Clear Sky Science · it
Modellazione del contesto a lungo raggio per il rilevamento delle vulnerabilità software usando un approccio basato su XLNet
Perché le falle nascoste nel software sono importanti
La vita moderna dipende dal software, dai servizi bancari online e dai sistemi ospedalieri ai lettori multimediali e alle app di messaggistica. Eppure anche piccoli errori nel codice possono aprire la porta agli hacker, mettendo a rischio il furto di dati o l’interruzione dei servizi. Gli esperti di sicurezza ricorrono sempre più all’intelligenza artificiale per analizzare milioni di righe di codice alla ricerca di queste debolezze. Questo articolo esplora un nuovo metodo basato su IA, chiamato XLNetVD, progettato per individuare vulnerabilità software sottili leggendo porzioni di codice molto più ampie di quelle che molti strumenti esistenti sono in grado di gestire.
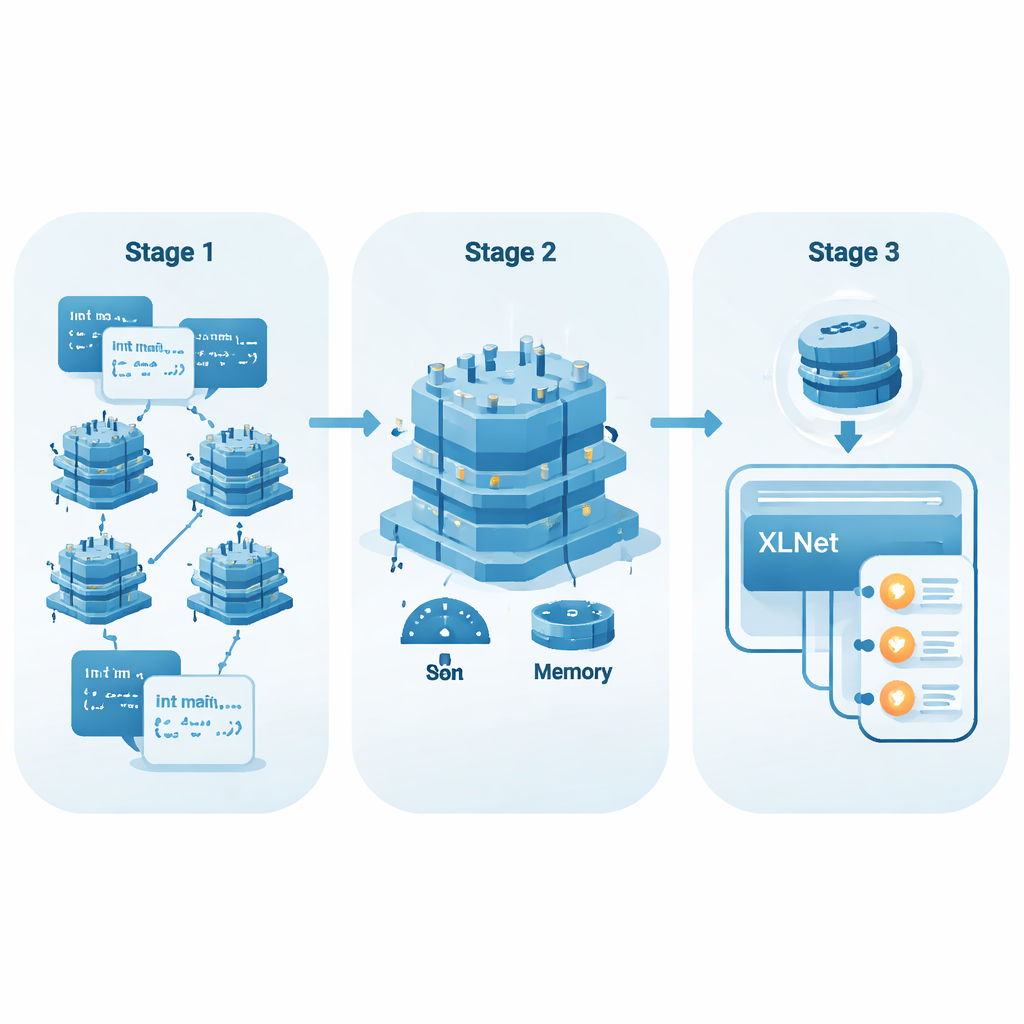
Dalle semplici liste di parole al codice che comprende il contesto
I primi metodi di IA per analizzare il codice trattavano ogni token — come il nome di una variabile o un simbolo — quasi come una parola di dizionario con un significato fisso. Tecniche come Word2Vec o GloVe imparavano un vettore per ogni token, indipendentemente dal punto in cui appariva. Questo funziona abbastanza bene per il linguaggio naturale, ma è insufficiente per i programmi, dove lo stesso nome di variabile può comportarsi in modo molto diverso a seconda di dove e come viene usato. I modelli più recenti, noti come modelli di embedding contestuali, considerano invece l’intera funzione e adattano la rappresentazione di ogni token in base al suo contesto. Questo consente loro di cogliere pattern legati al flusso dei dati, al controllo del flusso e alle dipendenze tra variabili — pattern che spesso fanno la differenza tra codice sicuro e insicuro.
