Clear Sky Science · it
Integrazione di ottimizzazione e apprendimento automatico per stimare la resistività dell’acqua e la saturazione in giacimenti di sabbie argillitose
Perché è importante per l’energia e l’ambiente
Le compagnie petrolifere e del gas si affidano alle misure prese lungo un foro di perforazione per decidere dove si nascondono gli idrocarburi e se un giacimento vale la pena di essere sviluppato. In molti giacimenti, specialmente quelli ricchi di argilla e limo, queste misure sono notoriamente difficili da interpretare, perciò gli ingegneri possono sottostimare la quantità reale di petrolio o gas. Questo studio propone un nuovo modo per estrarre informazioni più affidabili dai dati esistenti combinando ottimizzazione basata sulla fisica e moderno apprendimento automatico, migliorando potenzialmente il recupero e riducendo la necessità di costosi campioni di carote.
Il problema delle rocce fangose
Molti dei giacimenti di idrocarburi nel mondo sono “sabbie argillitose” – miscele di granuli di sabbia, fluidi di poro e minerali argillosi conduttivi. Queste argille distorcono le misure elettriche usate per stimare quanto dello spazio di pori della roccia è riempito da acqua rispetto agli idrocarburi. Gli strumenti e i diagrammi classici, sviluppati per sabbie più pulite, assumono strutture rocciose semplici e poca argilla. Nelle sabbie argillitose, tali assunzioni falliscono, facendo spesso apparire le rocce più sature d’acqua di quanto non siano, portando gli ingegneri a scartare intervalli che potrebbero invece contenere quantità significative di petrolio o gas.
Trasformare misure scarse in un ancoraggio solido
Gli autori affrontano una grandezza centrale chiamata resistività dell’acqua di formazione, che descrive quanto bene l’acqua nei pori conduce l’elettricità. Se questo valore è sbagliato, ogni successiva stima della saturazione dell’acqua risulterà distorta. Invece di fare affidamento su poche misure di laboratorio o su metodi grafici soggettivi, pongono il problema come un compito di ottimizzazione: trovare il valore unico di resistività dell’acqua che rende un modello fisico per sabbie argillitose il più aderente possibile alla resistività misurata lungo il pozzo. Testano diversi algoritmi di ricerca e mostrano che metodi semplici, privi di derivate, come Powell e Nelder–Mead possono recuperare la vera resistività dell’acqua con errori estremamente piccoli se confrontati con dati di carote e campioni d’acqua provenienti da 11 pozzi nel Mare del Nord norvegese e nel Deserto Occidentale egiziano.
Creare un registro “pseudo-carota” per l’apprendimento automatico
Una volta ottenuta questa resistività dell’acqua ottimizzata, lo stesso modello fisico viene usato per calcolare un profilo continuo di saturazione dell’acqua lungo ogni pozzo. Questo profilo è trattato come un’etichetta di alta qualità e informata dalla fisica – una sorta di “pseudo-carota” – che esiste a ogni profondità, non solo in pochi intervalli campionati. I ricercatori quindi forniscono i log standard di pozzo, come gamma ray, porosità neutronica, densità e resistività profonda, a un’ampia gamma di modelli di apprendimento automatico. Questi includono ensemble basati su alberi (Random Forest, XGBoost, CatBoost), macchine a vettori di supporto e diverse architetture di reti neurali, compresa una rete ricorrente speciale chiamata LSTM che può riconoscere pattern che si evolvono con la profondità. Una cura nella pre-elaborazione, nel filtraggio degli outlier e nella normalizzazione aiuta a garantire che i modelli apprendano relazioni geologiche genuine piuttosto che rumore.
