Clear Sky Science · it
Framework ibrido di deep learning per la classificazione accurata di dati genomici ad alta dimensionalità
Comprendere l’ondata di dati genomici
Le tecnologie moderne per il DNA possono misurare decine di migliaia di geni in un unico esperimento, promettendo diagnosi più precoci e terapie più mirate. Eppure questa ricchezza di dati è così vasta, rumorosa e complessa che anche modelli computazionali potenti faticano spesso a trovare pattern chiari e affidabili. Questo articolo introduce un nuovo tipo di sistema di intelligenza artificiale (IA) progettato appositamente per gestire dati genomici così schiaccianti, con l’obiettivo di rendere le predizioni più accurate e allo stesso tempo spiegare come queste predizioni sono state ottenute.
Perché i dati genomici sono così difficili da usare
Gli studi genomici producono di routine molte più misurazioni rispetto al numero di pazienti o campioni disponibili. Molte di queste misure sono irrilevanti, ridondanti o distorte da rumore tecnico. I metodi di machine learning tradizionali richiedono o che esperti umani selezionino manualmente quali geni potrebbero essere importanti, oppure tentano di usare tutto correndo il rischio di overfitting — ovvero ottenere buoni risultati sui dati di addestramento ma fallire sui casi nuovi. Il deep learning, che ha trasformato campi come il riconoscimento delle immagini, può apprendere automaticamente pattern dai dati grezzi. Tuttavia, in genomica spesso si comporta come una scatola nera: può fornire risposte accurate, ma offre poche spiegazioni sul perché, limitando la sua accettazione in medicina dove la trasparenza è essenziale.
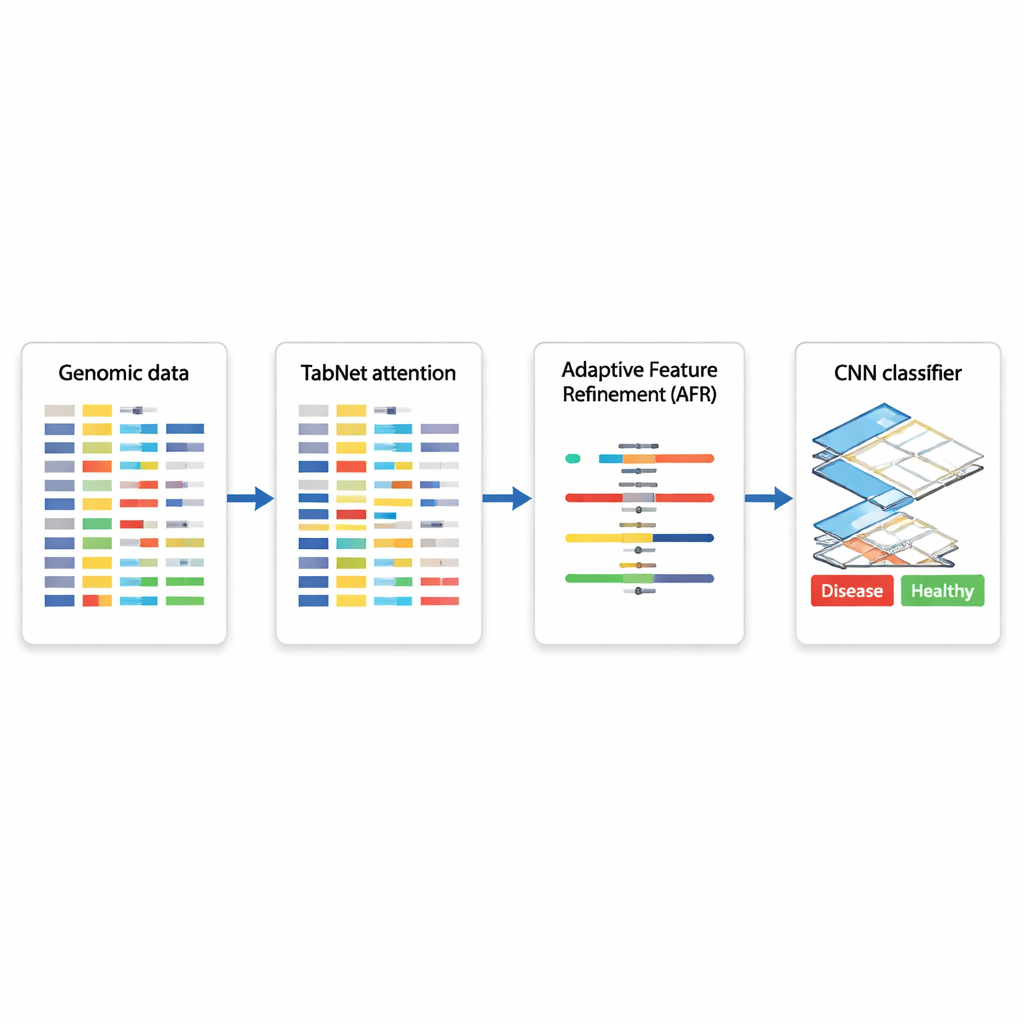
Un progetto ibrido di IA per decisioni basate sui geni
