Clear Sky Science · it
Un framework di apprendimento ibrido che integra l’evoluzione caotica Niche alpha per la previsione delle prestazioni scolastiche degli studenti
Perché è importante prevedere i voti in anticipo
Le scuole dispongono sempre più di una miniera d’oro di informazioni sui loro studenti — dai registri delle presenze e i voti dei compiti alle risposte ai questionari sulla vita familiare e sulle abitudini di studio. Questo articolo esplora come trasformare quei dati grezzi in segnali di allerta precoce su chi potrebbe avere difficoltà o eccellere in un corso. Gli autori presentano un nuovo framework informatico che predice con maggiore accuratezza i voti finali degli studenti delle scuole secondarie, aprendo la strada a interventi più tempestivi e mirati invece di interventi last‑minute.
Dai pagellini a tracce di dati ricche
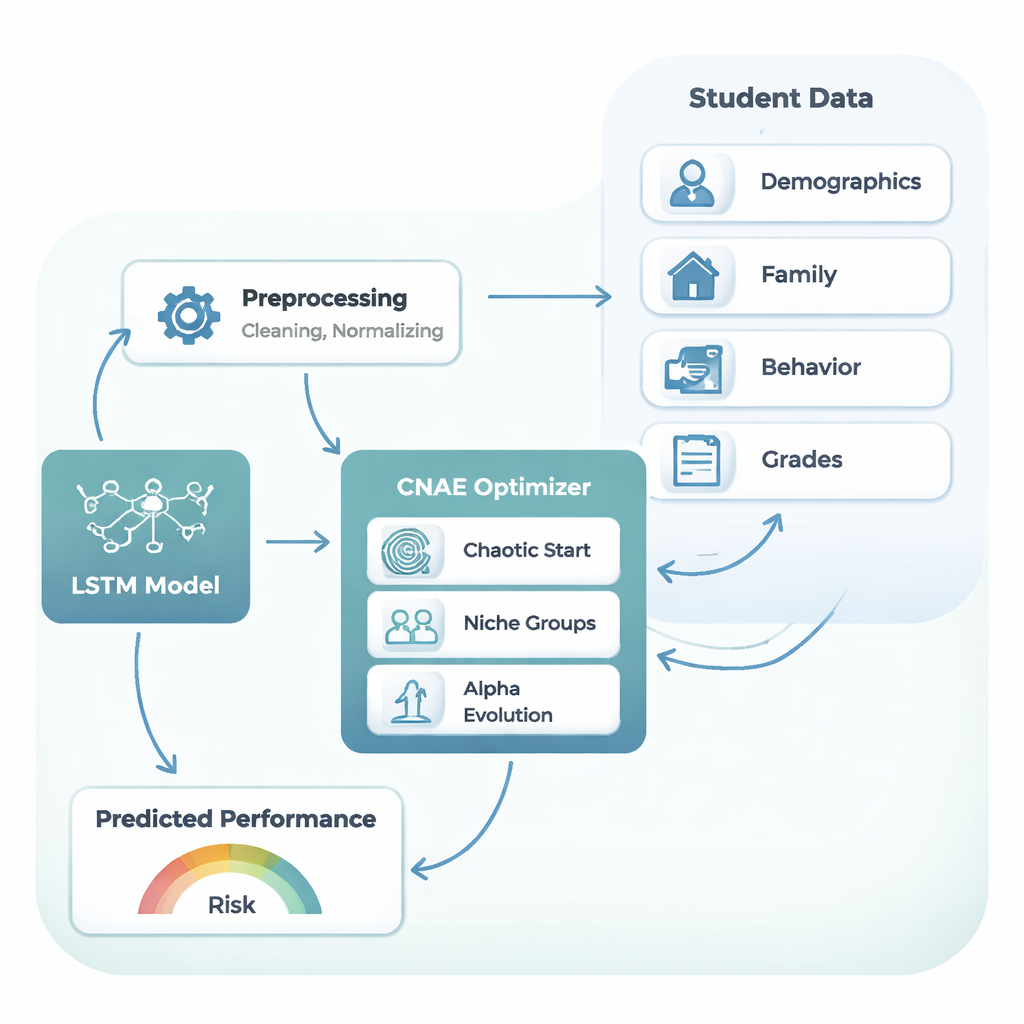
Le aule moderne producono molto più di un paio di voti d’esame. Il dataset utilizzato in questo studio include 480 studenti e 32 diverse informazioni per ciascuno: età, contesto familiare, tempo di tragitto, accesso a Internet, tempo dedicato allo studio, assenze e tre voti del corso distribuiti nell’anno scolastico. Insieme, questi dettagli tracciano un percorso di apprendimento — come impegno, circostanze e risultati precedenti si accumulano fino al voto finale. Tuttavia, questa ricchezza rende anche la previsione più difficile: i dati sono rumorosi, disomogenei e altamente variabili da uno studente all’altro.
