Clear Sky Science · it
La base di regole di credenza ottimizzata multi-parametro per prevedere le prestazioni degli studenti con interpretabilità
Perché prevedere i voti riguarda tutti
Il pagellino può sembrare semplice, ma le forze che determinano i voti di uno studente sono tutt’altro che banali. Le scuole si affidano sempre più a modelli informatici per individuare precocemente gli studenti in difficoltà e orientare gli interventi. Tuttavia molti di questi modelli sono “scatole nere”: possono essere precisi, ma nemmeno insegnanti e genitori riescono a vedere perché è stata formulata una certa previsione. Questo articolo presenta un nuovo approccio che mira a essere al contempo molto accurato e facile da comprendere, in modo che gli operatori dell’istruzione possano fidarsi dei risultati e agire di conseguenza.
Un modo più intelligente di leggere i segnali
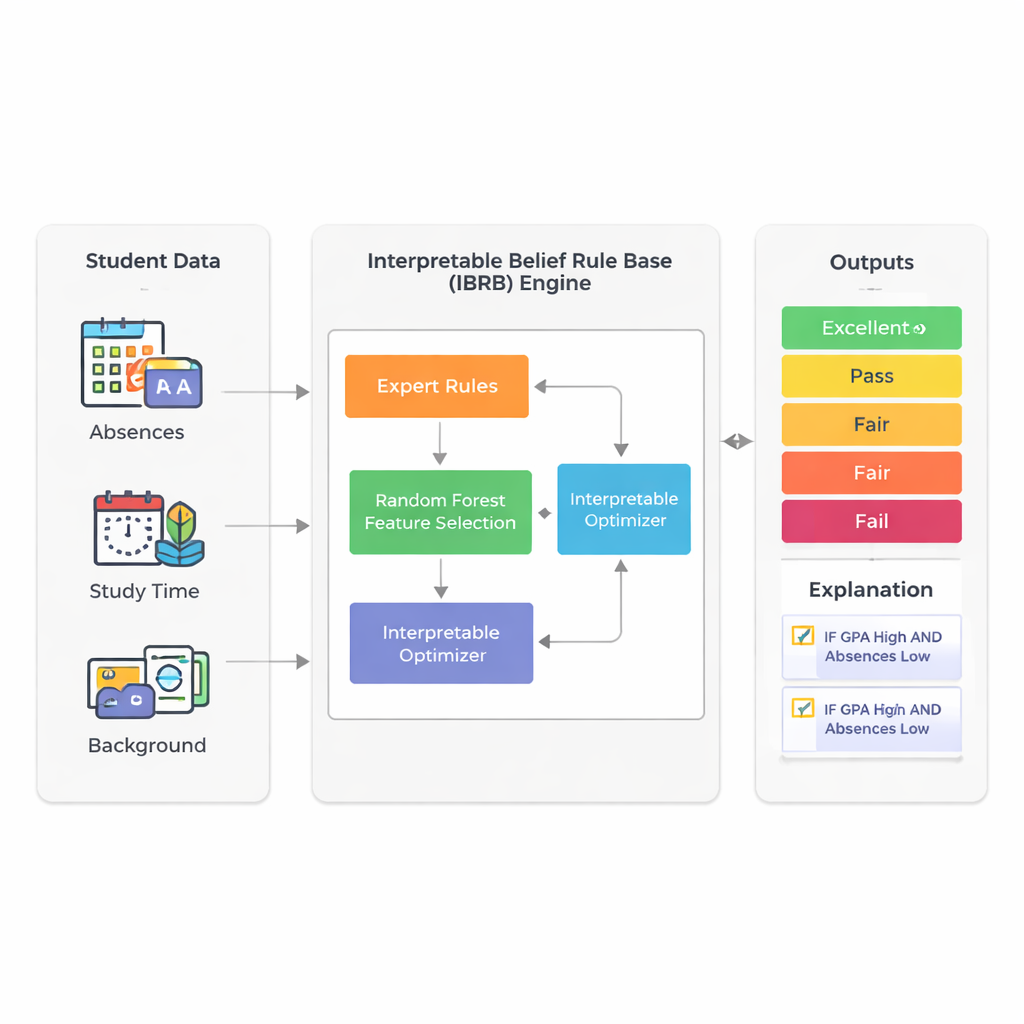
Lo studio si concentra sulla previsione delle prestazioni finali degli studenti usando le informazioni che le scuole già raccolgono: media dei voti (GPA), assenze, tempo di studio, contesto socioeconomico e fattori familiari e di attività. Invece di affidarsi a sistemi di deep learning opachi, gli autori si basano su una tecnica chiamata base di regole di credenza. In questo quadro, gli esperti scrivono regole che somigliano a ciò che un insegnante potrebbe dire: “Se la media è alta e le assenze sono poche, allora lo studente probabilmente andrà bene.” Ogni regola porta un grado di credenza riguardo a possibili esiti come Eccellente, Buono, Sufficiente, Discreto o Insufficiente. Ciò rende il processo di ragionamento visibile e, in linea di principio, spiegabile anche ai non esperti.
