Clear Sky Science · it
Segmentazione delle ghiandole colorettali con supervisione debole tramite apprendimento auto-supervisionato e pseudo-etichettatura basata su attenzione
Perché questo è importante per la diagnosi del cancro
Quando un patologo osserva al microscopio una biopsia del colon, una delle indicazioni più importanti della gravità del cancro è la forma e l’organizzazione di piccole strutture tubolari chiamate ghiandole. Delineare manualmente ogni ghiandola è lento, costoso e difficile da standardizzare tra gli ospedali. Questo studio mostra come l’intelligenza artificiale possa imparare a tracciare queste ghiandole quasi quanto esperti umani, usando però etichettature umane molto meno dettagliate, accelerando e rendendo più precisa la diagnosi del cancro colorettale.
La sfida di disegnare ogni piccolo contorno
Il cancro colorettale è uno dei tumori più comuni e letali al mondo, e la classificazione della sua gravità dipende in larga misura dall’aspetto delle ghiandole. Nei tessuti sani o nelle fasi iniziali le ghiandole appaiono come tubi ordinati e tondeggianti; nei tumori aggressivi diventano frastagliate, fuse o quasi irriconoscibili. I computer possono essere addestrati a segmentare, cioè a “colorare” ciascuna ghiandola per permettere misurazioni automatiche, ma i sistemi di deep learning tradizionali richiedono contorni pixel-per-pixel tracciati con cura da patologi esperti. Nelle cliniche reali è molto più facile ottenere etichette a livello di immagine, per esempio se una porzione di tessuto contiene o meno ghiandole, o se è benigna o maligna.
Addestrare un’IA con vetrini non etichettati e debolmente etichettati
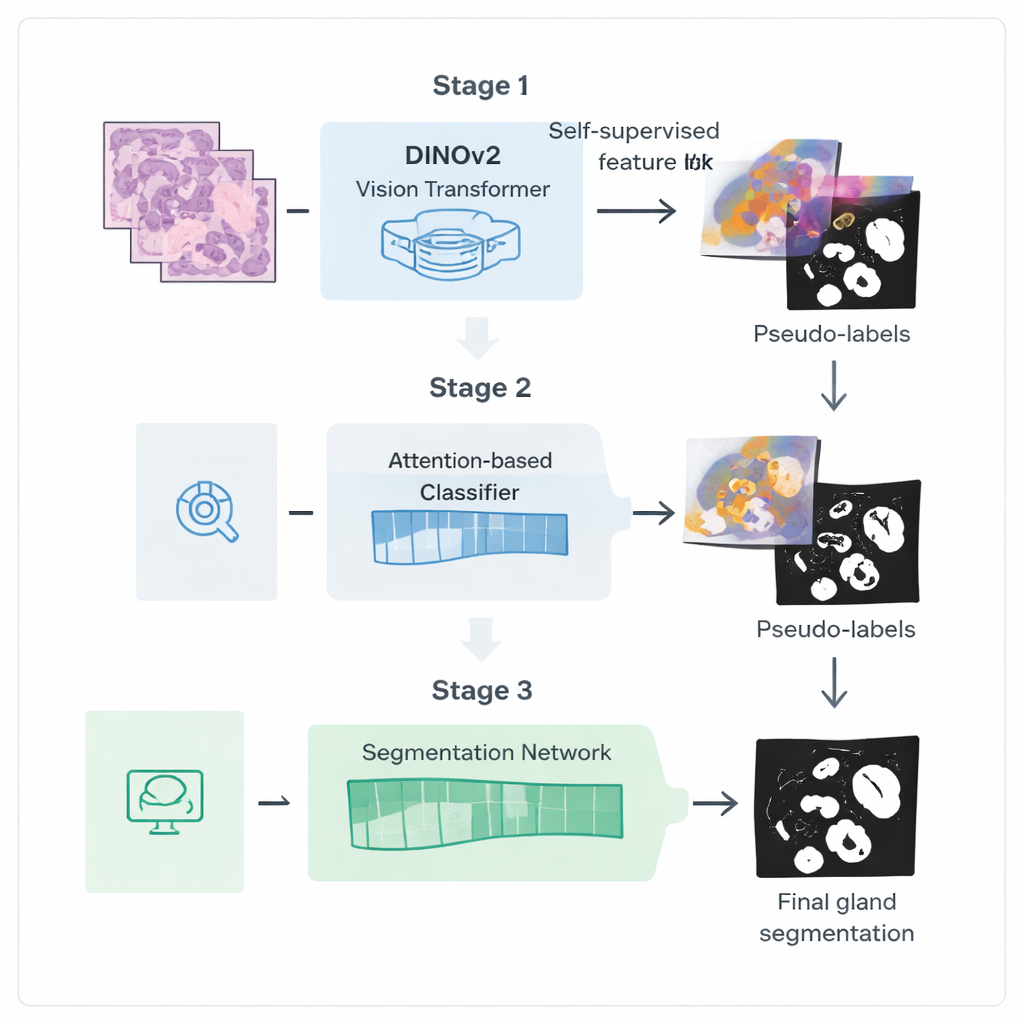
Gli autori propongono una pipeline di addestramento in tre fasi pensata per ricavare più valore da queste etichette deboli. Prima di tutto partono da un potente modello di visione chiamato DINOv2, originariamente addestrato su fotografie naturali, ed espongono il modello a migliaia di immagini di biopsie colorettali non