Clear Sky Science · it
Predizione cross-well con machine learning dei log sonici a Terranova e Labrador
Ascoltare le rocce senza un microfono
Le compagnie petrolifere e del gas si affidano a strumenti acustici «sonici» per ascoltare come onde sonore si propagano nelle rocce sotterranee. Queste misure dettagliate aiutano gli ingegneri a valutare la resistenza delle rocce, pianificare pozzi sicuri e mettere in corrispondenza i dati di perforazione con i sismici. Tuttavia gli strumenti sonici sono costosi, possono rallentare le operazioni e talvolta non possono essere impiegati. Questo studio mostra come il machine learning possa ricostruire l'informazione sonica a partire da misure più economiche e raccolte di routine, offrendo un modo per «sentire» il sottosuolo anche quando il microfono manca.
Perché prevedere i dati sonici conta
Nella perforazione offshore gli operatori registrano molti tipi di log: radioattività naturale, velocità di perforazione, portata della pompa, carico sulla punta di perforazione e altro. I log sonici sono particolarmente importanti perché rivelano la velocità di propagazione del suono nelle rocce, un input chiave per stimare la rigidità della roccia, la pressione e le sollecitazioni. Quando gli strumenti sonici non sono disponibili, gli ingegneri devono lavorare con lacune o affidarsi a regole empiriche approssimative. Usando il machine learning per trasformare i log non sonici comuni in curve «pseudo-soniche» accurate, le aziende possono ridurre i costi di acquisizione dati, riempire sezioni mancanti e continuare a prendere decisioni informate sulla stabilità del pozzo e sul comportamento del giacimento.
Una ricetta attenta per evitare «cheating»
Gli autori hanno lavorato con dati di due pozzi offshore a Terranova e Labrador. Per ogni profondità hanno provato a predire la lentezza compressionale (un modo di esprimere quanto tempo impiega un'onda sonora a attraversare la roccia) usando solo misure non soniche. Crucialmente hanno vietato qualsiasi input che usasse direttamente o indirettamente dati sonici, come proprietà elastiche derivate. Hanno inoltre costruito feature utilizzando soltanto informazioni della stessa profondità o più superficiali, imitando la perforazione in tempo reale dove il futuro è sconosciuto. Gli outlier nelle letture dei sensori sono stati identificati usando statistiche ottenute da un solo pozzo «di addestramento» e poi trattati nello stesso modo in entrambi i pozzi, assicurando che i modelli non potessero apprendere inavvertitamente dai dati di test. Tutte le normalizzazioni e le scelte di feature sono state fissate sul pozzo di training prima di essere applicate, inalterate, all'altro pozzo.
Trasformare i log grezzi in segnali apprendibili
Limitarsi a dare i log grezzi a un algoritmo raramente è sufficiente. Il team ha progettato un ricco insieme di feature consapevoli della profondità: hanno monitorato come ogni log cambia con la profondità, levigato segnali rumorosi a diverse scale e calcolato pendenze e curvature che evidenziano tendenze locali. Hanno anche espresso la profondità rispetto a segmenti del foro, catturando pattern che si ripetono quando cambia la dimensione dell'utensile di perforazione. Per evitare che i modelli venissero sovraccaricati, hanno ordinato le feature usando tre metodi diversi e combinato le graduatorie in un'unica lista. Un gruppo compatto delle feature più informative è stato poi selezionato usando uno split temporale-consapevole all'interno del pozzo di training, in modo che il processo rispettasse l'ordine naturale con la profondità.
I modelli ad albero battono il deep learning
Lo studio ha confrontato tre tipi di modelli: Random Forest, XGBoost (un noto metodo di gradient boosting) e reti neurali LSTM bidirezionali, spesso usate per dati sequenziali. Ogni modello è stato addestrato su un pozzo e testato alla cieca sull'altro, una configurazione rigorosa che mette a nudo le differenze tra pozzi in termini di intervalli di profondità, condizioni operative e tipologie di roccia. In questo test XGBoost ha ottenuto le migliori prestazioni, raggiungendo alta concordanza tra i log sonici previsti e quelli misurati quando addestrato sul primo pozzo e applicato al secondo. I Random Forest sono rimasti vicini e talvolta più stabili nelle zone rumorose. Le LSTM, nonostante la loro complessità, sono state meno precise e robuste, probabilmente perché i dati includevano solo due pozzi e variavano fortemente con la profondità, condizioni sfavorevoli per reti neurali di grande dimensione.
