Clear Sky Science · it
Strategia di ottimizzazione dinamica guidata da reinforcement learning per il design parametrico di modelli 3D
Progetti 3D più intelligenti con meno tentativi a vuoto
Dagli edifici che catturano lo sguardo alle piccole parti meccaniche all’interno del tuo telefono, molti oggetti moderni nascono come modelli 3D al computer. I progettisti spesso usano modelli “parametrici”, in cui cursori e formule controllano forme, dimensioni e pattern. Questo rende semplice esplorare molte opzioni — ma crea anche un labirinto di possibilità impossibile da esplorare manualmente. Questo articolo introduce un nuovo approccio di intelligenza artificiale chiamato HRL‑DOS che aiuta i computer a orientarsi in quel labirinto, migliorando automaticamente i progetti 3D in termini di resistenza, uso dei materiali e facilità di fabbricazione.
La sfida di troppe scelte
Nella progettazione parametrica, un singolo oggetto può dipendere da dozzine o centinaia di parametri collegati: spessori delle pareti, dimensioni dei fori, curvature e regole di allineamento. Man mano che i modelli diventano più complessi, questi parametri interagiscono in modi non ovvi. Gli strumenti di ottimizzazione tradizionali si basano o su funzioni matematiche lisce, che falliscono quando i progetti sono irregolari o rumorosi, o su metodi di ricerca per tentativi, che possono essere dolorosamente lenti per problemi di grandi dimensioni. Anche il reinforcement learning standard — dove un agente AI impara tramite tentativi ripetuti e feedback — fatica quando deve considerare tutte le possibili combinazioni di decisioni progettuali contemporaneamente.
Un’intelligenza a due livelli che pensa come un progettista
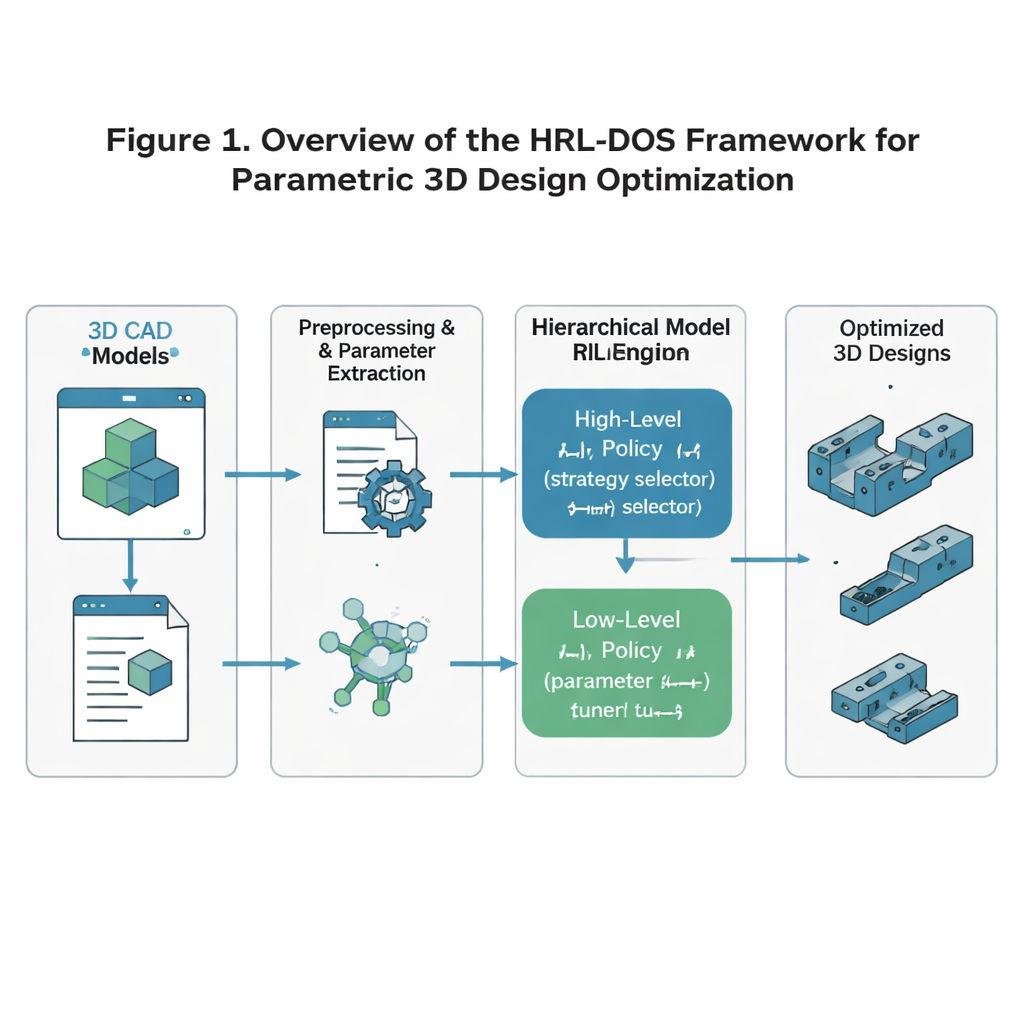
