Clear Sky Science · it
Decisione NBV gerarchica basata sull'informazione reciproca per SLAM visivo semantico attivo in ambienti dinamici
Robot che sanno guardare avanti
Con il passaggio dei robot dalle fabbriche alle case, agli ospedali e agli uffici, devono muoversi in spazi pieni di persone e altri oggetti in movimento. Questo articolo presenta un nuovo modo per far «pensare in anticipo» il robot su dove guardare e come muoversi, così da costruire una mappa affidabile dell’ambiente—anche quando ciò che lo circonda non resta fermo. Il lavoro è importante per chiunque stia pensando a robot di servizio più sicuri, corrieri intelligenti o futuri assistenti domestici che devono condividere lo spazio con gli esseri umani anziché con corridoi vuoti.
Perché le persone in movimento confondono i robot
Per muoversi autonomamente molti robot usano una tecnica chiamata visual SLAM, in cui una camera aiuta a costruire una mappa e a stimare la posizione simultaneamente. Questo funziona bene in ambienti statici ma si deteriora rapidamente quando persone attraversano, ostruiscono la vista o trasportano oggetti. Una soluzione comune è usare la visione «semantica» così che il robot riconosca persone, automobili e sedie e le ignori nella costruzione della mappa. Tuttavia questo crea un nuovo problema per i robot attivi che scelgono il proprio percorso: scartando troppe informazioni visive rischiano di perdere del tutto la localizzazione. Il campo visivo limitato della camera aggrava il problema, perché una singola persona che passa vicino può nascondere buona parte dello scenario utile agli occhi del robot.
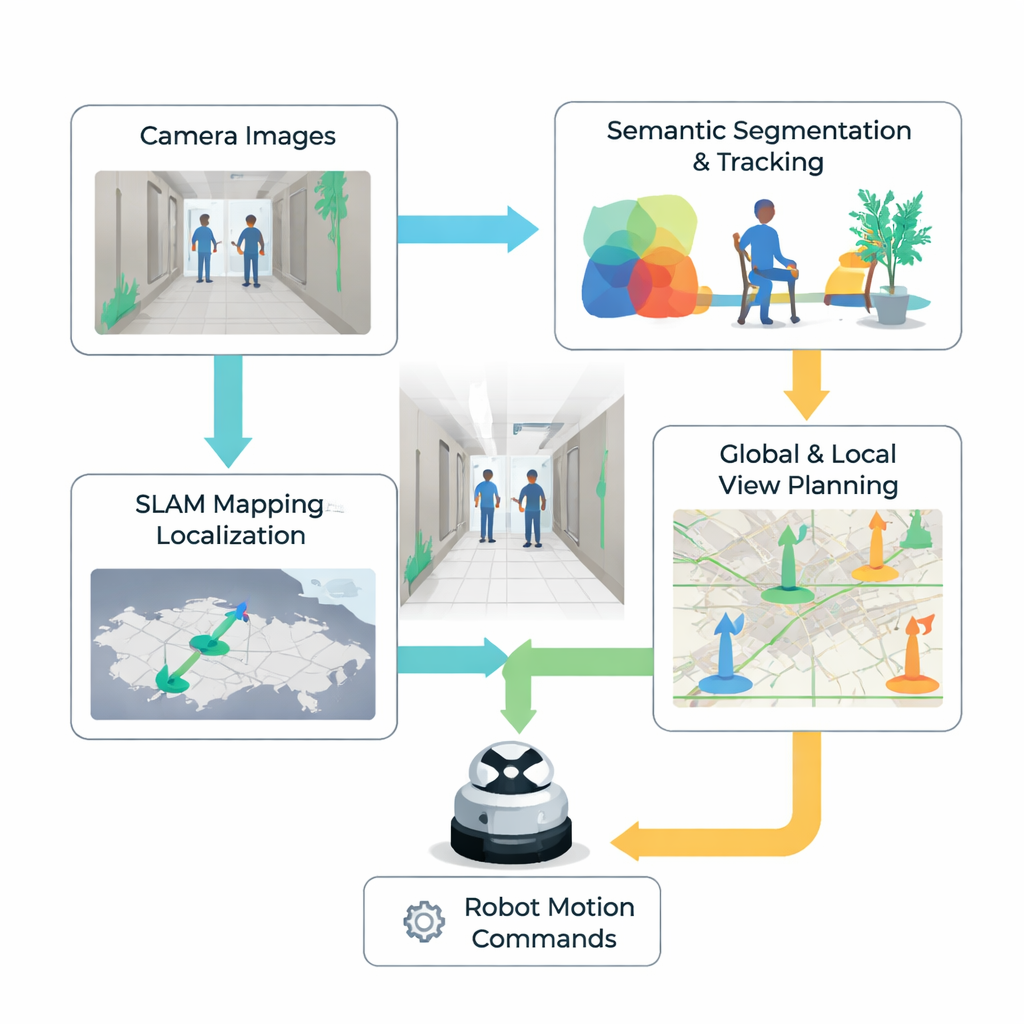
Una strategia a due livelli per scegliere dove guardare