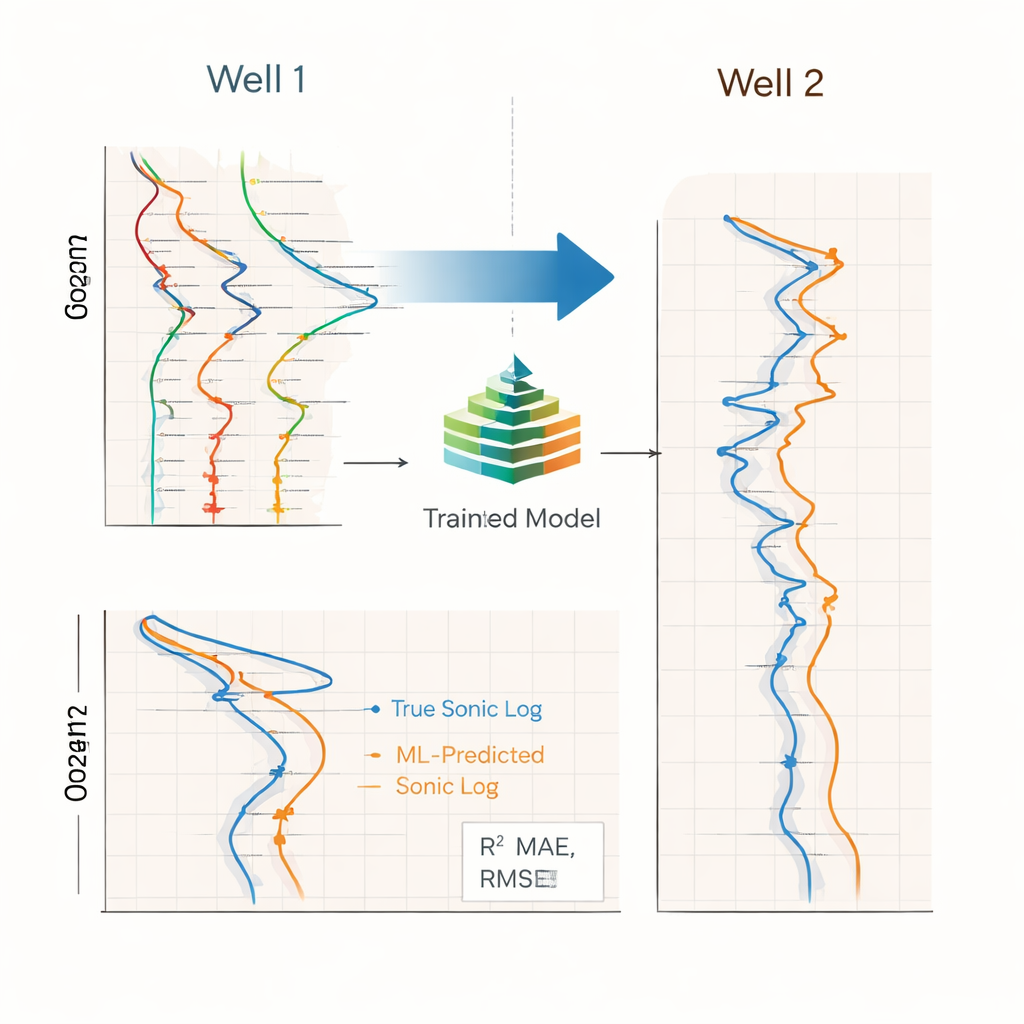
Che cosa guida l'accuratezza e dove è utile
Disattivando e riattivando diversi passaggi di preprocessing, gli autori hanno dimostrato che la generazione e la selezione intelligente delle feature hanno fatto la differenza maggiore nelle prestazioni, più che l'aggiunta di finestre di storia più lunghe o di un semplice filtraggio degli outlier. Quando questi passaggi erano inclusi, entrambi i modelli ad albero generalizzavano molto meglio tra i pozzi. I pseudo-log sonici risultanti erano sufficientemente accurati da supportare attività a valle come la stima della rigidità delle rocce, la modellazione della pressione dei pori e degli stati di sforzo, la calibrazione di dati sismici e la pianificazione dei pozzi in zone dove le misure soniche dirette mancano, sono ritardate o poco affidabili. Poiché tutte le trasformazioni sono fissate su un pozzo di riferimento e poi riutilizzate, il flusso di lavoro potrebbe funzionare quasi in tempo reale durante la perforazione.
Messaggio principale per i non specialisti
Questo lavoro dimostra che con una gestione rigorosa dei dati e modelli di machine learning ben scelti è possibile ricreare informazioni soniche di alto valore a partire da canali di perforazione e logging più economici in un nuovo pozzo mai visto dal modello. L'approccio non sostituisce gli strumenti sonici dedicati, specialmente dove i margini di sicurezza sono ristretti, ma offre una soluzione pratica e conveniente di backup, oltre a un controllo di qualità quando i dati misurati appaiono sospetti. Con l'aggiunta di più pozzi e regioni e con la sperimentazione di modelli più recenti sotto le stesse regole rigorose, questo tipo di predizione cross-well potrebbe diventare una componente standard della cassetta degli attrezzi digitale per una perforazione offshore più sicura ed efficiente.
Citazione: Zare, B., Huque, M.M., James, L.A. et al. Cross-well machine learning prediction of sonic logs in Newfoundland and Labrador. Sci Rep 16, 5292 (2026). https://doi.org/10.1038/s41598-026-36053-9
Parole chiave: machine learning, log sonici, well logging, perforazione offshore, caratterizzazione del giacimento