Clear Sky Science · it
Integrazione della regressione kriging basata su Random Forest per analizzare la variabilità spaziale delle precipitazioni in regioni aride e semiaride
Perché mappare la pioggia nelle terre aride è importante
Nei paesi dove l'acqua scarseggia, sapere esattamente dove e quando cade la pioggia può fare la differenza tra sicurezza alimentare e crisi. Il Pakistan comprende montagne, deserti e pianure fertili, e le sue precipitazioni sono diventate più irregolari con il cambiamento climatico. Tuttavia le stazioni meteorologiche a terra sono poche e distanti. Questo studio pone una domanda pratica: con dati limitati, l'apprendimento automatico moderno combinato con tecniche di mappatura classiche può produrre carte pluviometriche più nitide e affidabili per orientare agricoltura, pianificazione delle inondazioni e gestione idrica?
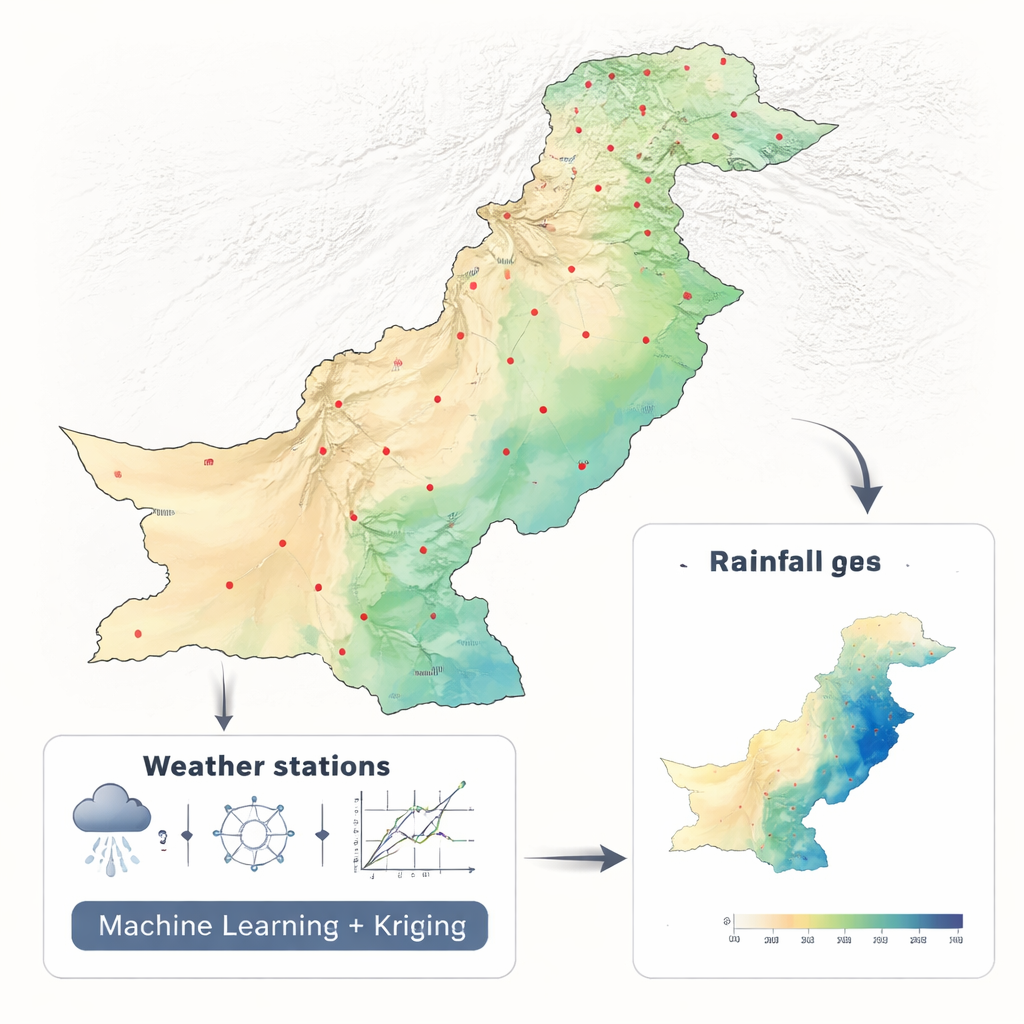
Trasformare pluviometri sparsi in mappe complete
I ricercatori hanno utilizzato due decenni di dati mensili sulle precipitazioni (2001–2010 e 2011–2021) provenienti da 42 stazioni in tutto il Pakistan, adottando un set di dati climatici coerente della NASA. Invece di immettere dozzine di variabili ambientali in un modello complesso, hanno volutamente usato solo latitudine e longitudine. Questo progetto essenziale ha permesso di concentrarsi su un problema centrale: quale approccio matematico converte al meglio misure puntuali sparse in una mappa continua. Hanno confrontato sei metodi di apprendimento automatico — Random Forest, Support Vector Machine, K-Nearest Neighbors, Neural Network, Elastic Net e Polynomial Regression — ciascuno inserito in un quadro noto come regression kriging, ampiamente usato nelle geoscienze.