Gli autori propongono un sistema decisionale gerarchico che aiuta il robot a decidere i prossimi punti di vista in modo più informato. A livello superiore, il robot mantiene una mappa a griglia vista dall’alto delle aree libere, occupate e sconosciute. Valuta i possibili punti di vista distanti stimando quanto ciascuno ridurrebbe l’incertezza in questa mappa, un concetto mutuato dalla teoria dell’informazione. Il robot preferisce posizioni che rivelino ampie aree inesplorate considerando al contempo quanto deve viaggiare e quanto deve ruotare la camera. Una volta scelto un settore promettente, un processo di livello inferiore prende il controllo per perfezionare esattamente come il robot dovrebbe muoversi e orientarsi all’interno di quel quartiere, in modo da riuscire effettivamente a vedere abbastanza dettagli utili con il suo campo visivo ristretto.
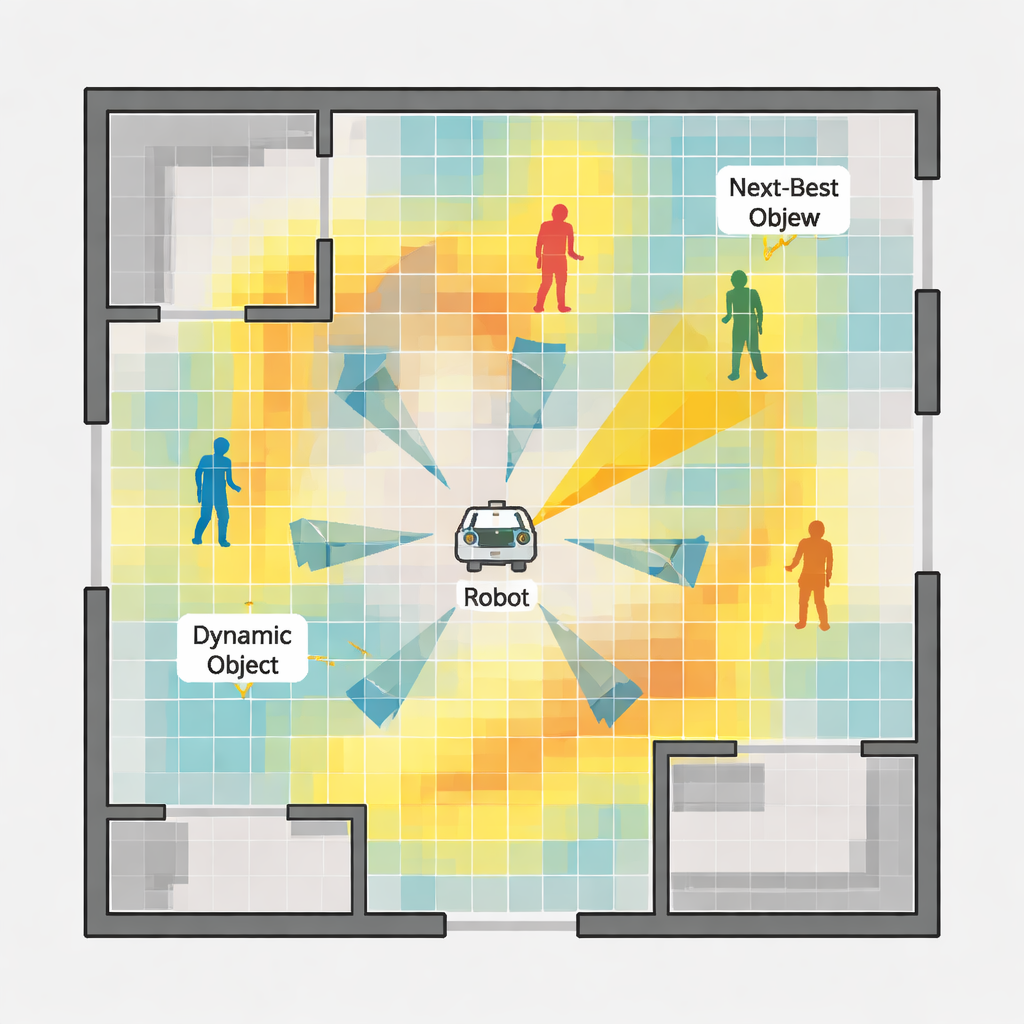
Vedere ciò che è stabile ed evitare ciò che non lo è
Al centro del processo decisionale locale c’è una «mappa di probabilità delle feature» costruita a partire da ogni immagine della camera. Innanzitutto il sistema rileva punti di riferimento visivi—angoli e pattern nella scena—che hanno probabilità di rimanere stabili nel tempo e sono utili per il tracciamento del movimento. Poi utilizza un rilevatore moderno di oggetti per individuare elementi potenzialmente mobili, come persone, e li traccia attraverso i fotogrammi. Analizzando il moto di questi oggetti, il sistema stima non solo dove si trovano ora, ma dove è probabile che si trovino nel prossimo futuro. Queste due fonti di informazione vengono fuse in una mappa di calore sull’immagine: regioni luminose indicano un’alta probabilità di vedere landmark affidabili, mentre regioni più scure segnalano aree povere di feature o probabilmente coperte da oggetti in movimento. Il robot usa questa mappa per giudicare quale piccola azione—girare a sinistra, a destra o avanzare—gli darà la vista più chiara e stabile possibile nel passo successivo.
Test in mondi virtuali e nel mondo reale