etichettate. Facendo corrispondere diverse viste della stessa porzione di tessuto, il modello apprende caratteristiche visive tarate sui colori e le texture dei vetrini istologici senza bisogno di annotazioni. Questa fase crea un “encoder” specializzato che trasforma le immagini grezze in rappresentazioni interne ricche che catturano strutture simili a ghiandole.
Lasciare che l’IA mostri dove sta guardando
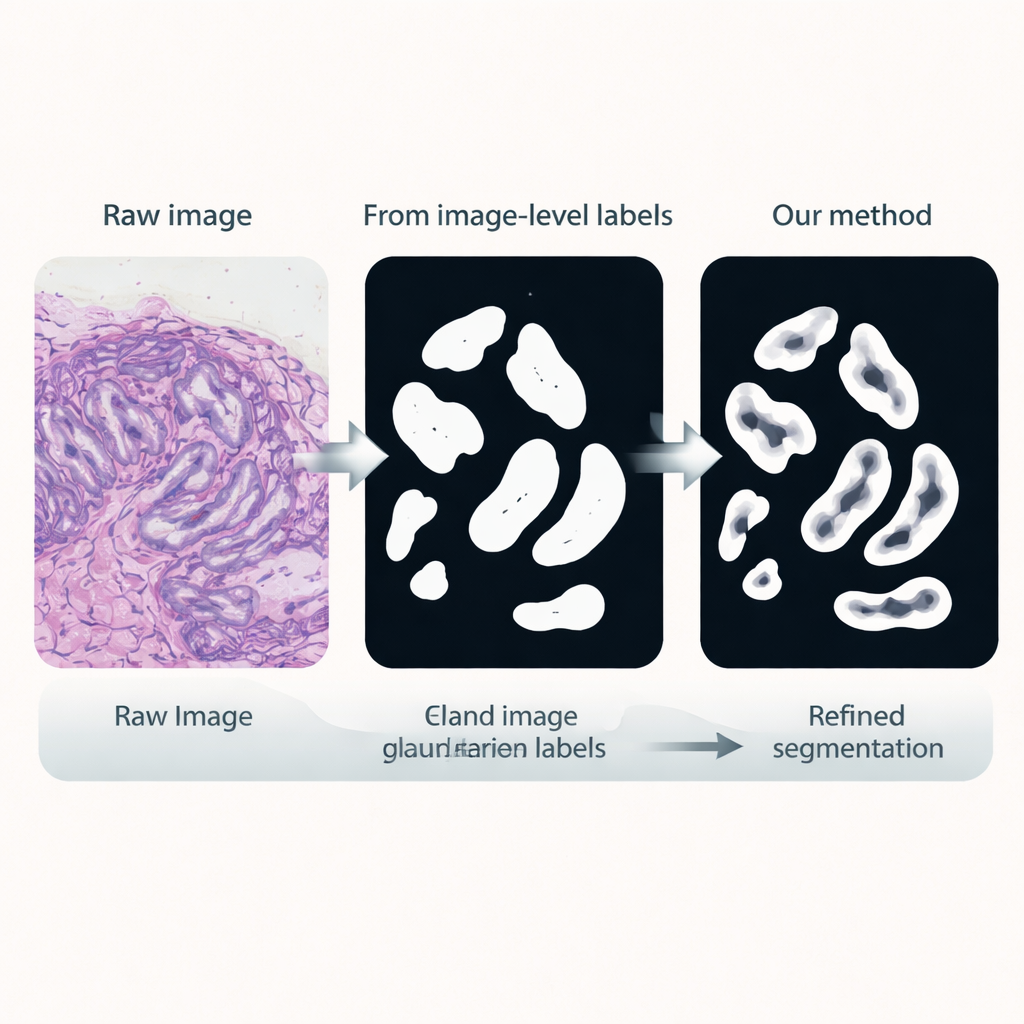
Nella seconda fase, questo encoder viene collegato a una rete di classificazione che richiede solo etichette a livello di immagine, come la presenza di ghiandole. Un meccanismo di attenzione interno alla rete impara ad assegnare pesi più alti alle regioni dell’immagine più rilevanti per la sua decisione. Queste mappe di attenzione evidenziano efficacemente dove la rete “ritiene” siano localizzate le ghiandole. I ricercatori trasformano queste mappe soft in maschere binarie approssimative tramite blending e sogliatura, poi le puliscono ulteriormente con una tecnica di smoothing probabilistica chiamata Conditional Random Field. Il risultato è un insieme di pseudo-etichette raffinate: contorni di ghiandole generati dal computer che non sono perfetti, ma sufficientemente buoni da guidare un modello di segmentazione più specializzato.
Affinare i confini delle ghiandole
Nella terza fase, una rete di segmentazione dedicata viene addestrata utilizzando queste pseudo-etichette come sostituti delle annotazioni manuali. Riutilizza l’encoder fine-tuned ma aggiunge una testa decoder leggera che riconverte le caratteristiche in una maschera dettagliata delle ghiandole. Crucialmente, la funzione di perdita usata durante l’addestramento presta particolare attenzione ai confini: gli errori che distorcono i bordi delle ghiandole sono penalizzati più dei piccoli errori nell’interno. Questo addestramento sensibile ai bordi incoraggia contorni nitidi e anatomicamente realistici, essenziali per misurare con precisione la forma e la separazione delle ghiandole.
Quanto funziona nella pratica?
