Clear Sky Science · it
Meta-apprendimento per il riconoscimento di compiti aperti con pochi esempi
Perché insegnare all’IA con pochissimi esempi è importante
I moderni sistemi di IA possono riconoscere volti, animali e oggetti di uso quotidiano con notevole accuratezza—ma di norma solo dopo aver visto milioni di immagini etichettate. In molte situazioni reali, come la diagnosi di una malattia rara o l’individuazione di un nuovo tipo di difetto su una linea di produzione, semplicemente non disponiamo di così tanti dati. Questo articolo esplora come addestrare modelli di IA che possano apprendere nuovi compiti visivi a partire da una manciata di esempi, anche quando quei compiti sono molto diversi da quelli su cui il modello è stato addestrato. Introduce un metodo chiamato Open-MAML che mira a rendere questo tipo di apprendimento flessibile e a basso consumo di dati più affidabile e prevedibile.
Dalle esercitazioni rigide a interrogazioni aperte
Gran parte della ricerca sul “few-shot learning” valuta i sistemi di IA in condizioni strettamente controllate. Il modello è addestrato e testato su compiti molto simili: per esempio deve sempre distinguere tra esattamente cinque categorie (detto “5-way”) con un esempio per categoria (“1-shot”). È come esercitare uno studente solo con quiz di cinque domande con un esempio di pratica per ogni tipo di domanda. Le applicazioni nel mondo reale sono molto più caotiche: il numero di categorie può cambiare e la quantità di dati etichettati per ciascuna può aumentare o diminuire nel tempo. Gli autori chiamano questa situazione più realistica il contesto di compito aperto, in cui i modelli devono gestire compiti con numeri di classi ed esempi diversi rispetto a quelli visti durante l’addestramento. 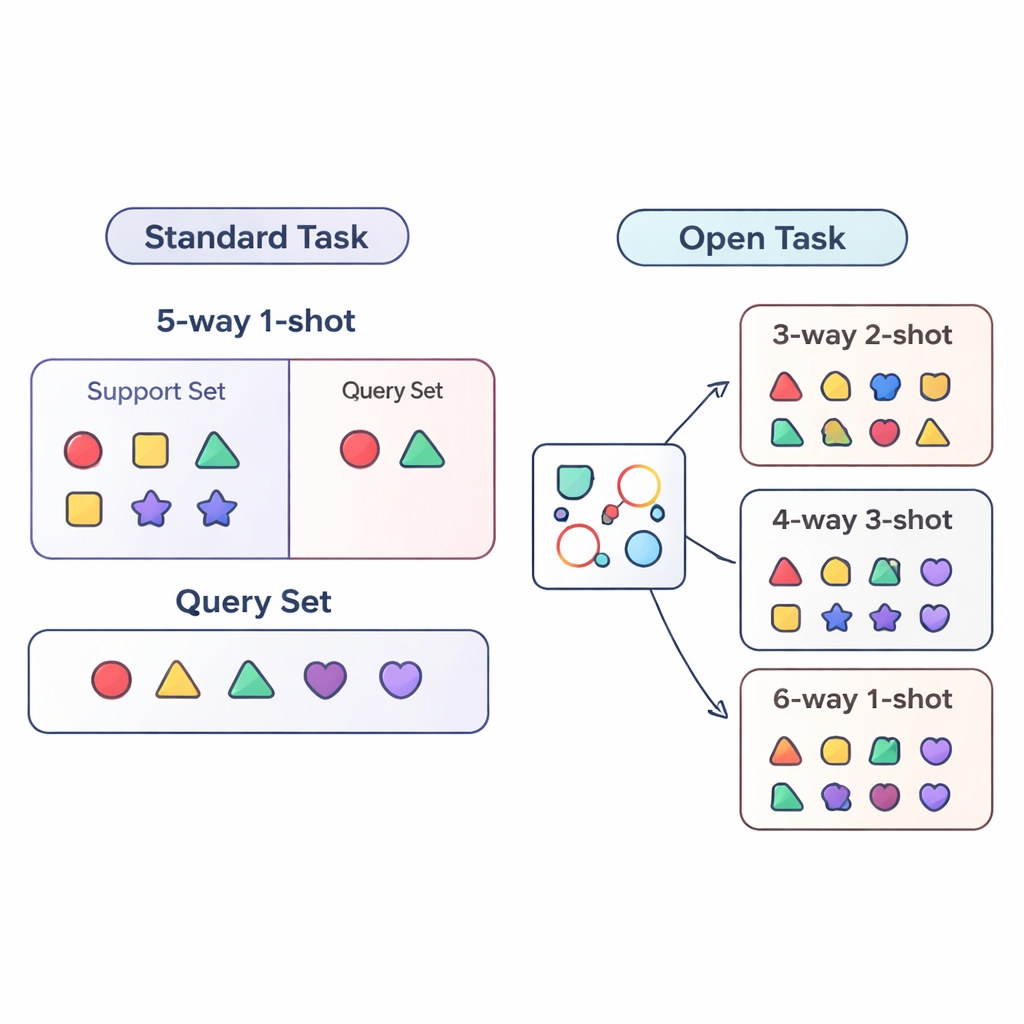
Ridefinire come testiamo i learner few-shot