I ricercatori hanno testato l’approccio in due spazi interni simulati di dimensioni e complessità diverse, ciascuno popolato da pedoni virtuali in movimento, e poi su un robot fisico che si muoveva in un ambiente interno reale. Hanno confrontato il loro metodo con varie strategie di esplorazione consolidate che mirano principalmente a coprire lo spazio o a ridurre la distanza di viaggio. Nelle simulazioni, il nuovo sistema ha prodotto mappe con meno distorsione e ha raggiunto una migliore precisione di posizionamento esplorando in tempi paragonabili o inferiori. Era anche meno propenso a perdere la traccia della posizione o ad avvicinarsi troppo a persone in movimento. Nell’esperimento nel mondo reale, il metodo ha funzionato in tempo reale su un computer robotico commerciale, confermando che è praticabile per il dispiegamento fuori dal laboratorio.
Cosa significa per i robot di tutti i giorni
In parole semplici, questo lavoro insegna a un robot a essere selettivo su dove guarda e dove si dirige quando ci sono persone intorno. Combinando comprensione della scena, previsione del movimento e una misura del guadagno informativo, il robot può orientarsi verso viste che sono al contempo informative e sicure, invece di limitarsi a dirigersi verso l’angolo inesplorato più vicino. Ciò rende la sua mappa interna più affidabile e i suoi movimenti più prevedibili, ingredienti fondamentali per robot che devono condividere spazi affollati con gli umani. Rimangono alcune sfide—come grandi folle improvvise che bloccano la camera—ma l’approccio rappresenta un passo verso robot domestici e di servizio capaci di gestire con garbo la natura disordinata e dinamica della vita reale.
Citazione: Yang, Z., Sang, A.W.Y., Muthugala, M.A.V.J. et al. Mutual information-based hierarchical NBV decision for active semantic visual SLAM under dynamic environments. Sci Rep 16, 5847 (2026). https://doi.org/10.1038/s41598-026-36259-x
Parole chiave: SLAM attivo, navigazione robotica, ambienti dinamici, mappatura semantica, next-best view