Combinare apprendimento in stile big data con intuizione spaziale
La regression kriging opera in due fasi. Prima, un modello di regressione predice le precipitazioni in qualsiasi punto a partire dalle coordinate, catturando pattern ampi come montagne più piovose e deserti più asciutti. Seconda, un metodo spaziale chiamato kriging colma le differenze locali residue tra osservazioni e previsioni. Per rendere affidabile questo secondo passaggio, il team ha prima studiato quanto fossero simili o diverse le precipitazioni tra coppie di stazioni a varie distanze — uno strumento chiamato variogramma. Hanno scoperto che forme matematiche semplici, “circolare” e “lineare”, descrivevano al meglio come la somiglianza delle precipitazioni diminuisce con la distanza attraverso le stagioni e tra i due decenni, segnale di sistemi pluviometrici regionali relativamente omogenei piuttosto che di salti bruschi.
Random Forest si afferma come la scelta migliore
Una volta definita la struttura spaziale, ogni metodo di apprendimento automatico è stato impiegato come motore di regressione all'interno del modello ibrido. Gli autori hanno valutato le prestazioni con indicatori standard di errore e con la quantità di variabilità delle precipitazioni che il modello era in grado di spiegare. In quasi tutti i mesi e in entrambi i decenni, l'approccio basato su Random Forest ha prodotto le mappe più accurate e stabili. Ha ridotto gli errori di previsione molto più della regressione polinomiale e ha superato costantemente support vector machine, reti neurali e altri metodi, specialmente durante i mesi del monsone, quando le precipitazioni sono più intense e variabili. Le mappe risultanti erano lisce dove necessario, ma riuscivano comunque a cogliere contrasti netti tra zone secche e umide, con un'incertezza relativamente bassa.
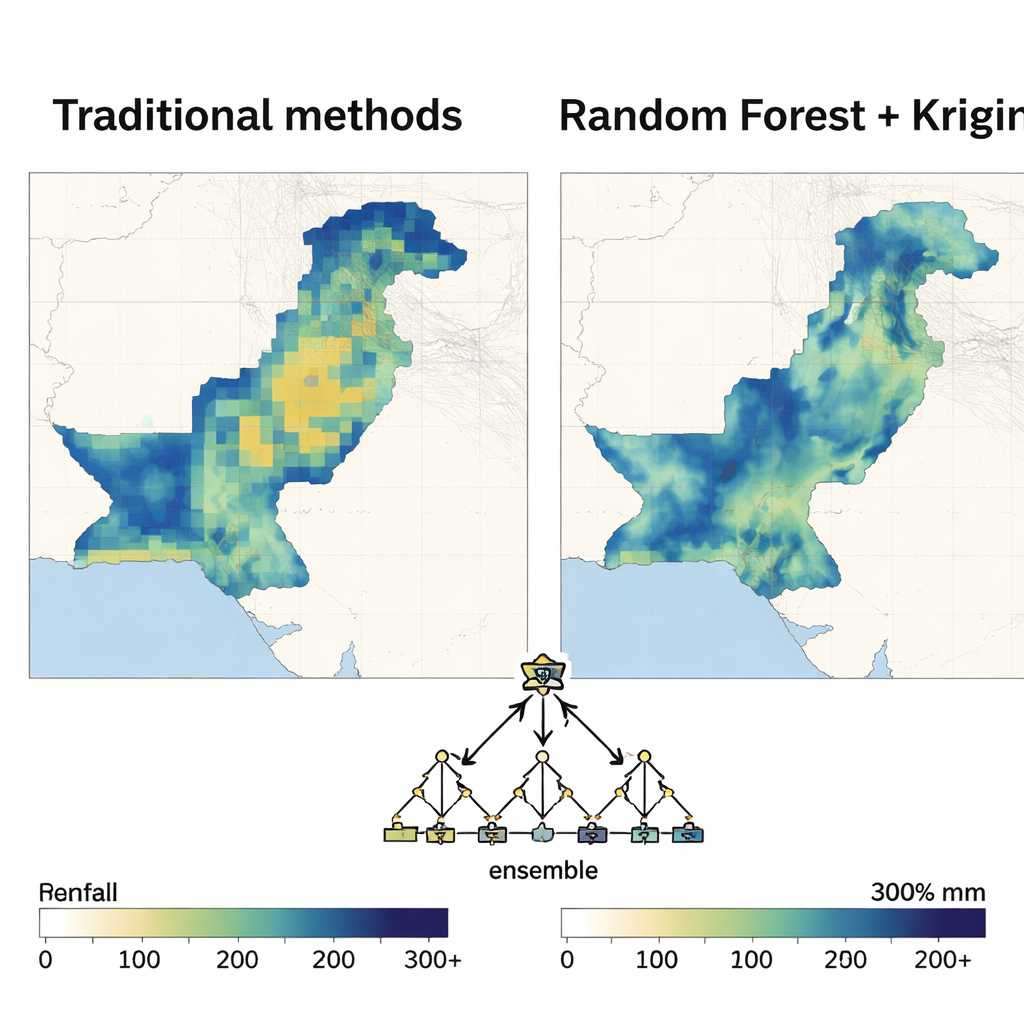
Cosa rivelano i cambiamenti nei modelli di pioggia