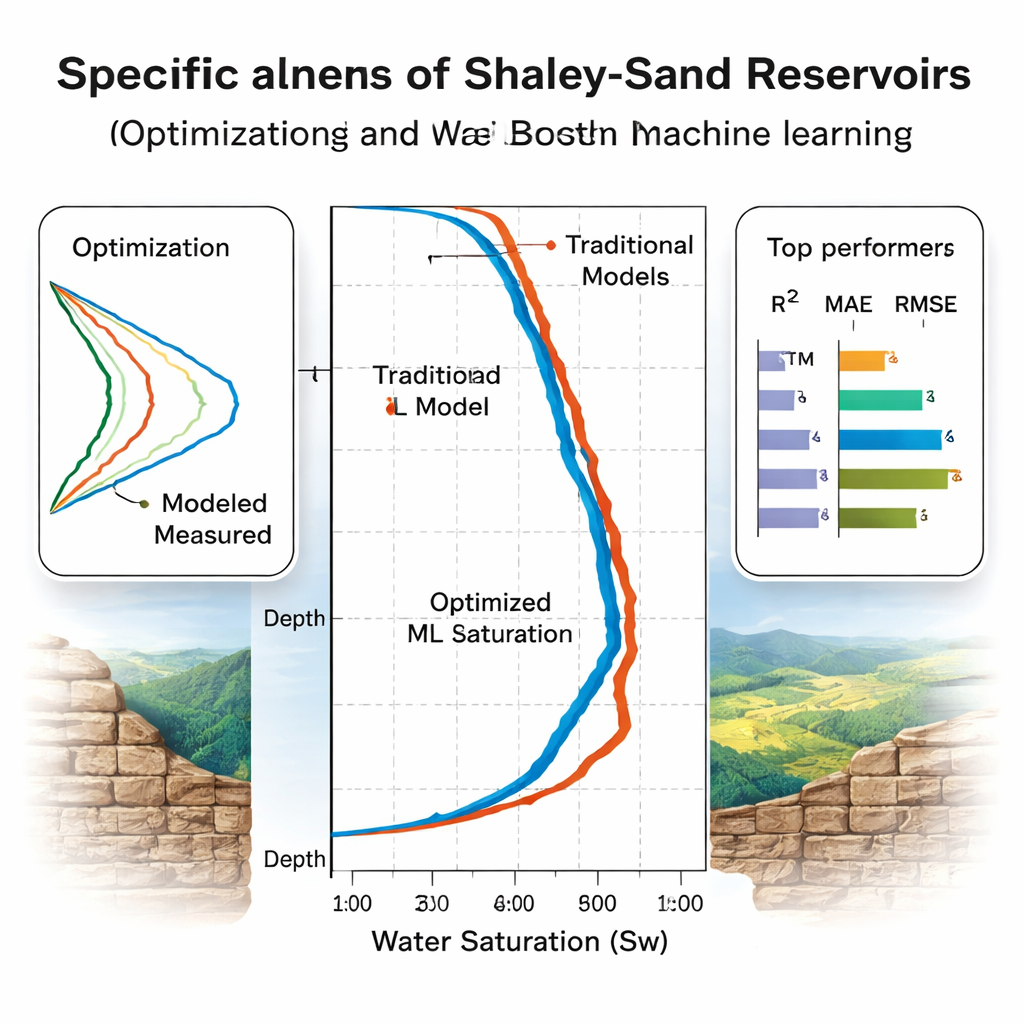
Quali modelli generalizzano davvero?
Il team valuta i modelli in due fasi. Prima, usa una validazione incrociata a cinque fold su otto pozzi del Mare del Nord per ottimizzarli e classificarli, trovando che Random Forest sembra vincere sulle metriche di accuratezza standard. Poi viene la prova più rivelatrice: tre pozzi “alla cieca”, inclusi due provenienti da un bacino geologicamente diverso in Egitto che non sono mai stati usati per l’addestramento. Qui alcuni modelli vacillano. Le prestazioni di Random Forest calano, segnalando un overfitting al bacino originale. Al contrario, gli alberi con gradient boosting (CatBoost e XGBoost) e le reti neurali LSTM e quelle regolarizzate in chiave bayesiana mantengono alta l’accuratezza, spiegando oltre il 93–94% della variazione della saturazione dell’acqua con errori modesti. L’analisi dell’importanza delle caratteristiche usando SHAP, uno strumento moderno di interpretabilità, conferma che i modelli fanno maggior affidamento su input fisicamente sensati come resistività, porosità e volume di argilla.
Che cosa significa in termini pratici
Per i non specialisti, l’idea chiave è che gli autori prima usano la fisica per ripulire e ancorare il problema e solo successivamente applicano l’apprendimento automatico. Consentendo a una routine di ottimizzazione di trovare la resistività dell’acqua più aderente e trasformando quella soluzione in un set di addestramento denso e coerente con la fisica, evitano il collo di bottiglia tipico rappresentato dalla scarsità e dal costo delle carote. I loro risultati mostrano che questo approccio “prima ottimizzazione, poi ML” può fornire stime affidabili di quanto di un giacimento argilloso sia riempito di acqua rispetto agli idrocarburi, anche in bacini nuovi non usati per l’addestramento. In termini pratici, questo può aiutare gli operatori a mappare le zone produttive in modo più affidabile, ridurre carote inutili e migliorare le stime degli idrocarburi in posto – tutto facendo un uso più intelligente dei dati che già raccolgono.
Citazione: Hameedy, M.A.E., Mabrouk, W.M. & Metwally, A.M. Integrating optimization and machine learning for estimating water resistivity and saturation in shaley sand reservoirs. Sci Rep 16, 6342 (2026). https://doi.org/10.1038/s41598-026-36133-w
Parole chiave: giacimenti di sabbie argillitose, saturazione dell’acqua, resistività dell’acqua di formazione, apprendimento automatico in petrofisica, caratterizzazione del giacimento