Clear Sky Science · it
Predizione con machine learning della dipendenza da cibo negli studenti universitari usando dati demografici, antropometrici e tratti di personalità
Perché il nostro rapporto con il cibo può sembrare fuori controllo
Molte persone scherzano sull’essere “dipendenti” dal cioccolato o dal cibo spazzatura, ma per alcuni i desideri compulsivi e la perdita di controllo nel mangiare sono problemi seri e angoscianti. Gli studenti universitari sono particolarmente vulnerabili, alle prese con stress, nuove libertà e cambiamenti corporei. Questo studio pone una domanda attuale: i programmi informatici possono imparare a individuare quali studenti sono a maggior rischio di dipendenza da cibo, utilizzando informazioni semplici sul loro background, misure corporee e personalità? Se sì, potremmo un giorno intercettare prima i problemi e offrire supporto mirato prima che le abitudini alimentari degenerino in problemi di salute a lungo termine.
Osservare gli studenti da più angolazioni
I ricercatori hanno lavorato con 210 studenti universitari ad Ahvaz, in Iran, di età compresa tra 18 e 35 anni. Ogni studente ha fornito dettagli di base come età e livello di istruzione, ha dichiarato altezza e peso per calcolare l’indice di massa corporea (BMI) e ha compilato un questionario standard sulla personalità. È stata inoltre somministrata una versione breve della Yale Food Addiction Scale, che classifica se una persona mostra schemi simili alla dipendenza verso alimenti altamente palatabili, come desideri intensi, tentativi falliti di ridurre il consumo o mangiare nonostante conseguenze negative. Soltanto 30 studenti soddisfacevano i criteri per la dipendenza da cibo, mentre 180 non lo facevano, rispecchiando come tali problemi interessino una quota più piccola della popolazione.
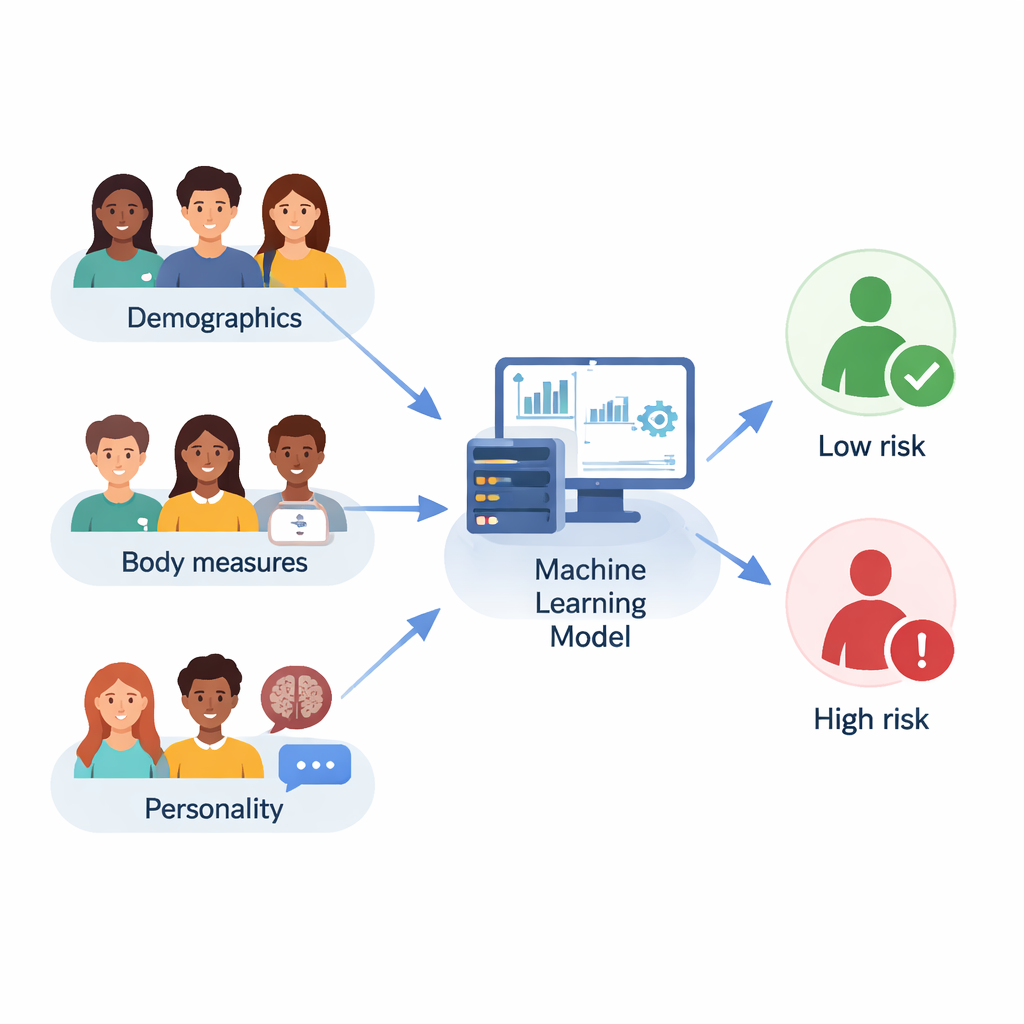
Bilanciare dati squilibrati e addestrare macchine intelligenti