Gli autori propongono un’architettura ibrida di deep learning che concatena tre moduli specializzati. Per prima cosa, un componente chiamato TabNet funge da riflettore, esaminando tutte le misurazioni genomiche disponibili e imparando quali caratteristiche sono più informative per un dato compito — per esempio distinguere tessuto canceroso da tessuto non canceroso. Invece di trattare ogni gene allo stesso modo, TabNet concentra l’attenzione su un sottoinsieme sparso che sembra più rilevante. Successivamente, uno strato di Adaptive Feature Refinement (AFR) prende questi segnali selezionati e ne ricalibra i pesi, rafforzando pattern coerenti e significativi e attenuando ulteriormente il rumore. Infine, una rete neurale convoluzionale (CNN), comunemente usata nell’analisi delle immagini, esamina come le caratteristiche affinate interagiscono localmente, cogliendo relazioni sottili tra gruppi di geni che potrebbero segnalare un particolare sottotipo di malattia o uno stato biologico.
Mettere il modello alla prova
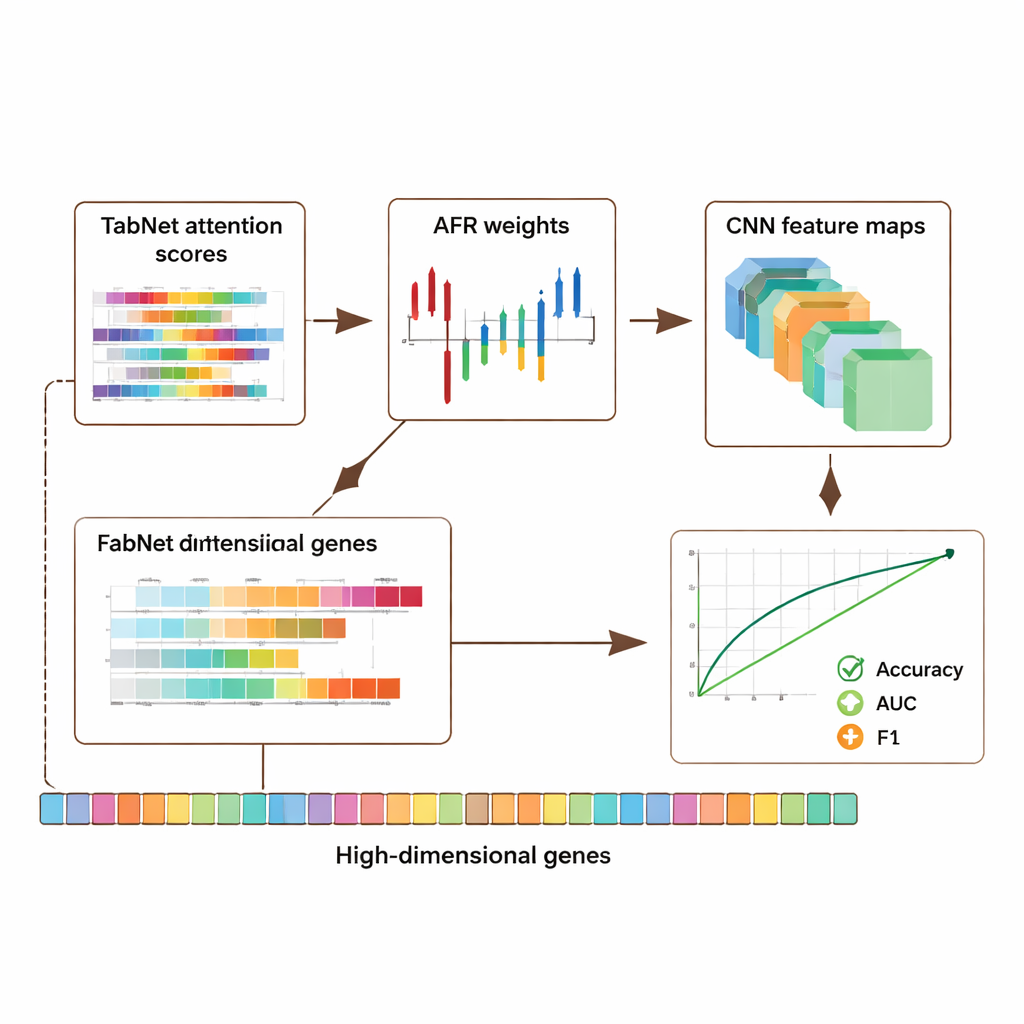
Il framework è stato valutato su tre importanti risorse pubbliche: un dataset sul cancro al seno da The Cancer Genome Atlas, un dataset single-cell sul melanoma dal Gene Expression Omnibus e un dataset epigenomico dal progetto ENCODE. Complessivamente queste collezioni includono migliaia di campioni e decine di migliaia di caratteristiche per campione, coprendo l’attività genica e le marcature chimiche sul DNA. Su tutti i dataset, il modello ibrido ha superato diversi approcci allo stato dell’arte, migliorando accuratezza e misure chiave di qualità della classificazione come l’area sotto la curva ROC (AUC) e l’F1-score di circa 5–8 punti percentuali. Cosa importante, questi guadagni non sono arrivati a scapito della trasparenza: il modello produce mappe di attenzione da TabNet e mappe di attivazione dalla CNN che evidenziano quali geni e regioni sono stati più influenti in ogni previsione.
Bilanciare accuratezza, privacy e fiducia