Domare la complessità senza perdere significato
Una sfida importante dei sistemi basati su regole è che possono diventare ingestibili quando si includono molte caratteristiche dello studente: ogni fattore aggiuntivo moltiplica il numero di regole possibili. Per evitare questa “esplosione di regole”, i ricercatori utilizzano prima una random forest—un ensemble di alberi decisionali ampiamente usato—per misurare quali caratteristiche sono più rilevanti per la previsione delle prestazioni. Nel loro dataset reale di 2.392 studenti provenienti da una fonte pubblica, GPA e numero di assenze spiegano circa il 73% della potenza predittiva del modello. Mantenendo deliberatamente solo questi due input, il modello finale resta compatto e più facilmente interpretabile, pur riflettendo la maggior parte della variabilità negli esiti degli studenti.
Costruire regole che le persone possano seguire
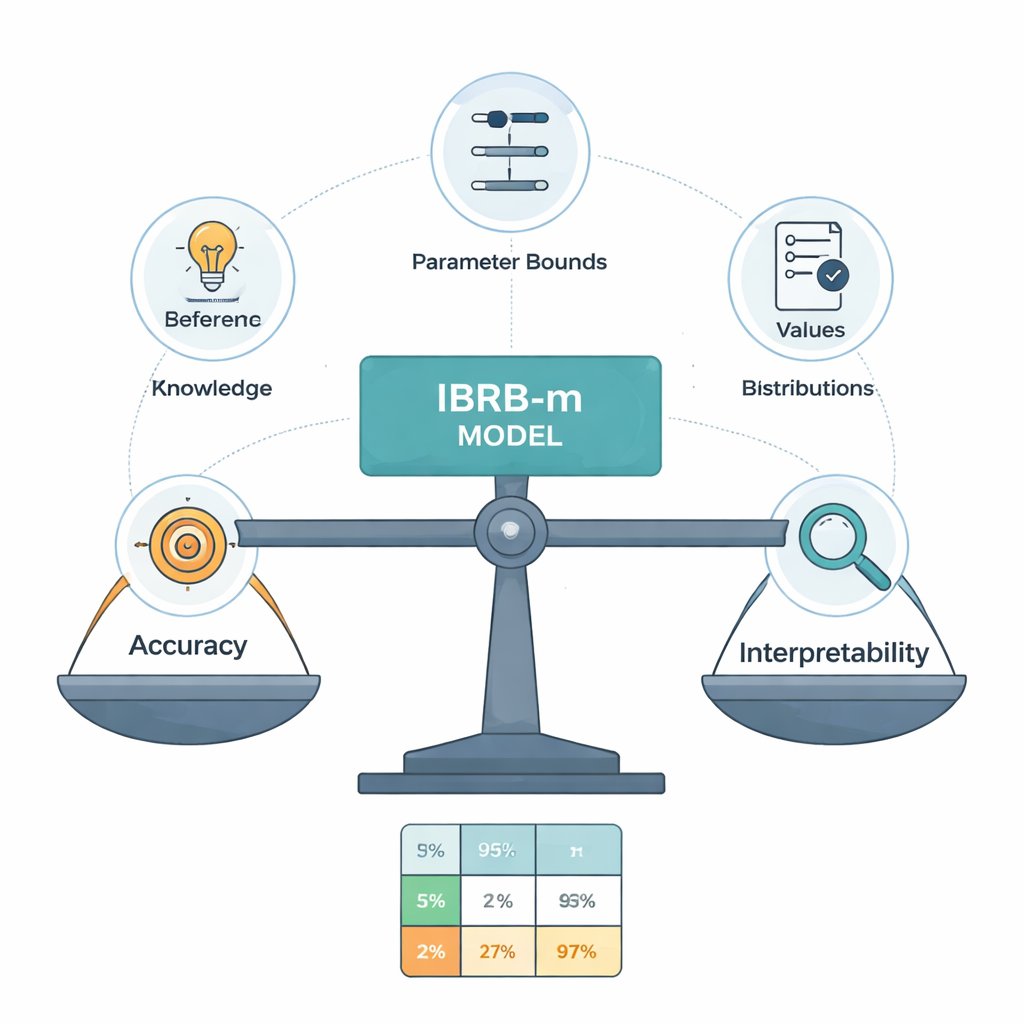
Il nucleo del nuovo modello, chiamato IBRB-m, è un insieme attentamente strutturato di 25 regole che combinano livelli di GPA e assenze con gradi di credenza per le cinque categorie di rendimento. Gli autori formalizzano cosa significa che un tale modello sia “interpretabile”. Tra i requisiti: ogni livello di riferimento (ad esempio “GPA basso”) deve coprire un intervallo chiaro e distinto; la base di regole deve coprire tutte le combinazioni realistiche di input; i parametri come i pesi delle regole e i pesi degli attributi devono avere significati comprensibili; e i calcoli interni del sistema devono trasformare l’informazione in modo trasparente e matematicamente coerente. Oltre a queste condizioni tradizionali, aggiungono linee guida specifiche per l’istruzione che costringono le previsioni del modello a seguire forme di buon senso—for example evitando casi bizzarri in cui uno studente risulti contemporaneamente molto probabile di eccellere e di essere insufficiente.
Lasciare che i dati mettano a punto ciò che dicono gli esperti
Gli esperti umani non sono sempre d’accordo e le loro regole iniziali possono essere imprecise. Per perfezionare queste regole senza trasformare il modello in una scatola nera, gli autori progettano un algoritmo di ottimizzazione migliorato che cerca valori di parametro migliori rispettando vincoli stringenti di interpretabilità. Questo algoritmo aggiusta non solo i pesi delle regole e i gradi di credenza, ma anche i