Clear Sky Science · it
Health-FedNet: apprendimento federato sicuro per la previsione delle malattie croniche su MIMIC-III con privacy differenziale e crittografia omomorfica
Perché i tuoi dati medici hanno bisogno di nuovi tipi di chiavi
Gli ospedali moderni si rivolgono all’intelligenza artificiale per individuare le malattie prima e personalizzare i trattamenti, ma questa potenza ha un costo: i computer apprendono meglio da grandi quantità di cartelle cliniche che sono troppo sensibili per essere semplicemente centralizzate. Questo articolo presenta Health-FedNet, un nuovo metodo che permette agli ospedali di addestrare strumenti predittivi potenti per malattie croniche come il diabete e l’ipertensione mantenendo i dettagli dei pazienti protetti all’interno di ogni istituzione. Mostra come ottenere i vantaggi della medicina basata su grandi dati senza creare un unico bersaglio allettante per gli hacker o violare le normative sulla privacy.
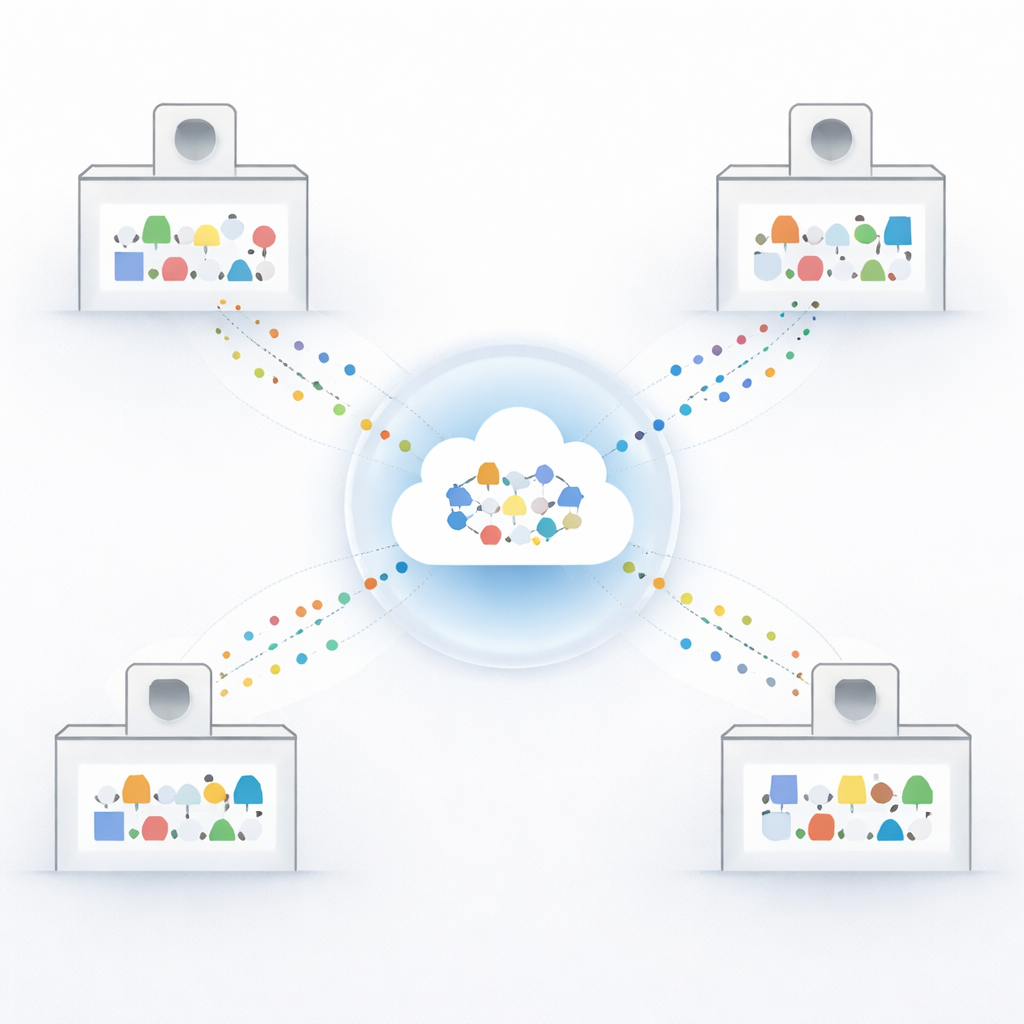
Come gli ospedali possono imparare insieme senza condividere le cartelle
Health-FedNet si basa su un approccio chiamato apprendimento federato, in cui un modello predittivo condiviso viene inviato a più ospedali, addestrato localmente sui dati di ogni sede e poi restituito come insieme aggiornato di parametri. Invece di raccogliere i record medici grezzi in un magazzino centrale, viaggiano solo questi aggiornamenti, quindi le informazioni sui pazienti non lasciano le mura dell’ospedale. Il server centrale combina poi tutti gli aggiornamenti per produrre un modello globale migliorato, e il ciclo si ripete finché le predizioni non si stabilizzano. In questo lavoro, gli autori simulano una rete di ospedali usando il noto database di terapia intensiva MIMIC-III, chiedendo a Health-FedNet di prevedere chi svilupperà diabete o ipertensione.
