Clear Sky Science · it
Previsione della qualità delle acque superficiali tramite una rete neurale ibrida MLA-Mamba con ottimizzazione GRPO
Perché è importante prevedere lo stato dei fiumi
I fiumi e i laghi sono le nostre fonti di acqua potabile, le riserve per l’irrigazione e gli habitat per la fauna. Tuttavia la loro qualità può cambiare rapidamente quando l’inquinamento arriva da fattorie, fabbriche o città. Le autorità spesso lo scoprono solo dopo che il danno è già avvenuto. Questo studio esplora come l’intelligenza artificiale moderna possa funzionare come un sistema di allerta precoce intelligente, prevedendo variazioni della qualità dell’acqua con giorni di anticipo in modo che i gestori abbiano il tempo di intervenire.
Strumenti vecchi, problemi nuovi
Per decenni gli scienziati hanno cercato di prevedere la qualità dell’acqua usando formule matematiche e statistiche tradizionali. Questi metodi o simulano la chimica e il flusso in grande dettaglio o adattano misure passate con curve relativamente semplici. Entrambi gli approcci faticano con la realtà disordinata dei fiumi, dove meteo, scarichi a monte e attività biologiche interagiscono in modi complessi e non lineari. Spesso mancano picchi improvvisi di inquinamento o non riescono a tenere conto di come le condizioni in una stazione di monitoraggio si propagano a valle verso un’altra. Di conseguenza, le previsioni possono risultare troppo approssimative per decisioni sicure.
Insegnare a una rete neurale a leggere un fiume
Gli autori propongono un nuovo modello di deep learning, chiamato MLA-Mamba, progettato specificamente per questo intreccio di spazio e tempo. Invece di guardare un singolo sensore isolatamente, il modello assume una settimana di dati orari da più stazioni di monitoraggio, insieme a informazioni di supporto come temperatura dell’acqua, portata e acidità. Impara quindi a prevedere quattro indicatori chiave che segnalano inquinamento organico e carico di nutrienti: un indice di domanda chimica di ossigeno (CODMn), ammoniaca (NH3–N), fosforo totale (TP) e azoto totale (TN). Il modello combina due componenti specializzate. Una si concentra sui pattern nel tempo, riconoscendo cicli, derive lente ed effetti ritardati. L’altra osserva lo spazio, apprendendo come le stazioni a monte e vicine si muovono insieme. Fondendo queste prospettive, la rete costruisce un quadro più ricco di come evolve la qualità dell’acqua.
Catturare trend temporali e influenza a monte
All’interno del framework MLA-Mamba, il modulo “Mamba” si concentra sulla dimensione temporale. Scansiona lunghe sequenze di misure, usando idee dai modelli a spazio di stato e dalle moderne reti ricorrenti per mantenere informazioni di giorni precedenti senza essere sopraffatto. Questo aiuta a riconoscere schemi stagionali e impatti persistenti da disturbi passati. In parallelo, un modulo “Multi-Head Local Attention” pesa quanto ciascuna stazione è correlata alle altre in un dato istante, con una preferenza incorporata verso siti vicini nello stesso tratto di fiume. Se una stazione a monte registra improvvisamente un aumento di ammoniaca, il meccanismo di attenzione può spostare rapidamente il focus su quel segnale quando si prevedono le condizioni a valle. Una configurazione multi-task permette al modello di apprendere i quattro indicatori insieme, così che variazioni in un inquinante possano informare le previsioni per gli altri.
Allenamento più intelligente per dati ambientali rumorosi
Allenare una rete simile su registrazioni di sensori reali è complicato: i dati sono rumorosi, si verificano lacune e i metodi di ottimizzazione standard possono bloccarsi. Per affrontare questo, i ricercatori introducono una strategia di addestramento personalizzata chiamata Gradient Reparameterization Optimization (GRPO). GRPO adegua la velocità di apprendimento di ciascun parametro della rete in base al comportamento del suo gradiente nel tempo, accelerando grossolanamente nelle direzioni stabili e rallentando quando gli aggiornamenti iniziano a oscillare. Impone anche una dimensione minima del passo in modo che l’apprendimento non si arresti su parti piatte della superficie di errore. Il team sfrutta inoltre il dropout non solo per prevenire l’overfitting ma anche per stimare l’incertezza, eseguendo il modello più volte e osservando quanto variano le sue previsioni. Questo genera bande di confidenza attorno a ogni previsione, dando ai gestori un’idea di quanto sia affidabile una previsione specifica.