Confrontando i due decenni, lo studio ha inoltre rilevato segnali di un comportamento pluviometrico in evoluzione. In media, il periodo più recente (2011–2021) è risultato più umido, con una maggiore variabilità mese per mese e luogo per luogo, in particolare in primavera e durante il monsone. La struttura spaziale delle precipitazioni è diventata più dispersa, suggerendo oscillazioni più ampie nella distribuzione delle piogge. È importante notare che la combinazione Random Forest–kriging ha gestito sia il clima precedente, relativamente più mite, sia il periodo recente, più variabile, senza perdere precisione, suggerendo che strumenti flessibili di questo tipo sono adatti a un mondo in riscaldamento e meno prevedibile.
Dalle mappe alle decisioni sul territorio
In termini pratici, il lavoro mostra che algoritmi intelligenti possono estrarre più valore da registri pluviometrici limitati, producendo mappe ad alta risoluzione utili anche in regioni con pochi dati. Per il Pakistan, queste mappe possono supportare una migliore pianificazione dell'irrigazione, la gestione degli invasi e delle difese contro le inondazioni, e aiutare a identificare le comunità più esposte a siccità o piogge intense. Gli autori sottolineano che il loro lavoro è una prova di concetto focalizzata sulle tecniche di mappatura, non ancora un sistema completo di allerta per alluvioni o siccità. Tuttavia, la conclusione è chiara: combinare l'apprendimento ensemble, con Random Forest in primo piano, con la mappatura geostatistica offre un modo potente e pratico per monitorare come cambia la pioggia in terre aride e semiaride nel mondo.
Citazione: Manaf, M., Ali, Z. & Scholz, M. Integrating random forest-based regression kriging for analyzing spatial variability of rainfall in arid and semi-arid regions. Sci Rep 16, 5298 (2026). https://doi.org/10.1038/s41598-026-36074-4
Parole chiave: mappatura delle precipitazioni, random forest, regression kriging, clima del Pakistan, risorse idriche