Il team ha testato il metodo su due benchmark standard di tessuto colorettale. Sul dataset GlaS, il loro approccio con supervisione debole non solo ha superato altri metodi che utilizzano etichette limitate, ma in diverse misure si è avvicinato o ha superato sistemi classici completamente supervisionati che si basano su annotazioni pixel-level complete. Su un dataset più difficile chiamato CRAG, ricco di ghiandole altamente irregolari e maligne, le prestazioni sono calate per tutti i metodi, ma il nuovo framework ha comunque superato gli altri concorrenti con etichette deboli e ha ridotto il divario con i modelli pienamente supervisionati. Studi di ablation hanno mostrato che ogni componente — il fine-tuning auto-supervisionato, la pseudo-etichettatura basata su attenzione con post-processing e la perdita sensibile ai bordi — ha contribuito in modo significativo ai miglioramenti.
Cosa significa per i futuri strumenti di patologia
Per un lettore non esperto, la conclusione principale è che questo lavoro indica la strada verso sistemi di IA in grado di fornire mappe di alta qualità e con confini precisi delle strutture ghiandolari microscopiche, facendo perlopiù affidamento su semplici etichette a livello di vetrino già presenti negli archivi ospedalieri. Riducendo la dipendenza da faticose delineazioni manuali, l’approccio potrebbe rendere la classificazione avanzata basata su immagini e l’analisi quantitativa più praticabili in molti centri, aiutando i patologi a diagnosticare il cancro colorettale in modo più coerente ed efficiente, e potenzialmente estendendosi ad altri tipi di tessuto e strutture in futuro.
Citazione: Wen, H., Wu, Y., Huang, D. et al. Weakly supervised colorectal gland segmentation through self-supervised learning and attention-based pseudo-labeling. Sci Rep 16, 5771 (2026). https://doi.org/10.1038/s41598-026-36256-0
Parole chiave: cancro colorettale, patologia digitale, segmentazione delle ghiandole, apprendimento con supervisione debole, visione auto-supervisionata