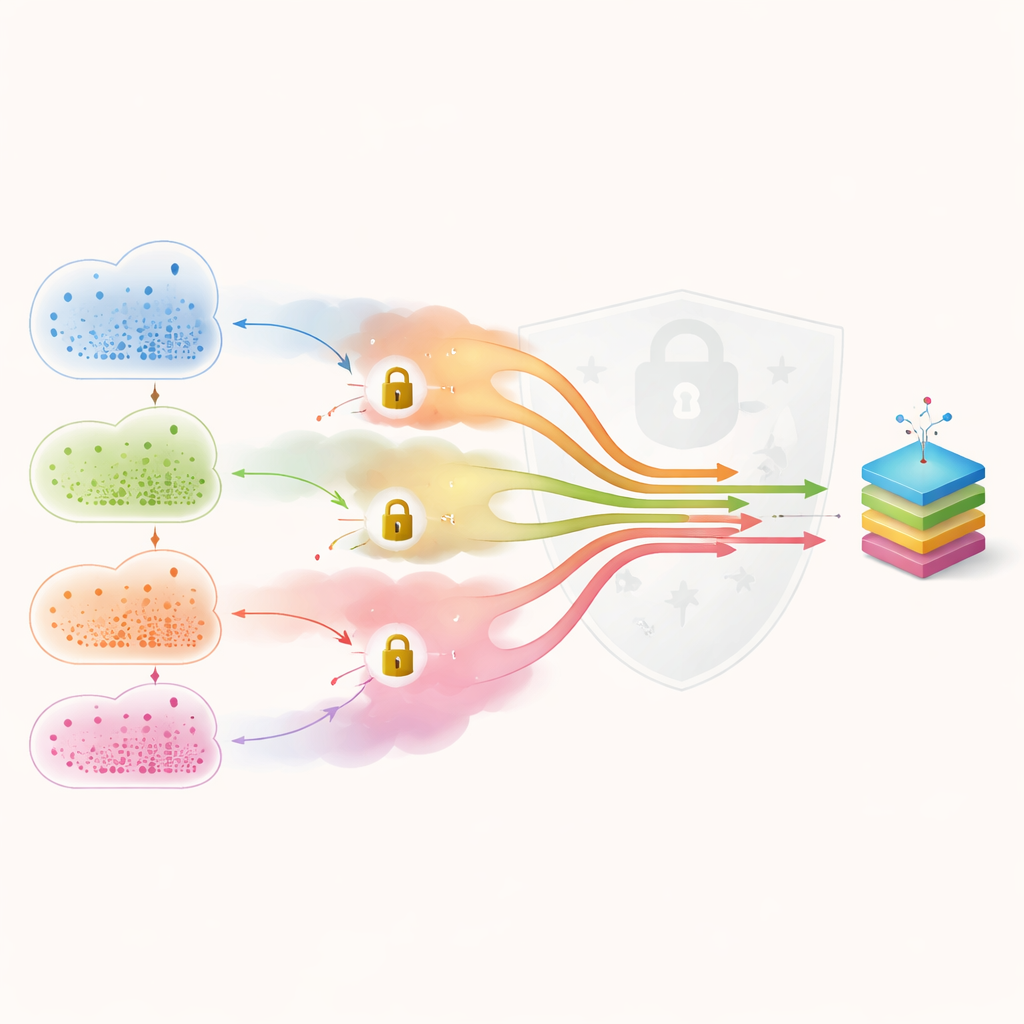
Aggiungere rumore e serrature per nascondere i singoli pazienti
Scambiarsi semplicemente aggiornamenti del modello non basta per garantire la privacy, perché attaccanti esperti possono talvolta ricostruire informazioni sui singoli pazienti a partire da quegli aggiornamenti. Health-FedNet contrasta questo problema su due fronti. Innanzitutto, ogni ospedale aggiunge deliberatamente una piccola quantità di “rumore” matematico ai propri aggiornamenti, in modo che l’influenza del record di una singola persona diventi indistinguibile. Questa tecnica, chiamata privacy differenziale, permette agli autori di fissare un limite numerico rigido su quanto un singolo record possa essere esposto. In secondo luogo, gli aggiornamenti rumoreggiati sono crittografati con un metodo che consente comunque di combinarli mentre rimangono bloccati, così il server centrale non li vede mai in chiaro. Insieme, questi livelli riducono drasticamente la probabilità che estranei — o anche il server stesso — possano ricostruire dettagli privati.