Poiché molti meno studenti erano classificati come dipendenti dal cibo, il dataset risultava sbilanciato. Questo squilibrio può indurre i modelli informatici a prevedere per lo più il gruppo di maggioranza ignorando la minoranza ad alto rischio. Per contrastare ciò, il team ha usato due tecniche per la gestione dei dati. Prima hanno applicato il metodo Tomek Links per rimuovere con cura i casi del gruppo di maggioranza che si trovavano troppo vicino ai casi della minoranza. Poi hanno impiegato SMOTE, che crea esempi sintetici realistici della minoranza, per pareggiare i numeri. Solo i dati di addestramento sono stati modificati in questo modo; un gruppo di test separato e intatto è stato tenuto da parte per verificare come i modelli si comportassero su studenti nuovi e non visti.
Mettere alla prova numerosi algoritmi
I ricercatori non si sono affidati a un’unica ricetta matematica. Hanno invece confrontato dieci diversi modelli di machine learning, da metodi semplici come la regressione logistica e k‑nearest neighbors a metodi “ensemble” più avanzati come Random Forest, Gradient Boosting, LightGBM e CatBoost. Hanno anche provato dodici strategie di selezione delle feature per decidere quali domande e misure fossero più informative, e hanno usato cross‑validation e ricerche automatizzate per ottimizzare i parametri di ciascun modello. La performance complessiva è stata giudicata usando diverse misure, tra cui accuratezza (quanto spesso il modello aveva ragione), F1‑score (un equilibrio tra il cogliere i casi veri senza troppi falsi allarmi) e l’area sotto la curva ROC, che cattura quanto bene un modello separa individui a rischio più elevato da quelli a rischio più basso.
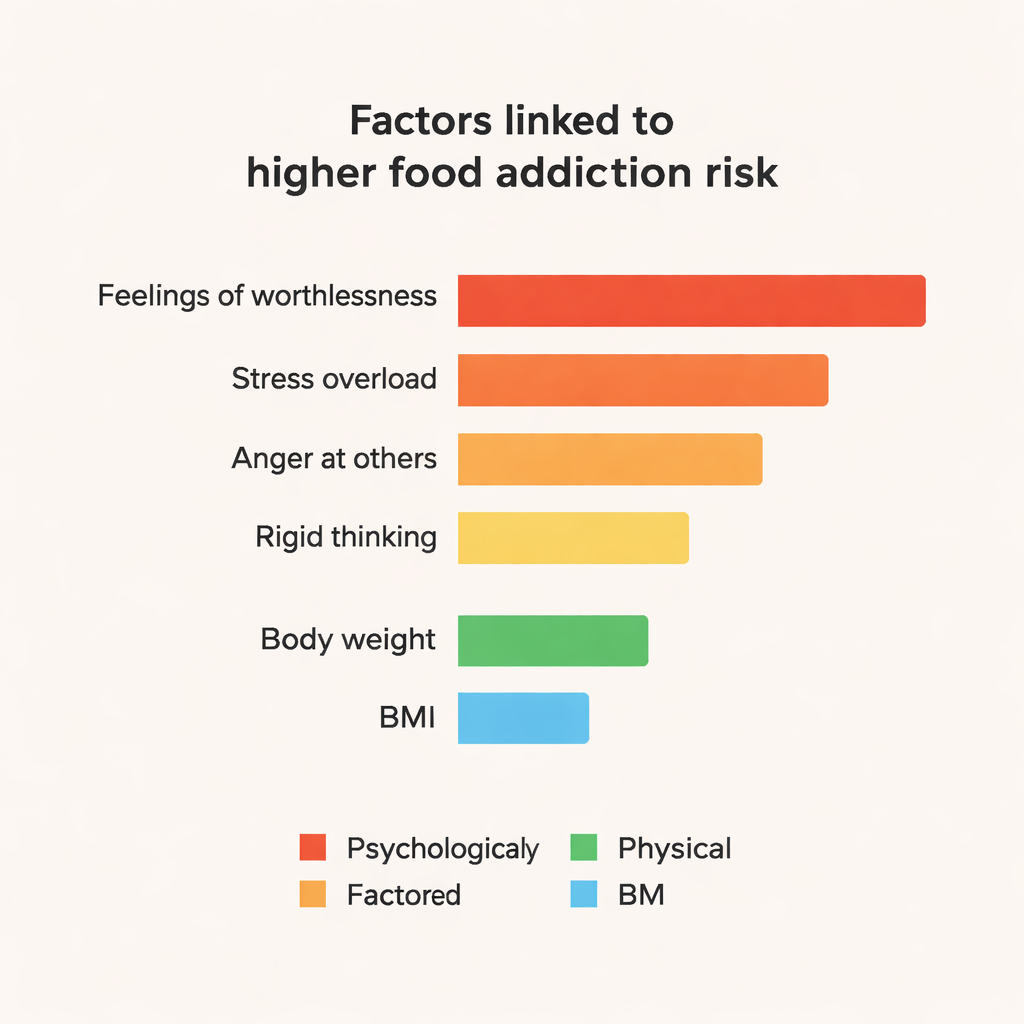
Cosa guida le predizioni sotto il cofano
I modelli ensemble, in particolare CatBoost e Random Forest, hanno costantemente superato gli approcci più semplici, raggiungendo circa l’84% di accuratezza e F1‑score intorno a 0,84 in questo piccolo dataset. Per andare oltre le predizioni “scatola nera”, il team ha utilizzato uno strumento chiamato