Un modo più intelligente di leggere l’apprendimento nel tempo
Per seguire questi percorsi di apprendimento, gli autori si affidano a un tipo di rete neurale chiamata Long Short‑Term Memory, o LSTM. Invece di trattare ogni informazione come un fatto scollegato, un LSTM è progettato per ricordare segnali utili provenienti da punti precedenti di una sequenza — un po’ come un insegnante che ricorda un miglioramento costante o un progressivo disimpegno di uno studente anziché guardare solo all’ultimo quiz. In questo studio, l’LSTM incorpora il mix di fattori di contesto, comportamenti e voti precedenti e produce una previsione del voto finale su una scala da 0 a 20. Tuttavia, gli LSTM sono pignoli: le loro prestazioni dipendono fortemente da scelte di progetto come il numero di strati, le unità per strato, la velocità di apprendimento, la quantità di regolarizzazione e il numero di record studente elaborati per volta durante l’addestramento.
Lasciare che l’evoluzione cerchi il modello migliore
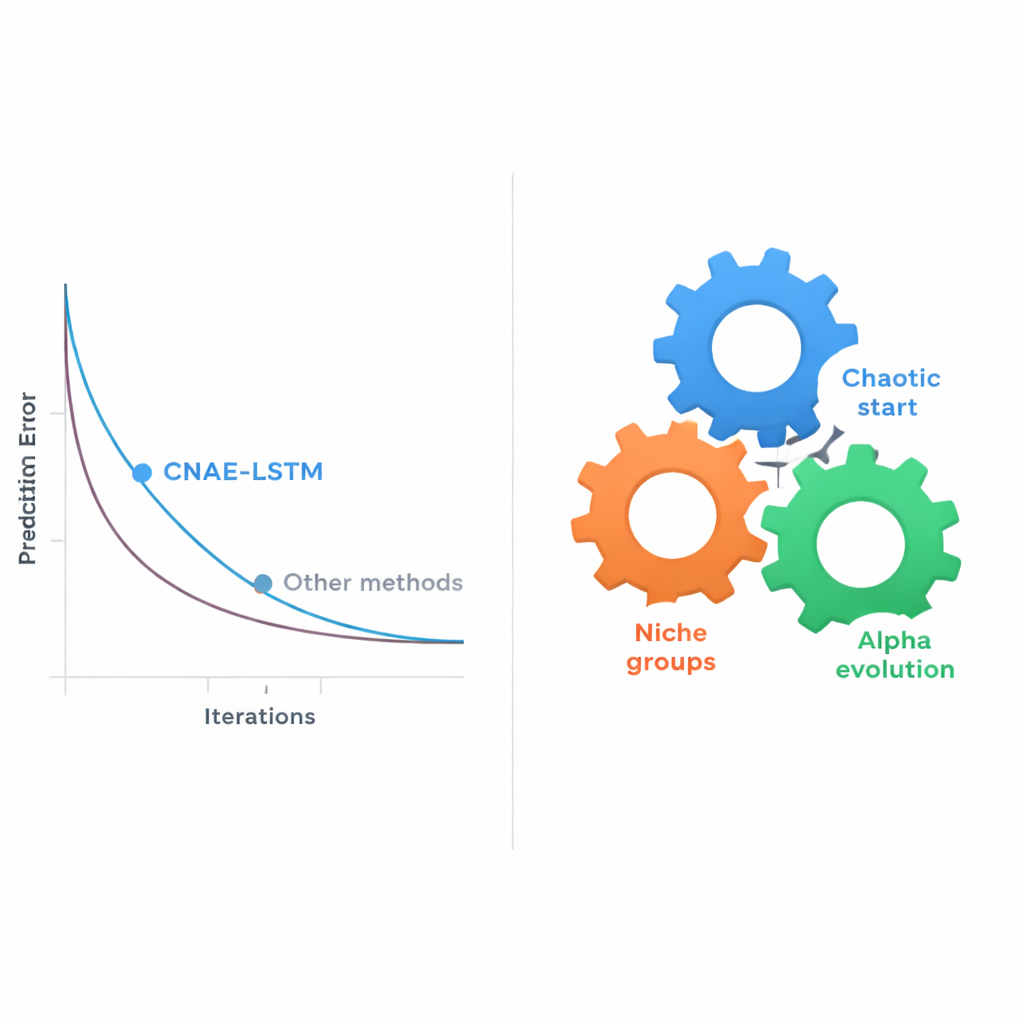
Scegliere manualmente tali impostazioni — o anche con semplici prove ed errori a griglia — diventa rapidamente impraticabile man mano che le combinazioni esplodono. Il nucleo di questo articolo è una nuova strategia di ricerca automatica chiamata Chaotic Niche Alpha Evolution (CNAE), che gli autori associano all’LSTM, formando il framework CNAE‑LSTM. CNAE inizia generando una grande varietà di progetti LSTM candidati usando un processo matematico ispirato al caos, assicurando che le opzioni iniziali siano ampiamente distribuite nello spazio di ricerca. Raggruppa poi candidati simili in “nicchie”, mantenendo solo l’esempio più forte di ciascun cluster mentre li muta leggermente per sondare possibilità vicine. Infine, un passaggio di “alpha evolution” spinge la ricerca verso le regioni più promettenti mentre gradualmente si passa dall’esplorazione ampia alla messa a punto fine. Ogni LSTM candidato viene valutato in base a quanto bene predice i voti su un set di validazione separato, e i progetti migliori sopravvivono per modellare la generazione successiva.
Cosa mostrano gli esperimenti