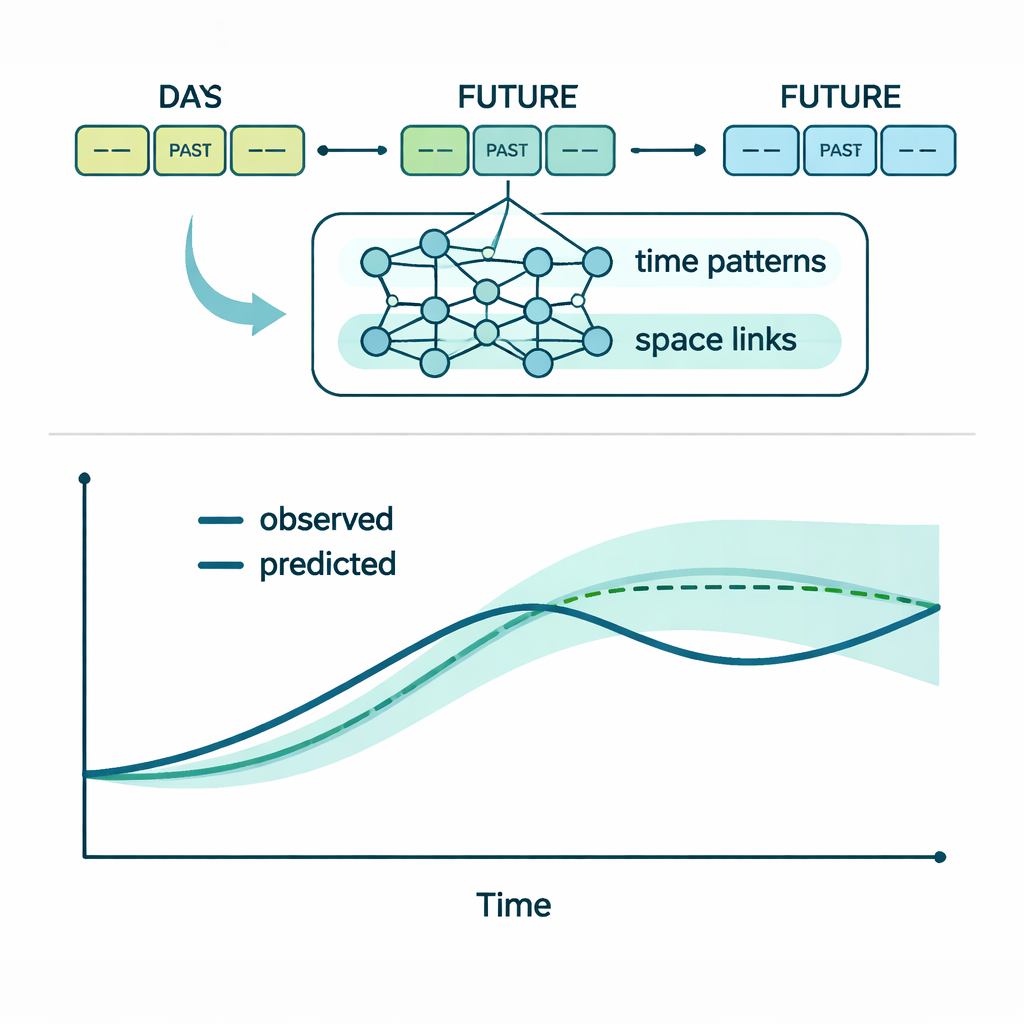
Mettere il modello alla prova
Gli autori valutano MLA-Mamba su diversi anni di dati orari provenienti da due stazioni fluviali in Cina, una a monte dell’altra. Il modello prende i sette giorni precedenti di dati e prevede i tre giorni successivi. Viene confrontato con otto alternative, che vanno da metodi statistici classici ad architetture moderne di deep learning come reti LSTM (long short-term memory), ibridi convoluzionali–ricorrenti e modelli Transformer. Su tutti e quattro gli indicatori e in entrambe le località, MLA-Mamba fornisce sistematicamente gli errori di previsione più bassi. In molti casi riduce gli errori tipici del 10–20 percento rispetto a solidi baseline di deep learning. Quando parti del modello vengono disabilitate in test controllati — rimuovendo l’attenzione spaziale, sostituendo un LSTM standard al modulo Mamba, spegnendo l’ottimizzatore GRPO o addestrando ogni indicatore separatamente — le prestazioni peggiorano in modo evidente. Questo mostra che ogni ingrediente contribuisce ai miglioramenti.
Cosa significa per la tutela delle risorse idriche
In termini pratici, lo studio dimostra che una rete neurale ibrida su misura può produrre previsioni a breve termine dell’inquinamento fluviale più accurate e affidabili rispetto agli strumenti standard attuali. Tracciando simultaneamente più inquinanti attraverso più stazioni e quantificando la sicurezza delle proprie previsioni, il framework MLA-Mamba potrebbe supportare sistemi di allerta precoce che attivano ispezioni o misure temporanee prima che vengano superate soglie critiche. Pur dipendendo ancora da dati di monitoraggio di buona qualità e dovendo essere testato su più fiumi ed eventi estremi, offre una strada promettente verso una gestione delle acque superficiali più intelligente e guidata dai dati.
Citazione: Wei, R., Chen, H. & Wang, H. Surface water quality prediction via an MLA-Mamba hybrid neural network with GRPO optimization. Sci Rep 16, 5845 (2026). https://doi.org/10.1038/s41598-026-36229-3
Parole chiave: previsione della qualità delle acque, inquinamento fluviale, deep learning, modellazione spazio-temporale, monitoraggio ambientale