SHAP per esplorare quali feature spingessero il modello a etichettare qualcuno come dipendente dal cibo. Le influenze principali erano di natura psicologica: affermazioni forti come “A volte mi sento completamente inutile”, sentirsi come se si stesse “sfaldando” sotto stress, frequente rabbia per come gli altri li trattano, tensione emotiva e pensiero rigido e inflessibile. Anche il peso corporeo e il BMI contavano, ma erano meno centrali rispetto a questi segnali emotivi e legati alla personalità. Tratti associati a umore positivo e buona organizzazione mostravano un lieve effetto protettivo.
Che cosa significa per la vita di tutti i giorni
Per il lettore medio, il messaggio chiave è che la dipendenza da cibo non riguarda semplicemente la forza di volontà o il gradimento di snack gustosi. In questo gruppo pilota di studenti, difficoltà emotive più profonde — bassa autostima, difficoltà a gestire lo stress e relazioni tese — erano strettamente intrecciate con comportamenti alimentari problematici. Versioni iniziali di strumenti di machine learning, alimentate da questionari di base e misure corporee, sono state in grado di cogliere questi schemi con un’accuratezza incoraggiante. Tuttavia, gli autori sottolineano che il campione era piccolo, basato su auto‑segnalazioni e tratto da una singola università, quindi i risultati sono preliminari. Con studi più ampi e diversificati, modelli simili potrebbero infine essere usati insieme alle valutazioni cliniche standard per individuare i giovani che potrebbero beneficiare di supporto nella gestione sia delle emozioni sia delle abitudini alimentari.
Citazione: Rahimnezhad, A., Mortazavi, S.T., Behdarvand, Y. et al. Machine learning prediction of food addiction in university students using demographic, anthropometric and personality traits. Sci Rep 16, 6745 (2026). https://doi.org/10.1038/s41598-026-36162-5
Parole chiave: dipendenza da cibo, studenti universitari, tratti di personalità, machine learning, alimentazione emotiva