Clear Sky Science · it
Sostituzione dialettale come approccio avversario per valutare la robustezza del NLP arabo
Perché l’arabo di tutti i giorni confonde i computer intelligenti
Molte applicazioni oggi leggono testo in arabo per valutare il sentiment, classificare notizie o rispondere a domande. Tuttavia questi sistemi imparano per lo più dall’arabo standard moderno (MSA), mentre le persone reali mescolano quotidianamente dialetti regionali. Questo articolo mostra come sostituire una sola parola con la forma egiziana o del Golfo possa ingannare modelli linguistici all’avanguardia, sollevando preoccupazioni per chi si affida all’IA araba in assistenza clienti, monitoraggio dei media o sicurezza online.
Una lingua, molte voci
L’arabo non è un modo di parlare unico e uniforme. L’MSA si usa nelle scuole, nei notiziari e nei testi ufficiali, ma nelle conversazioni quotidiane si fanno largo dialetti come l’egiziano e l’arabo del Golfo. Queste varietà differiscono nel lessico, nelle forme delle parole e persino nella struttura delle frasi. Per esempio, una parola semplice come “ora” assume forme molto diverse a seconda della regione. Per i lettori umani queste variazioni sono naturali e facili da comprendere. Per i modelli computazionali addestrati quasi esclusivamente su MSA, invece, le parole dialettali possono apparire estranee, trasformando una frase chiara in qualcosa di sconcertante.
Usare i dialetti come test di resistenza per l’IA
Per sondare quanto siano fragili i modelli linguistici arabi, l’autore progetta un semplice test in due fasi. Prima, il modello viene interrogato ripetutamente per individuare la singola parola in una frase che influisce di più sulla sua decisione — spesso un aggettivo marcato, un verbo chiave o un sostantivo tematico. Secondo, quella parola viene sostituita con un equivalente in arabo egiziano o del Golfo usando un grande modello «dialettizzatore» finemente messo a punto. Il resto della frase resta intatto e il significato rimane lo stesso per i lettori umani. Questo rende la frase modificata un esempio avversario realistico: una piccola modifica dall’aspetto naturale progettata per ingannare il sistema senza alterare il messaggio inteso.
