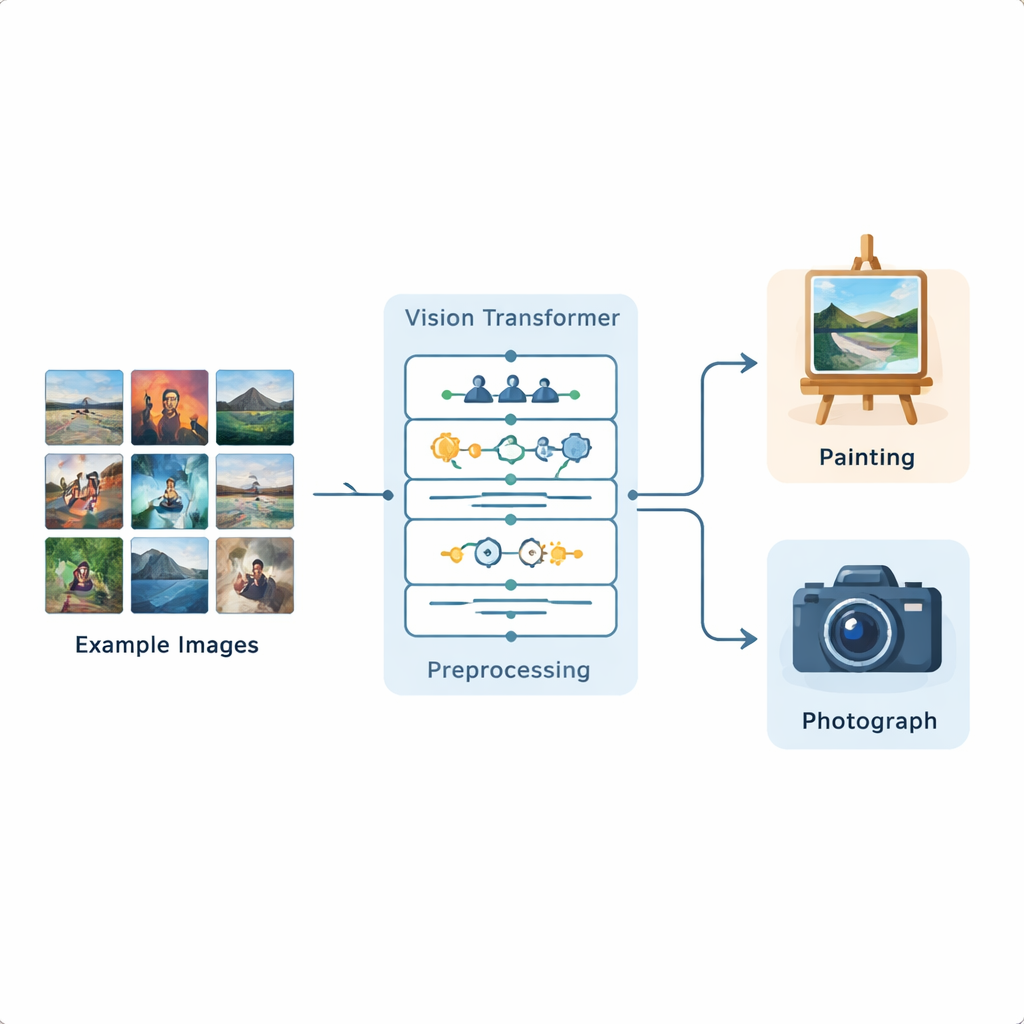
Come il modello si concentra sui dettagli giusti
A differenza delle reti neurali precedenti che guardavano principalmente i pattern locali, il Vision Transformer utilizza un meccanismo di "attenzione" per decidere quali parti di un'immagine sono più rilevanti per il compito. Si chiede, per ogni patch, quanto debba prestare attenzione a ogni altra patch. Questo lo rende più capace di cogliere la struttura globale: il modo in cui i colori scorrono su una tela, come la luce cade su una scena o come le texture si ripetono. Per verificare che il modello non stia indovinando alla cieca, gli autori applicano anche un metodo di visualizzazione chiamato Grad-CAM, che evidenzia le regioni specifiche che hanno influenzato ogni decisione. Per i dipinti, queste evidenziazioni tendono a concentrarsi sulle texture delle pennellate e su aree stilizzate; per le fotografie, si raggruppano attorno a bordi fini, superfici realistiche e transizioni di illuminazione. 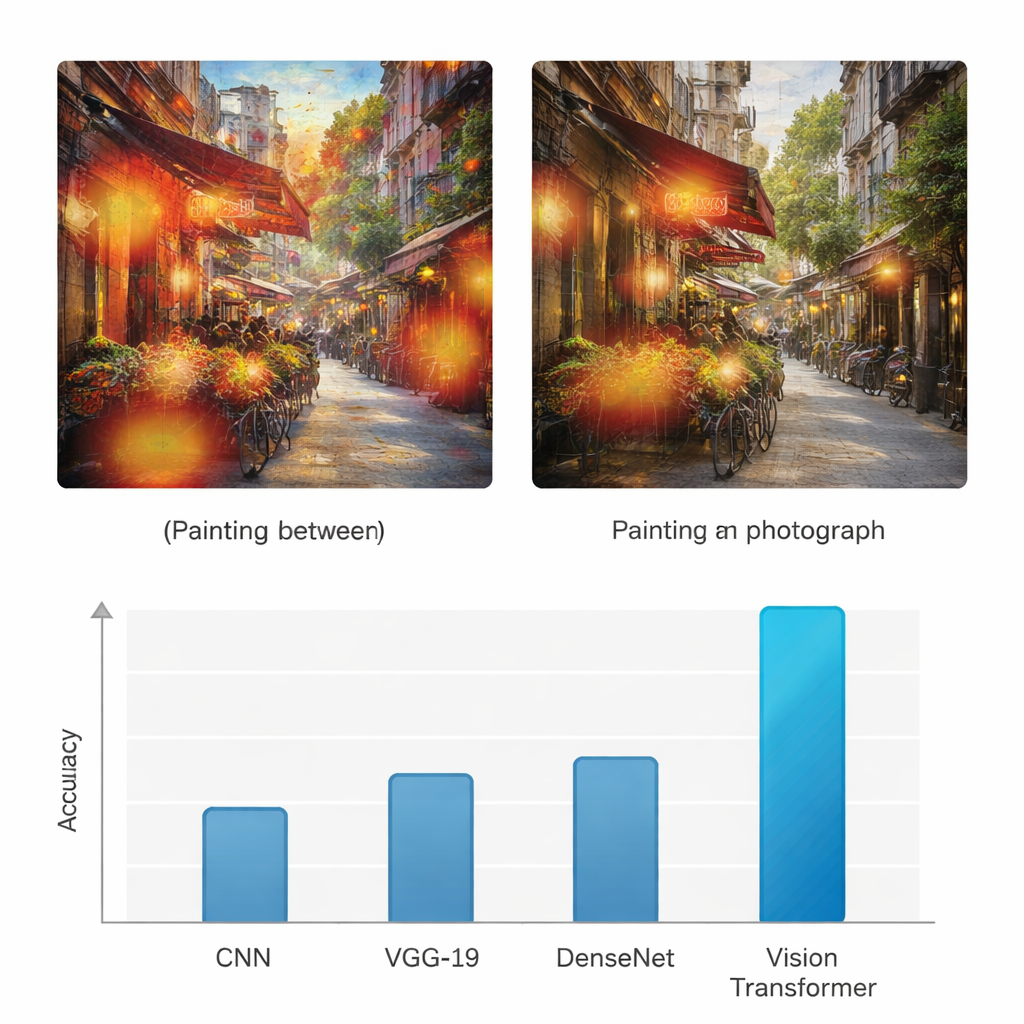
Superare i metodi precedenti di riconoscimento delle immagini
Per capire se questo approccio apporti realmente valore, lo studio confronta il Vision Transformer con tre architetture di deep learning ampiamente utilizzate: una rete neurale convoluzionale standard (CNN), la rete VGG-19 e DenseNet. Tutti i modelli sono addestrati e testati sullo stesso dataset e valutati con misure comuni come accuratezza, precisione, richiamo e F1-score, che bilanciano le rilevazioni corrette e gli errori per entrambe le classi. Mentre le reti di base raggiungono accuratezze nella fascia mediamente del 70-80%, il Vision