Gli autori propongono la Strategia di Ottimizzazione Dinamica basata su Reinforcement Learning Gerarchico, o HRL‑DOS, per affrontare questa complessità. Invece di trattare il progetto come un’unica grande decisione, HRL‑DOS suddivide il compito in due livelli. Una policy di alto livello sceglie una direzione complessiva per il progetto — per esempio privilegiare minor peso, maggiore simmetria o un margine di sicurezza extra. Una policy di basso livello poi regola i singoli parametri, come dimensioni specifiche o posizionamento delle caratteristiche, all’interno di quel piano più ampio. Entrambi i livelli ricevono feedback basati su quanto bene il modello corrente performa rispetto a tre obiettivi fondamentali: stabilità strutturale, efficienza geometrica e fabbricabilità. Questa struttura a strati rispecchia il modo in cui lavorano i progettisti umani: prima si decide il concetto, poi si rifiniscono i dettagli.
Trasformare modelli 3D grezzi in dati apprendibili
Per addestrare il sistema, i ricercatori partono dall’ABC Dataset, una vasta raccolta open di modelli 3D industriali dettagliati come staffe, ingranaggi, leve e piastre di montaggio. Preprocessano ogni modello in modo che l’AI veda una rappresentazione pulita e coerente: la geometria viene normalizzata a una scala e orientamento standard; le dimensioni chiave e le caratteristiche vengono estratte come parametri; e le regole di fabbricazione — come spessore minimo delle pareti o angoli di sbalzo ammessi — vengono codificate come vincoli. Questi parametri vengono poi trasformati in una descrizione “latente” compatta che scoraggia naturalmente forme impossibili o instabili. Il risultato è uno stato numerico che l’AI può modificare in sicurezza rispettando comunque le regole ingegneristiche di base.
Imparare a migliorare parti realistiche
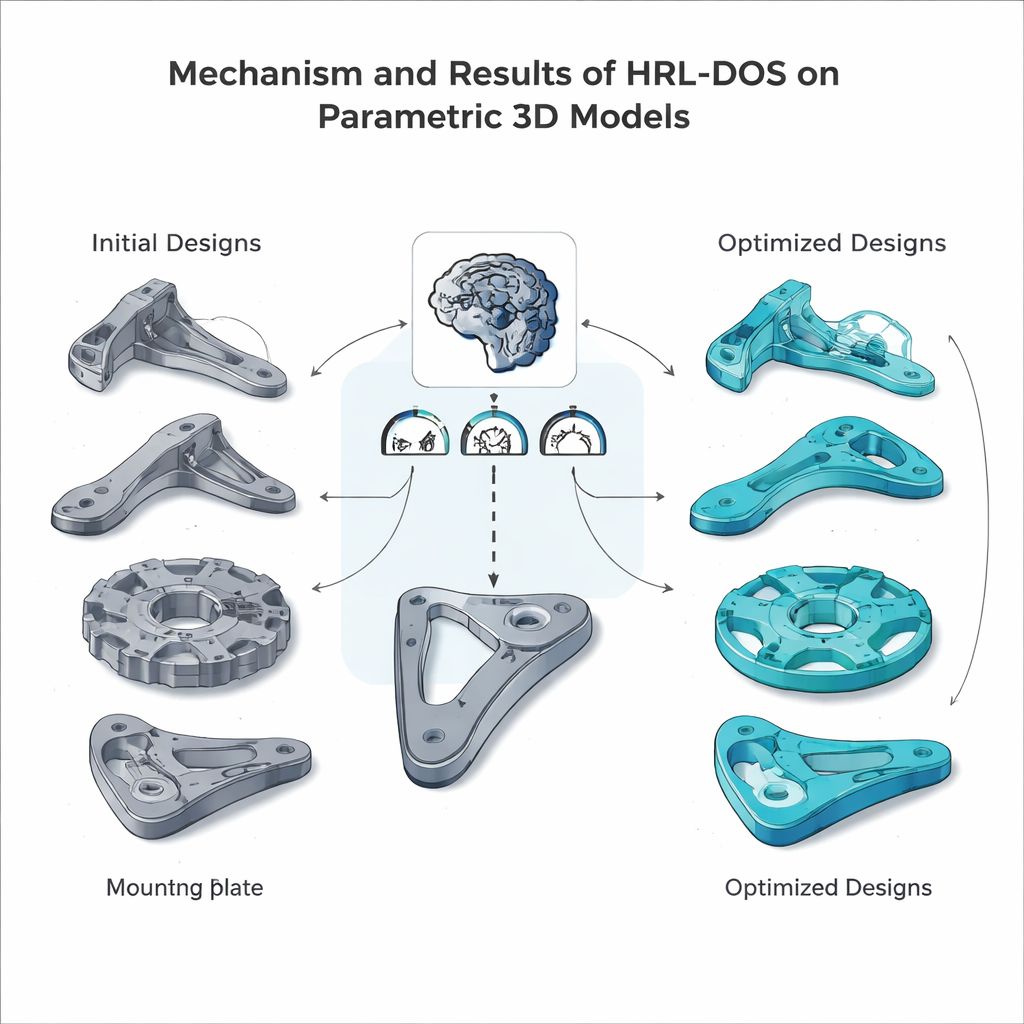
All’interno di questo ambiente preparato, gli agenti gerarchici propongono ripetutamente nuovi progetti, eseguono simulazioni per stimare peso e stress, verificano la fabbricabilità e ricevono un punteggio di ricompensa combinato. Nel corso di numerosi episodi di addestramento, l’agente di alto livello impara quali obiettivi