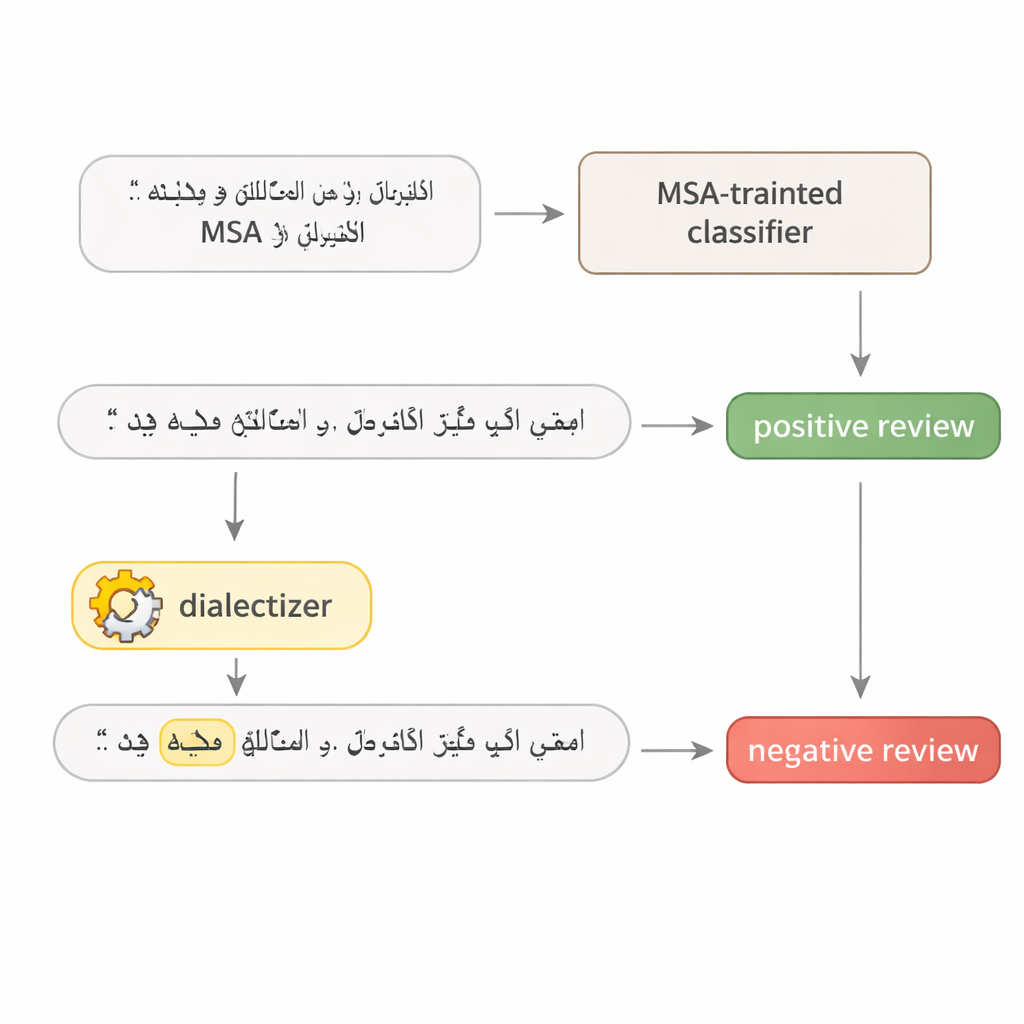
Mettere alla prova recensioni di hotel e articoli di cronaca
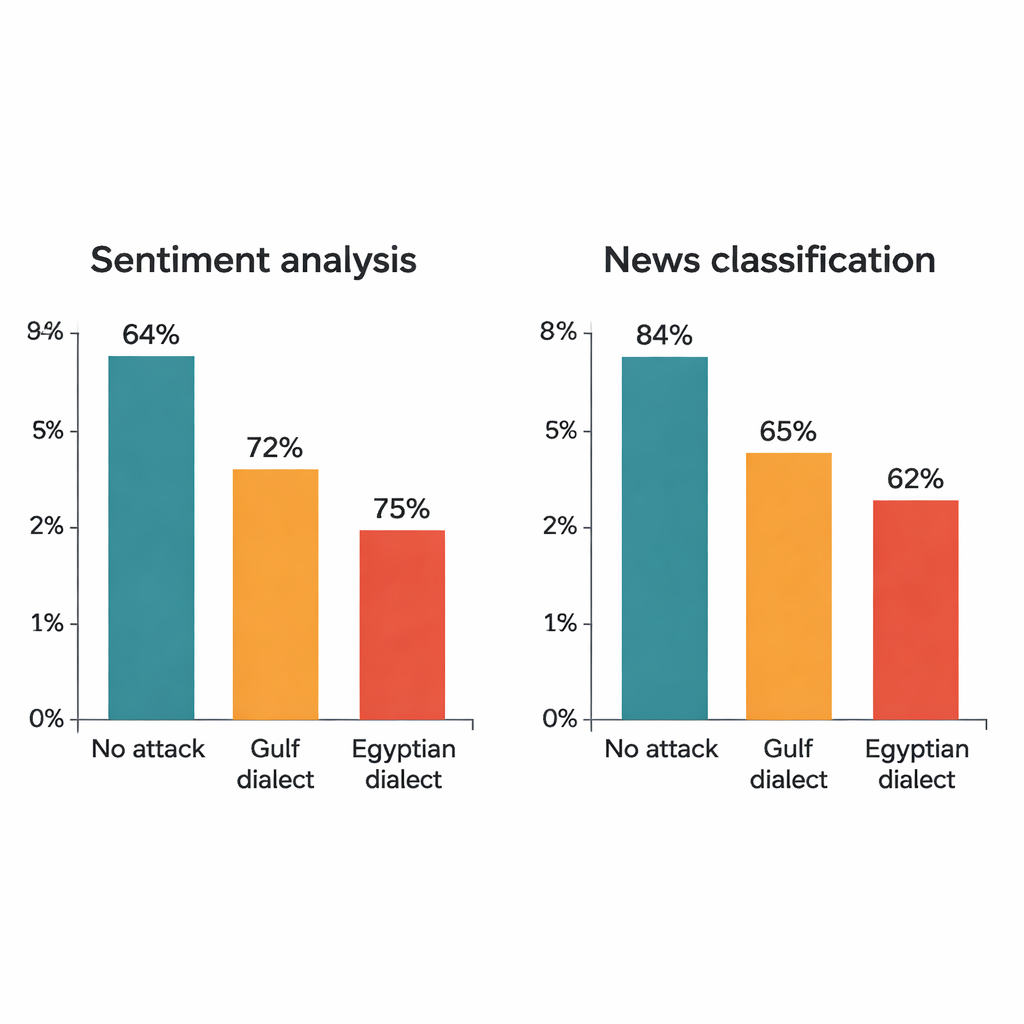
Lo studio attacca quattro modelli di deep learning noti: due grandi trasformatori (AraBERT e CAMeLBERT) e due reti più piccole (un modello convoluzionale e un LSTM bidirezionale). Sono addestrati su due importanti dataset in MSA: recensioni di hotel per l’analisi del sentiment e articoli di notizia per la classificazione tematica. Da ciascun set di test, l’autore estrae 1.280 esempi e applica la procedura di sostituzione dialettale. Anche se in ogni frase viene cambiata una sola parola, l’impatto è notevole. Nelle recensioni di hotel, l’accuratezza di AraBERT scende dal 94 percento sul testo pulito a circa il 72 percento con sostituzioni del Golfo e al 65 percento con quelle egiziane. CAMeLBERT cala ancora di più, arrivando approssimativamente al 63 e al 55 percento. Anche i classificatori di notizie risentono dell’attacco: il modello convoluzionale perde circa 18-22 punti percentuali, e l’LSTM mostra cali simili.
Cosa va storto dentro i modelli
Un’analisi più approfondita rivela che le parole più vulnerabili corrispondono a come le persone effettivamente leggono il testo. Nelle recensioni di hotel, quasi la metà delle parole mirate sono aggettivi come «buono» o «terribile», che portano chiaro peso emotivo. Negli articoli di notizia, la maggior parte delle parole selezionate sono sostantivi e nomi che segnalano argomenti come politica, sport o finanza. Quando quelle parole-scatola vengono sostituite con forme dialettali, i modelli addestrati solo su MSA spesso non le riconoscono. I modelli transformer si dimostrano particolarmente fragili: la loro dipendenza da frammenti subword e l’attenzione concentrata su alcuni token altamente ponderati rendono una singola parola dialettale sufficiente a ribaltare una predizione. I modelli più piccoli, che distribuiscono l’attenzione in modo più uniforme sulla frase, vengono comunque ingannati ma risultano leggermente più robusti.
