Clear Sky Science · it
Algoritmo DDPG prioritizzato modificato per l’ottimizzazione congiunta del beamforming e delle fasi RIS nei sistemi MISO downlink
Superfici intelligenti per la nuova ondata di wireless
Man mano che telefoni, auto e sensori richiedono connessioni sempre più veloci e affidabili, le reti wireless odierne vengono spinte ai loro limiti. Questo studio esplora un nuovo modo per rendere le future reti 6G più ecologiche e più affidabili combinando «superfici» riflettenti intelligenti sugli edifici con una tecnica di intelligenza artificiale che apprende autonomamente come orientare i segnali radio consumando meno energia.
Trasformare i muri in specchi utili per il segnale
I futuri sistemi 6G dovranno servire un numero enorme di dispositivi con alte velocità dati, affidabilità elevata e latenza molto bassa. Soddisfare tutte queste richieste affidandosi soltanto alle stazioni base tradizionali richiederebbe molta più apparecchiatura e consumo energetico. Le Superfici Intelligenti Riconfigurabili (RIS) offrono un approccio diverso: pannelli ricoperti da molti piccoli elementi a basso consumo che possono riflettere le onde radio in direzioni controllate, come uno specchio programmabile. Scegliendo con cura le fasi di queste riflessioni, un RIS può deviare i segnali intorno agli ostacoli, rafforzare collegamenti deboli e ridurre le interferenze, il tutto senza trasmettere attivamente potenza propria. Questo dà ai progettisti di rete una nuova leva potente per ampliare la copertura e migliorare l’efficienza.
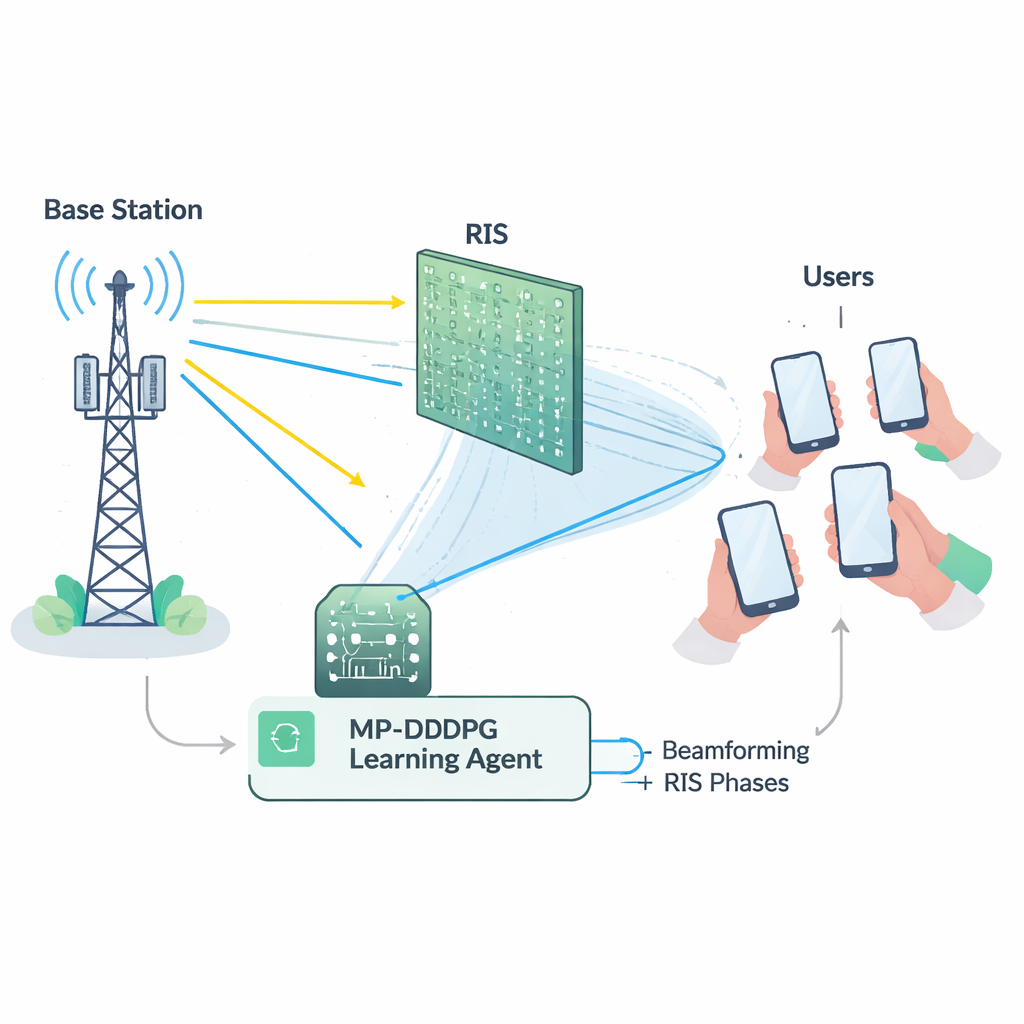
Un difficile atto di bilanciamento per la rete
Sfruttare al meglio un RIS non è banale. La stazione base deve decidere come puntare le sue antenne (beamforming), mentre il RIS deve impostare la fase di ciascuno dei suoi numerosi elementi riflettenti. Queste scelte sono strettamente correlate e devono rispettare contemporaneamente diversi vincoli: mantenere la potenza totale di trasmissione al di sotto di un massimo, garantire a ogni utente una qualità minima del segnale e rispettare i limiti fisici dell’hardware RIS. Matematicamente, questo problema di ottimizzazione congiunta è altamente non lineare e «non convesso», il che significa che gli strumenti di ottimizzazione convenzionali tendono a essere lenti, fragili o a restare intrappolati in soluzioni sub‑ottimali, specialmente al crescere della dimensione della rete. Inoltre, misurare con precisione lo stato dettagliato di ogni collegamento radio (la cosiddetta channel state information) è di per sé costoso e soggetto a errori nelle implementazioni reali.