Permettere all’IA di leggere più del file
Modelli di codice popolari come CodeBERT e GraphCodeBERT già adottano questo approccio contestuale, ma di solito limitano la loro “vista” a circa 512 token. Per funzioni lunghe, o per vulnerabilità suggerite in punti del codice molto distanti tra loro, quella finestra può essere troppo breve. Controlli importanti all’inizio di una funzione possono essere separati da operazioni rischiose verso la fine. Gli autori invece si basano su XLNet, un modello derivato da Transformer-XL, che può ricordare informazioni attraverso segmenti e processare sequenze più lunghe in modo confortevole (fino a 768 token nei loro esperimenti). Questo lo rende più adatto a collegare eventi distanti nel codice — per esempio capire che un valore era stato validato prima, o rendersi conto che non lo è mai stato.
Rendere potenti i modelli più leggeri e veloci
I grandi modelli di IA spesso richiedono hardware potente, il che ne limita l’uso negli ambienti di sviluppo quotidiani. Per affrontare questo problema, gli autori applicano un metodo di fine-tuning chiamato Low-Rank Adaptation (LoRA). Piuttosto che modificare tutti i numerosi parametri di XLNet, LoRA aggiunge piccoli strati adattatori che sono molto più economici da addestrare e memorizzare. Il team introduce un semplice punteggio, EffScore, che bilancia quanto memoria e tempo si risparmiano rispetto a una eventuale perdita nella qualità del rilevamento. Tra diversi modelli di riferimento, XLNet con LoRA risulta il più efficiente complessivamente, offrendo buona accuratezza consumando risorse significativamente inferiori.
Test su progetti reali e sintetici
I ricercatori valutano XLNetVD su due dataset molto diversi. Uno è composto da codice C reale proveniente da 12 progetti open-source — come librerie multimediali e server web — con un rapporto estremamente sbilanciato di circa 1 funzione vulnerabile su 65 non vulnerabili, riflettendo la realtà delle grandi basi di codice. L’altro è una raccolta sintetica bilanciata del progetto SARD, in cui ogni funzione è costruita per rappresentare un tipo di debolezza noto. XLNetVD non solo eguaglia o supera i precedenti sistemi di deep learning e gli strumenti classici di analisi statica in questi test, ma si comporta bene anche in scenari cross-project, dove deve trovare falle in un progetto mai visto prima. Il suo vantaggio è particolarmente marcato per funzioni lunghe, dove il contesto esteso è cruciale, e attraverso diverse categorie di vulnerabilità, inclusi overflow interi, cattiva gestione delle risorse e gestione impropria degli input.
Cosa significa questo per la sicurezza del software nella pratica
Per un non specialista, il messaggio principale è che un’IA più intelligente e consapevole del contesto può leggere e ragionare sul codice in modo più simile a un revisore umano esperto, ma su scala meccanica. Consentendo al modello di vedere più di ogni funzione e ottimizzandone l’addestramento, XLNetVD offre un modo pratico per dare priorità alle parti di una grande codebase che meritano un’ispezione umana più approfondita. Non sostituisce le revisioni manuali di sicurezza né i metodi formali, e non può garantire che il software sia privo di bug. Tuttavia, migliora significativamente le probabilità di individuare errori pericolosi precocemente, anche in progetti poco familiari, rendendolo un elemento promettente per infrastrutture digitali più affidabili e sicure.
Citazione: Zhao, Y., Lin, G. & Liao, Z. Long-range context modeling for software vulnerability detection using an XLNet-based approach. Sci Rep 16, 5338 (2026). https://doi.org/10.1038/s41598-026-36196-9
Parole chiave: vulnerabilità software, sicurezza del codice, deep learning, XLNet, fine-tuning LoRA