Per studiare in modo sistematico questo mondo di compiti aperti, l’articolo propone tre regimi di valutazione. Nel regime cross-way cambia solo il numero di classi: il modello potrebbe essere addestrato su cinque classi ma testato su tre o quindici. Nel regime cross-shot varia il numero di esempi per classe, da una singola immagine etichettata a diverse. Il caso più difficile è cross-way–cross-shot, dove sia il numero di classi sia la quantità di dati per classe cambiano insieme. Gli autori esaminano anche cosa accade quando lo stile visivo dei dati cambia, addestrando su un dataset generico di oggetti e testando su un dataset più fine di uccelli. Queste configurazioni sono pensate per mettere alla prova se un metodo può davvero generalizzare oltre una singola ricetta di addestramento fissa.
Come Open-MAML si adatta al volo
Open-MAML si basa su una strategia di meta-apprendimento diffusa chiamata Model-Agnostic Meta-Learning (MAML), che addestra un modello affinché possa adattarsi rapidamente a un nuovo compito con pochi passi di gradiente. Tuttavia il MAML standard presume che il numero di categorie al test corrisponda a quello dell’addestramento e utilizza uno strato finale di classificazione fisso. Open-MAML introduce tre accorgimenti chiave per superare questa limitazione. Primo, utilizza la costruzione dinamica del classificatore: quando un nuovo compito ha più classi di prima, crea unità di output aggiuntive copiando la media di quelle esistenti, dando al modello un punto di partenza neutro ma sensato. Secondo, regola il tasso di apprendimento interno in base al numero di classi e di esempi del compito, così l’adattamento resta stabile sia quando i dati sono scarsi sia quando sono abbondanti. Terzo, aggiunge un regularizzatore chiamato AdaDropBlock che nasconde temporaneamente regioni contigue nelle mappe di feature durante l’addestramento, spingendo il modello a usare indizi visivi più diversi invece di sovradattarsi a dettagli piccoli e fragili. 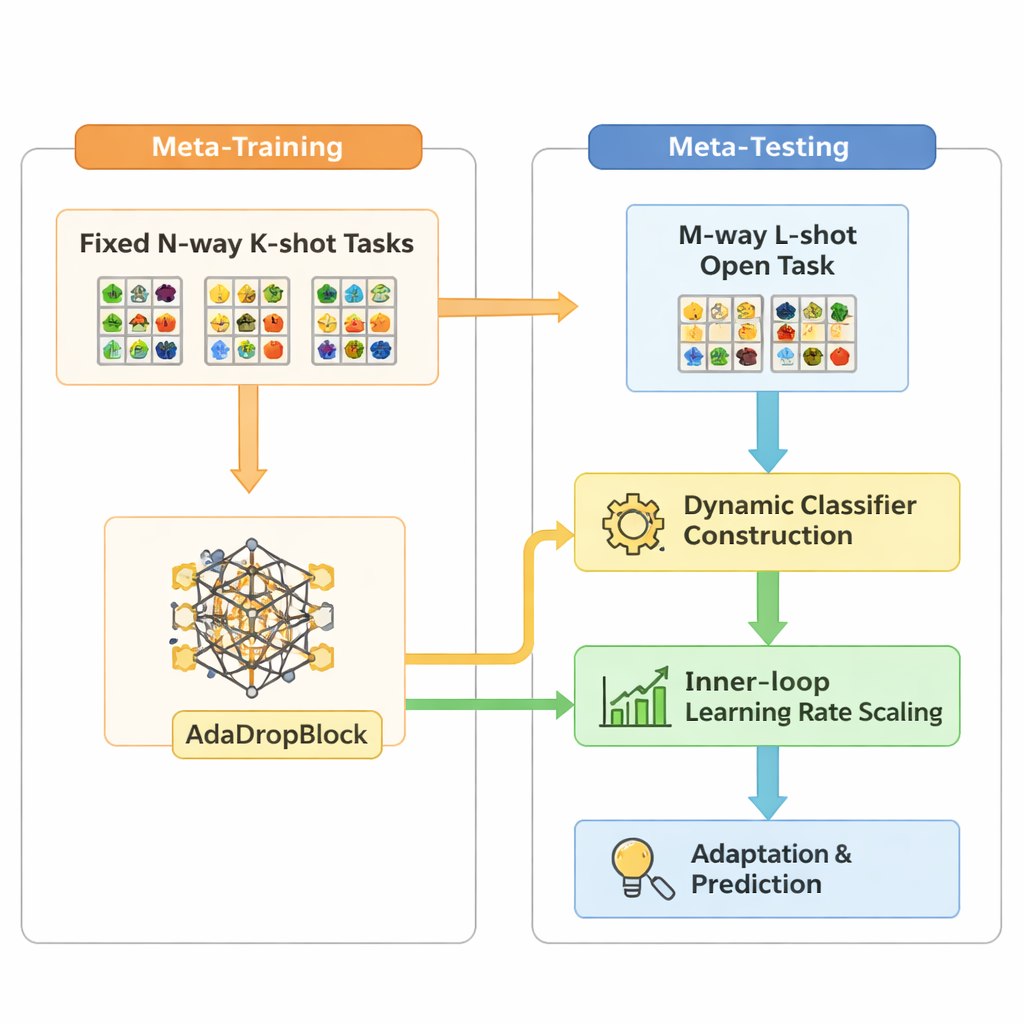
Mettere alla prova l’apprendimento flessibile