punti di separazione che definiscono categorie come Eccellente o Sufficiente. Mantiene tutte le modifiche entro limiti approvati dagli esperti e applica pattern di credenza ragionevoli e graduali lungo i voti. In sostanza, il computer “spinge” il sistema di esperti verso una maggiore accuratezza, ma non è autorizzato a inventare regole che lascerebbero perplesso un insegnante esperto.
Quanto funziona in pratica?
Testato sul dataset di Kaggle sulle prestazioni degli studenti, il modello IBRB-m predice correttamente i livelli di rendimento finale in oltre il 99% dei casi, superando sia i sistemi di base di regole di credenza precedenti sia strumenti comuni di machine learning come reti neurali, random forest e k-nearest neighbors. Altrettanto importante, le regole ottimizzate restano vicine alle valutazioni iniziali degli esperti quando misurate con una semplice metrica di distanza, il che significa che il ragionamento dietro ogni previsione può ancora essere tracciato e giustificato. La validazione incrociata su più suddivisioni del dataset mostra che la performance del modello è stabile e non frutto di una fortunata ripartizione.
Cosa significa questo per le aule
Per il pubblico generale, la conclusione principale è che è possibile disporre di strumenti di previsione delle prestazioni studentesche che siano al contempo potenti e comprensibili. Invece di emettere punteggi di rischio misteriosi, il modello può evidenziare pattern concreti come “GPA moderato ma assenze frequenti” e mostrare come questi confluiscano in una previsione di Discreto o Insufficiente. Insegnanti e consulenti possono quindi intervenire con azioni mirate—come supporto alla frequenza o coaching sulle abilità di studio—spiegando con sicurezza a studenti e genitori perché il modello ha raggiunto quella conclusione. Gli autori sostengono che questa combinazione di accuratezza e trasparenza è essenziale perché i sistemi basati sui dati possano svolgere un ruolo affidabile nella promozione di un’istruzione equa ed efficace.
Citazione: Li, J., Zhou, W., Jiang, S. et al. The multi-parameter optimized belief rule base for predicting student performance with interpretability. Sci Rep 16, 5772 (2026). https://doi.org/10.1038/s41598-026-35950-3
Parole chiave: predizione delle prestazioni degli studenti, IA interpretabile, base di regole di credenza, data mining educativo, apprendimento automatico spiegabile