Lasciare che un agente AI impari a fare beam
Per superare questi ostacoli, gli autori costruiscono un agente di apprendimento usando il deep reinforcement learning, un ramo dell’IA in cui un agente scopre buone strategie per tentativi ed errori interagendo con un ambiente. Il loro metodo, chiamato Modified Prioritized Deep Deterministic Policy Gradient (MP‑DDPG), osserva lo stato attuale della rete—direzioni di beam precedenti, impostazioni RIS, potenza ricevuta e qualità del segnale—e quindi sceglie nuovi valori per il beamforming e per le fasi RIS. Dopo ogni scelta riceve una ricompensa che incentiva tre aspetti contemporaneamente: una minore potenza di trasmissione, il soddisfacimento degli obiettivi di qualità del servizio per gli utenti e il rispetto del limite di potenza della stazione base. Dopo molte interazioni simulate, l’agente impara gradualmente una politica di controllo che bilancia questi obiettivi senza che venga fornita esplicitamente alcuna formula per il canale radio.
Imparare più in fretta concentrandosi su ciò che conta
L’innovazione chiave risiede nel modo in cui l’algoritmo impara dalle esperienze passate. Gli approcci standard memorizzano molte situazioni passate e le campionano casualmente durante l’addestramento, il che può essere dispendioso e lento. MP‑DDPG invece assegna a ogni esperienza memorizzata una priorità che dipende sia dalla sua ricompensa sia da quanto il suo stato è diverso rispetto ai vicini più prossimi. Le esperienze che sono informativamente rilevanti e diversificate vengono campionate più spesso, mentre quelle ridondanti vengono ignorate. Questa «riproduzione prioritizzata modificata» rende ogni passo di apprendimento più utile, accelerando la convergenza e aiutando l’agente a evitare pessime soluzioni locali. Gli autori analizzano anche il costo computazionale aggiuntivo e mostrano che, sebbene la gestione sia più complessa rispetto al metodo base, l’apprendimento più rapido lo compensa ampiamente nella pratica.