strategici tendono a risultare vantaggiosi, mentre l’agente di basso livello scopre quali regolazioni dei parametri concretamente realizzano quegli obiettivi. Il team ha testato HRL‑DOS su diverse parti rappresentative del dataset — una staffa con nervature, un disco dentato, una maniglia a leva e una piastra di montaggio — e ne ha confrontato le prestazioni con varie alternative avanzate, inclusi reinforcement learning “piatto”, ibridi con algoritmi genetici e altri strumenti di progettazione assistita da AI. HRL‑DOS ha raggiunto buone soluzioni circa il 27% più velocemente e ha prodotto modelli con punteggi di qualità complessivi approssimativamente superiori del 18%.
Progetti robusti, producibili e flessibili
Oltre alle prestazioni pure, HRL‑DOS si è dimostrato migliore nel rimanere entro limiti ingegneristici stringenti. Ha generato molti meno progetti che violavano vincoli di sicurezza o di produzione e ha ottenuto punteggi di fabbricabilità più elevati in controlli come angoli di sbalzo, cavità interne e tolleranze. Il metodo si è anche generalizzato bene a nuovi tipi di parti non visti durante l’addestramento ed è rimasto robusto quando i dati di input erano rumorosi o parzialmente mancanti — una caratteristica importante per i flussi di lavoro progettuali nel mondo reale. Nel complesso, questi risultati suggeriscono che il reinforcement learning gerarchico può fungere da motore pratico per una progettazione assistita da computer intelligente, aiutando architetti e ingegneri a esplorare più opzioni in meno tempo mantenendo i modelli sicuri, efficienti e pronti per la fabbricazione.
Citazione: Zhong, G., Vijay, V.C. Reinforcement learning-driven dynamic optimization strategy for parametric design of 3D models. Sci Rep 16, 5041 (2026). https://doi.org/10.1038/s41598-026-35863-1
Parole chiave: progettazione 3D parametrica, reinforcement learning, ottimizzazione del design, progettazione assistita da computer, ingegneria generativa