Poiché i dati genomici sono profondamente personali, gli autori hanno anche studiato come proteggere la privacy mantenendo però il segnale utile. Hanno introdotto un meccanismo di privacy adattivo che aggiunge più rumore alle caratteristiche altamente sensibili e meno ad altre, combinato con il mascheramento di input selezionati. I test hanno mostrato che anche quando è stato introdotto un rumore moderato, il modello ha mantenuto forte accuratezza e capacità discriminante, degradando le prestazioni in modo graduale man mano che la protezione veniva aumentata. Allo stesso tempo, i pattern interpretabili di attenzione e attivazione spesso indicavano geni già noti per il loro ruolo nel cancro e nella regolazione immunitaria, suggerendo che il sistema non si limita a memorizzare i dati ma cattura segnali biologicamente significativi. Uno studio di ablation — rimuovendo sistematicamente parti dell’architettura — ha confermato che ciascun modulo, in particolare lo strato AFR, apporta un contributo misurabile alle prestazioni.
Cosa significa questo per la medicina del futuro
In termini pratici, questo lavoro offre un modo più intelligente per setacciare enormi fogli di calcolo genomici alla ricerca di pattern collegati alla malattia, mostrando nel contempo quali voci del foglio di calcolo hanno contato di più. Combinando selezione mirata delle caratteristiche, raffinamento accurato e riconoscimento dei pattern, il modello ibrido migliora l’accuratezza delle predizioni, resta gestibile dal punto di vista computazionale e fornisce indizi visivi che clinici e biologi possono interpretare. Sebbene siano necessari ulteriori test su gruppi di pazienti più ampi e diversificati, tali framework potrebbero aiutare a identificare nuovi biomarcatori, raffinare sottotipi di malattia e supportare strumenti decisionali clinici nella medicina di precisione — portando l’analisi IA del DNA un passo più vicino all’uso nel mondo reale.
Citazione: Swain, M.K., Kamila, N.K., Jena, L. et al. Hybrid deep learning framework for accurate classification of high dimensional genomic data. Sci Rep 16, 5919 (2026). https://doi.org/10.1038/s41598-026-36128-7
Parole chiave: deep learning genomico, scoperta di biomarcatori per il cancro, IA interpretabile, medicina di precisione, genomica che preserva la privacy