I ricercatori hanno testato il loro approccio sul dataset reale delle scuole secondarie, confrontando CNAE‑LSTM con una serie di alternative: una support vector machine (un metodo classico di machine learning), due modelli di deep learning (una rete convoluzionale e un Transformer), un LSTM standard regolato a mano e diversi LSTM le cui impostazioni erano state scelte con noti metodi di ricerca evolutiva o tramite ricerca a griglia e casuale. Le prestazioni sono state misurate dalla vicinanza tra voti predetti e reali e dalla quota di varianza nei punteggi che il modello riusciva a spiegare. CNAE‑LSTM è risultato il migliore su tutte le misure: ha registrato l’errore medio di previsione più basso e la massima capacità di spiegare le differenze tra gli studenti, migliorando l’errore di oltre il 10 percento rispetto al più forte baseline evolutivo esistente. Ripetere gli esperimenti 30 volte ha mostrato che CNAE‑LSTM non era solo più accurato, ma anche più stabile — i suoi risultati variavano meno tra una esecuzione e l’altra.
Perché questo è importante per studenti e scuole
Per un lettore non specialistico, la conclusione è semplice: permettendo a una procedura di ricerca evolutiva di progettare il modello predittivo, le scuole possono ottenere previsioni più affidabili su come gli studenti finiranno un corso molto prima dell’esame finale. Il framework CNAE‑LSTM trasforma dati educativi disordinati e reali in un quadro più chiaro di chi è in regola e chi potrebbe aver bisogno di aiuto extra, utilizzando le risorse computazionali in modo sufficientemente efficiente da risultare praticabile. Sebbene lo studio attuale si concentri su un singolo dataset di scuola secondaria, lo stesso approccio potrebbe essere adattato ad altre materie e livelli scolastici. Se accoppiati a interventi ponderati e umani, questi strumenti previsionali potrebbero aiutare gli educatori a passare dal reagire al fallimento al prevenirlo.
Citazione: Chen, H., Zhou, Y. & Cao, Q. A hybrid learning framework integrating chaotic Niche alpha evolution for student academic performance prediction. Sci Rep 16, 5302 (2026). https://doi.org/10.1038/s41598-026-36263-1
Parole chiave: predizione delle prestazioni degli studenti, data mining educativo, LSTM, ottimizzazione evolutiva, sistemi di allerta precoce