Clear Sky Science · it
Fusione di caratteristiche spazio-temporali guidata dall’attenzione per il rilevamento robusto di anomalie in videosorveglianza
Perché le telecamere più intelligenti sono importanti
Dalle affollate stazioni ferroviarie ai centri commerciali, la vita moderna è piena di telecamere di sicurezza che registrano silenziosamente tutto ciò che accade. Eppure la maggior parte di questi video viene ancora visualizzata—se mai lo è—da occhi umani affaticati che possono facilmente perdere un momento cruciale. Questo articolo esplora un nuovo tipo di sistema di sorveglianza “intelligente” in grado di individuare automaticamente comportamenti insoliti o a rischio, come furti o atti di vandalismo, in tempo reale comprendendo sia cosa appare in una scena sia come cambia nel tempo.

Vedere oltre i pixel
Un flusso video tradizionale è solo una sequenza di immagini. I sistemi informatici più vecchi cercavano di rilevare problemi osservando ogni singolo fotogramma separatamente, cercando forme e contorni che assomigliassero a persone o oggetti. Gli autori testano prima una versione moderna di questa idea che utilizza una rete di riconoscimento delle immagini compatta combinata con classici rilevatori di bordi. Questa configurazione funziona abbastanza bene in scene ben inquadrate, soprattutto per notare indizi visivi chiari come qualcuno che afferra un oggetto. Ma poiché si concentra su istantanee singole, fatica quando le persone si sovrappongono, quando la folla è densa o quando la stessa posa può significare comportamento normale o sospetto a seconda di come si sviluppa nel tempo.
Comprendere il movimento e il comportamento
Per catturare la storia dietro un’azione, non solo l’aspetto di un singolo fotogramma, lo studio valuta poi un modello focalizzato sui video che analizza brevi clip anziché immagini statiche. Questo modello apprende come il movimento scorre attraverso più fotogrammi e può identificare meglio cambiamenti improvvisi come la fuga, una colluttazione o uno strappo. Si dimostra efficace nel cogliere molti eventi anomali, il che porta a un’alta sensibilità. Tuttavia, soffre anche di un problema classico del mondo reale: gli eventi veramente insoliti sono rari rispetto alle attività quotidiane. Di conseguenza, il modello può diventare instabile, generando troppe falsi allarmi e richiedendo segmenti video pre-tagliati con cura che non riflettono la natura disordinata e continua delle riprese di sorveglianza reali.
Combinare dove e quando
Sfruttando punti di forza e limiti di questi due approcci di riferimento, gli autori propongono un nuovo sistema ibrido chiamato HybridModel-1 che mira a “pensare” contemporaneamente nello spazio e nel tempo. Combina una rete molto capace di comprendere quali oggetti sono presenti in ciascun fotogramma con un rilevatore veloce che localizza quegli oggetti nella scena. Un modulo di fusione speciale impara a enfatizzare i dettagli visivi più informativi—come le persone e gli oggetti chiave—riducendo al contempo il rumore di fondo come pareti, alberi o auto di passaggio. Allo stesso tempo, una nuova strategia di addestramento penalizza delicatamente il sistema ogni volta che la sua confidenza salta in modo brusco da un fotogramma al successivo, spingendolo verso decisioni più fluide e coerenti lungo l’intero video.