Transformer ottiene il 95% di accuratezza sia per i dipinti sia per le fotografie, con precisione e richiamo altrettanto elevati. Gli autori eseguono inoltre molteplici test statistici per confermare che questo miglioramento non sia dovuto al caso, dimostrando che il modello basato su transformer è sistematicamente migliore attraverso prove ripetute e criteri di valutazione differenti.
Cosa significa per l'arte, la fiducia e la tecnologia
I risultati suggeriscono che i modelli transformer moderni possono servire come strumenti potenti e spiegabili per separare i dipinti dalle fotografie e per segnalare immagini generate dall'IA che imitano uno dei due media. Per i non specialisti, la conclusione è che i computer possono ora rilevare indizi sottili — come le pennellate, la levigatezza o i gradienti di illuminazione — che anche osservatori umani attenti potrebbero perdere, e farlo su larga scala. Tali sistemi potrebbero aiutare gallerie e collezionisti a verificare le opere, assistere curatori e archivisti nell'organizzare vaste collezioni digitali e supportare le piattaforme online nell'etichettare o filtrare contenuti sintetici. Man mano che i generatori di immagini continuano a sfumare il confine tra realtà e invenzione, metodi come quello presentato qui offrono un modo pratico per mantenere la fiducia in ciò che vediamo.
Citazione: Yu, L. Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction. Sci Rep 16, 5326 (2026). https://doi.org/10.1038/s41598-026-36298-4
Parole chiave: Immagini generate dall'IA, autenticazione delle opere d'arte, classificazione delle immagini, vision transformer, analisi dell'arte digitale