Egiziano vs Golfo: non tutti i dialetti sono uguali
Gli attacchi mostrano anche che l’arabo egiziano tende a mandare più spesso in crisi i modelli rispetto all’arabo del Golfo. Studi linguistici lo confermano: le varietà del Golfo spesso restano più vicine all’MSA nel lessico e nella struttura, mentre l’egiziano ha assorbito forme più distintive dalla storia e dai contatti con altre lingue. Di conseguenza, le sostituzioni del Golfo a volte somigliano abbastanza all’originale in MSA da permettere al modello di cavarsela, mentre le sostituzioni egiziane hanno maggiori probabilità di cadere al di fuori di ciò che il modello ha visto in precedenza. Test statistici confermano che i cali di prestazione osservati non sono casuali: riflettono punti ciechi sistematici nel modo in cui i sistemi attuali gestiscono la diglossia araba.
Cosa significa per l’IA in arabo
Per gli utenti di tutti i giorni, la conclusione è semplice: l’IA araba odierna può essere facilmente confusa da parole dialettali ordinarie, anche quando gli esseri umani trovano il testo perfettamente chiaro. Un singolo termine dialettale in una recensione di hotel può ribaltare il giudizio di un modello da positivo a negativo, o etichettare erroneamente il tema di una notizia. Per ricercatori e sviluppatori, il messaggio è un invito a costruire sistemi «consapevoli della diglossia» che si addestrino sia su MSA sia sui dialetti regionali, e a usare test di stress realistici come la sostituzione dialettale per valutare la robustezza. Fino ad allora, qualsiasi applicazione che presuma «l’arabo è solo MSA» corre il rischio di gravi incomprensioni sul campo.
Citazione: Alshemali, B. Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness. Sci Rep 16, 5996 (2026). https://doi.org/10.1038/s41598-026-36252-4
Parole chiave: NLP arabo, variazione dialettale, esempi avversari, analisi del sentiment, classificazione del testo