I ricercatori valutano Open-MAML su benchmark standard di few-shot e nei nuovi scenari di compito aperto, confrontandolo con diversi baseline noti. Tra questi ci sono modelli addestrati da zero per ciascun compito, modelli che utilizzano un potente estrattore di feature pre-addestrato più un classificatore fine-tuned, e metodi basati su metriche che classificano immagini in base alla distanza dai “prototipi” di classe. Tutti i metodi condividono la stessa rete backbone in modo che le differenze dipendano dalla strategia di apprendimento, non dall’architettura. Su decine di migliaia di compiti di test, Open-MAML ottiene costantemente un’accuratezza più alta—tipicamente 1–7 punti percentuali in più quando cambia solo il numero di classi o di esempi, e 3–6 punti in più quando variano entrambi. I guadagni sono ancora più pronunciati negli scenari più difficili con più classi, più shot o con il passaggio al dataset di uccelli, suggerendo che i suoi meccanismi di adattamento aiutano realmente in territori complessi e non familiari.
Cosa significa per i sistemi IA nel mondo reale
Per un lettore generale, il messaggio è che non tutti i few-shot learner sono uguali una volta usciti dalla zona di comfort del laboratorio. Un metodo che eccelle su un singolo benchmark fisso può inciampare quando il numero di categorie o la quantità di dati etichettati cambia. Open-MAML dimostra che pianificando esplicitamente per tali variazioni strutturali—consentendo al classificatore di crescere o ridursi, scalando il learning rate con la dimensione del compito e regularizzando le feature in modo agnostico rispetto al compito—i sistemi di IA possono meglio affrontare le condizioni mutevoli che incontreranno in pratica. In ambiti come l’imaging medico, il monitoraggio satellitare o l’ispezione industriale, dove sia l’insieme di categorie sia la disponibilità di etichette sono in continuo cambiamento, questo tipo di robustezza ai compiti aperti potrebbe rendere il few-shot learning molto più utilizzabile al di fuori di benchmark di ricerca accuratamente curati.
Citazione: Han, X., Shi, D., Wang, Z. et al. Meta-learning for few-shot open task recognition. Sci Rep 16, 5624 (2026). https://doi.org/10.1038/s41598-026-36291-x
Parole chiave: few-shot learning, meta-learning, open-task recognition, image classification, generalization