Lasciare che i dati di qualità superiore si facciano sentire di più
Gli ospedali reali non sono tutti uguali. Alcuni curano più pazienti, altri raccolgono informazioni più ricche e alcuni hanno registrazioni più rumorose. Se il contributo di ogni istituzione viene trattato alla pari, il modello finale può essere appesantito da dati di qualità inferiore. Health-FedNet introduce uno schema di pesatura adattiva che valuta ogni ospedale in base al numero di record e alla performance del suo modello locale. A quelli con dati più coerenti e informativi viene data una voce relativamente più forte quando gli aggiornamenti vengono combinati, pur garantendo che nessuna singola sede domini il processo. Gli autori dimostrano che questa pesatura aiuta il modello condiviso a imparare in modo più stabile quando tassi di malattia e qualità dei record variano da un’istituzione all’altra — una situazione realistica nella pratica sanitaria quotidiana.
Quanto bene il sistema predice e protegge
Per testarne la praticabilità, il team confronta Health-FedNet sia con un modello centralizzato standard che si allena su dati aggregati sia con una configurazione federata più basilare priva degli strumenti di privacy aggiuntivi. Sulla rete ospedaliera simulata, Health-FedNet predice le malattie croniche con circa il 92% di accuratezza e un valore di area sotto la curva (AUC) di 0,94, chiaramente davanti alle alternative. Allo stesso tempo, riduce nettamente il rischio che un attaccante possa determinare se il record di una persona specifica sia stato usato per l’addestramento o ricostruire i suoi dettagli medici, diminuendo tali fughe di informazioni di circa tre-quattro volte. Nonostante l’aggiunta di crittografia e rumore, il sistema abbassa anche l’overhead di comunicazione tra gli ospedali e il server centrale, grazie a un attento impacchettamento e pesatura degli aggiornamenti, rendendolo più praticabile per reti di grandi dimensioni.
Cosa significa questo per la medicina digitale del futuro
In termini semplici, Health-FedNet dimostra che non dobbiamo scegliere tra previsioni mediche accurate e forti garanzie di privacy. Permettendo agli ospedali di imparare insieme dai pattern nei loro dati mantenendo le cartelle individuali locali, aggiungendo rumore calibrato e crittografando gli aggiornamenti end-to-end, il framework soddisfa requisiti chiave di regolamentazioni come HIPAA e GDPR. Lo studio suggerisce che progettazioni analoghe potrebbero sostenere future reti sanitarie nazionali o persino internazionali, in cui molte istituzioni collaborano per prevedere malattie, individuare focolai e guidare i trattamenti — senza mai cedere i record grezzi dei pazienti.
Citazione: Shahid, M.I., Badar, H.M.S., Asghar, M.N. et al. Health-FedNet: secure federated learning for chronic disease prediction on MIMIC-III with differential privacy and homomorphic encryption. Sci Rep 16, 7968 (2026). https://doi.org/10.1038/s41598-026-36034-y
Parole chiave: apprendimento federato, privacy dei dati sanitari, previsione delle malattie croniche, sicurezza dell'IA medica, condivisione dei dati ospedalieri