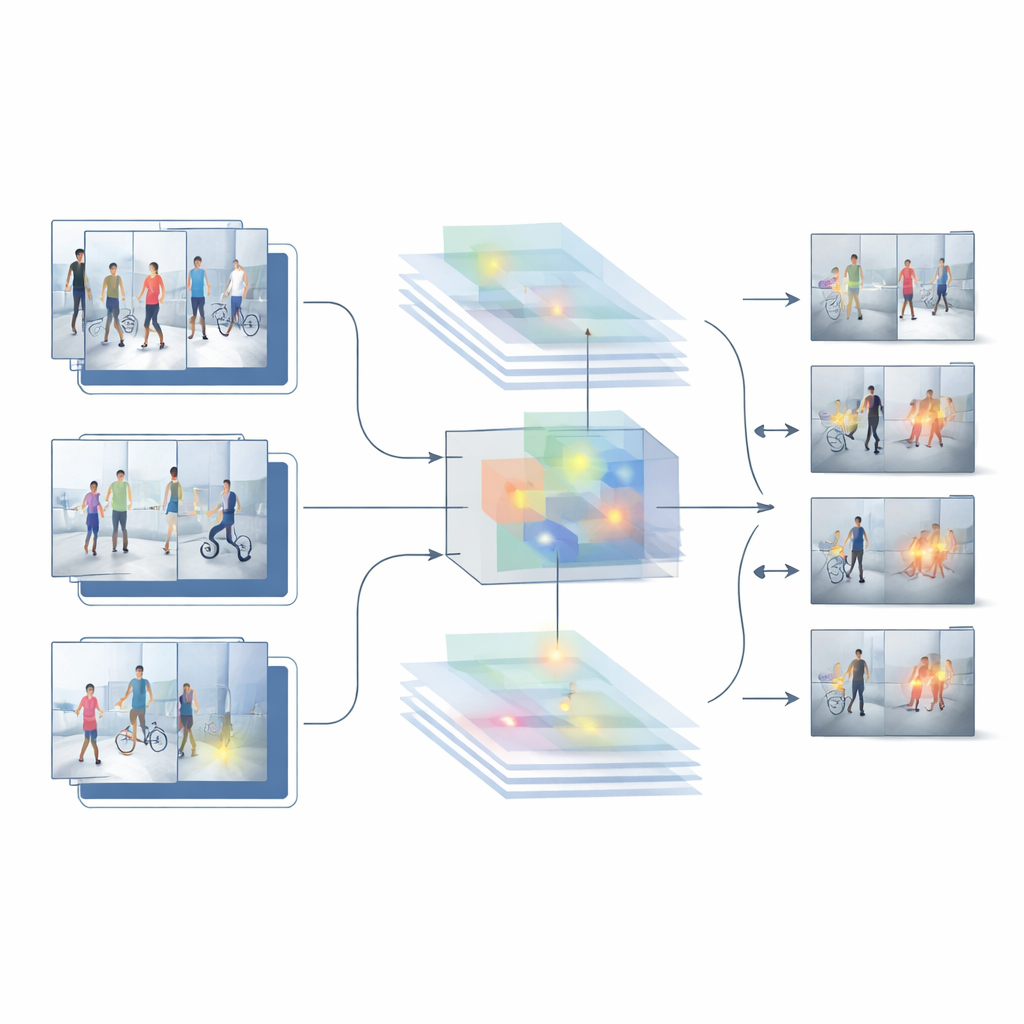
Mettere alla prova il sistema
Per verificare se questo progetto funziona al di fuori del laboratorio, i ricercatori lo testano su diversi set di dati pubblici e difficili composti da riprese di sorveglianza reali. Queste raccolte includono scene di furto indoor così come passaggi all’aperto nelle aree universitarie, con posizioni delle telecamere, illuminazione, densità di folla e tipi di incidenti variabili. Su questi benchmark, il modello ibrido surclassa sia le soluzioni basate solo su immagini sia quelle basate solo sui video. Raggiunge una maggiore accuratezza complessiva, produce molti meno falsi allarmi e mantiene prestazioni solide anche quando valutato su riprese su cui non è stato addestrato. Confronti dettagliati e studi di ablazione—dove parti del sistema sono rimosse o modificate—mostrano che il modulo di fusione delle caratteristiche e il passaggio di addestramento focalizzato sulla scorrevolezza contribuiscono in modo significativo a questi miglioramenti.
Cosa significa per la sicurezza quotidiana
In termini semplici, questo lavoro dimostra che i sistemi di sorveglianza diventano più affidabili quando imparano a prestare attenzione alle parti giuste di una scena e a mantenere giudizi stabili nel tempo. Invece di trattare ogni fotogramma come un’immagine isolata o affidarsi esclusivamente al movimento grezzo, l’approccio proposto fonde il “cosa” e il “quando” in un unico quadro accuratamente calibrato. Sebbene rimangano sfide in condizioni di oscurità estrema o viste fortemente occluse, i risultati suggeriscono una strada pratica verso reti di telecamere in grado di analizzare silenziosamente grandi quantità di video, far emergere eventi veramente sospetti e ridurre il carico di falsi allarmi per gli operatori umani. Per il pubblico, ciò potrebbe significare spazi più sicuri monitorati da sistemi che non si limitano a guardare, ma comprendono davvero ciò che vedono.
Citazione: Nivethika, S.D., Joshi, S., Verma, K. et al. Attention-guided saptio-temporal feature fusion for robus video surveillance anomaly detection. Sci Rep 16, 8027 (2026). https://doi.org/10.1038/s41598-026-36130-z
Parole chiave: videosorveglianza, rilevamento anomalie, telecamere intelligenti, rilevamento crimini, apprendimento automatico