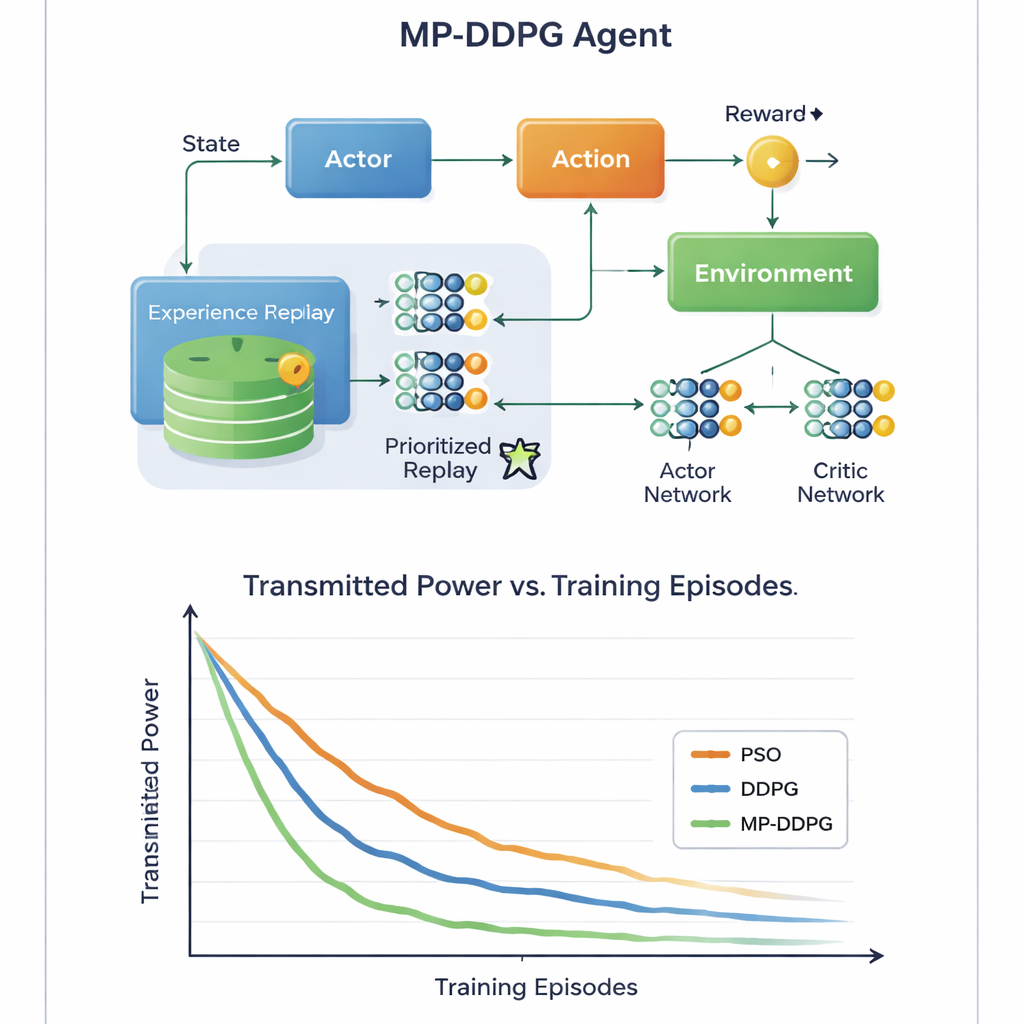
Segnali più verdi con meno hardware
Attraverso simulazioni al computer dettagliate di uno scenario cellulare downlink, lo studio confronta MP‑DDPG con due alternative: un metodo tradizionale di ottimizzazione a sciame di particelle e l’algoritmo DDPG originale. Il nuovo metodo raggiunge costantemente una potenza di trasmissione inferiore in meno episodi di addestramento, e lo fa usando meno elementi RIS e meno antenne nella stazione base per lo stesso livello di prestazioni. In termini semplici, la rete impara a ottenere più beneficio da ogni tassello riflettente e da ogni antenna. Per un lettore non tecnico, il messaggio è che lasciando a un controllore AI il compito di sintonizzare in modo intelligente sia i beam della stazione base sia le superfici intelligenti sui muri vicini, le future reti 6G potrebbero fornire segnali forti e affidabili usando meno energia e meno hardware, contribuendo a rendere il nostro mondo sempre più connesso più sostenibile.
Citazione: Shukry, S., Fahmy, Y. Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems. Sci Rep 16, 5942 (2026). https://doi.org/10.1038/s41598-026-36179-w
Parole chiave: superficie intelligente riconfigurabile, wireless 6G, apprendimento profondo per rinforzo, ottimizzazione del beamforming, reti ad alta efficienza energetica