Clear Sky Science · it
HEViTPose: verso una stima della posa umana 2D ad alta accuratezza ed efficiente con attenzione a riduzione spaziale a gruppi cascata
Insegnare ai computer a leggere il linguaggio del corpo
Dalle app per il fitness ai sistemi di assistenza alla guida, molte tecnologie oggi dipendono dalla capacità di un computer di comprendere come si muovono le persone. Questa abilità, chiamata stima della posa umana, consiste nel trovare le posizioni delle articolazioni del corpo—come spalle, ginocchia e caviglie—in un’immagine o in un video. La sfida è farlo con precisione e abbastanza velocemente per l’uso in tempo reale su hardware comune. Questo articolo presenta HEViTPose, un nuovo metodo che punta a mantenere alta accuratezza usando meno potenza di calcolo rispetto a molti sistemi attuali.
Perché trovare le articolazioni nelle immagini è così difficile
A prima vista, localizzare le articolazioni potrebbe sembrare semplice: basta cercare braccia e gambe. In pratica, le persone appaiono a diverse scale, in pose insolite, in scene affollate e spesso parzialmente occluse da oggetti come mobili o automobili. I sistemi moderni di stima della posa di solito gestiscono questo creando una “heatmap” dettagliata per ogni articolazione, dove le aree più luminose indicano le posizioni probabili. Le heatmap sono molto precise ma costose da calcolare. I sistemi tradizionali si basano principalmente su reti neurali convoluzionali, ottime nel riconoscere pattern locali ma costrette a diventare più profonde e pesanti per catturare relazioni a lungo raggio su tutto il corpo. I modelli recenti basati su transformer eccellono nel catturare questi legami a lunga distanza, tuttavia spesso richiedono grandi dataset e calcoli intensivi, rendendoli più difficili da usare in tempo reale o su dispositivi più piccoli.
Riquadri sovrapposti per una visione più fluida
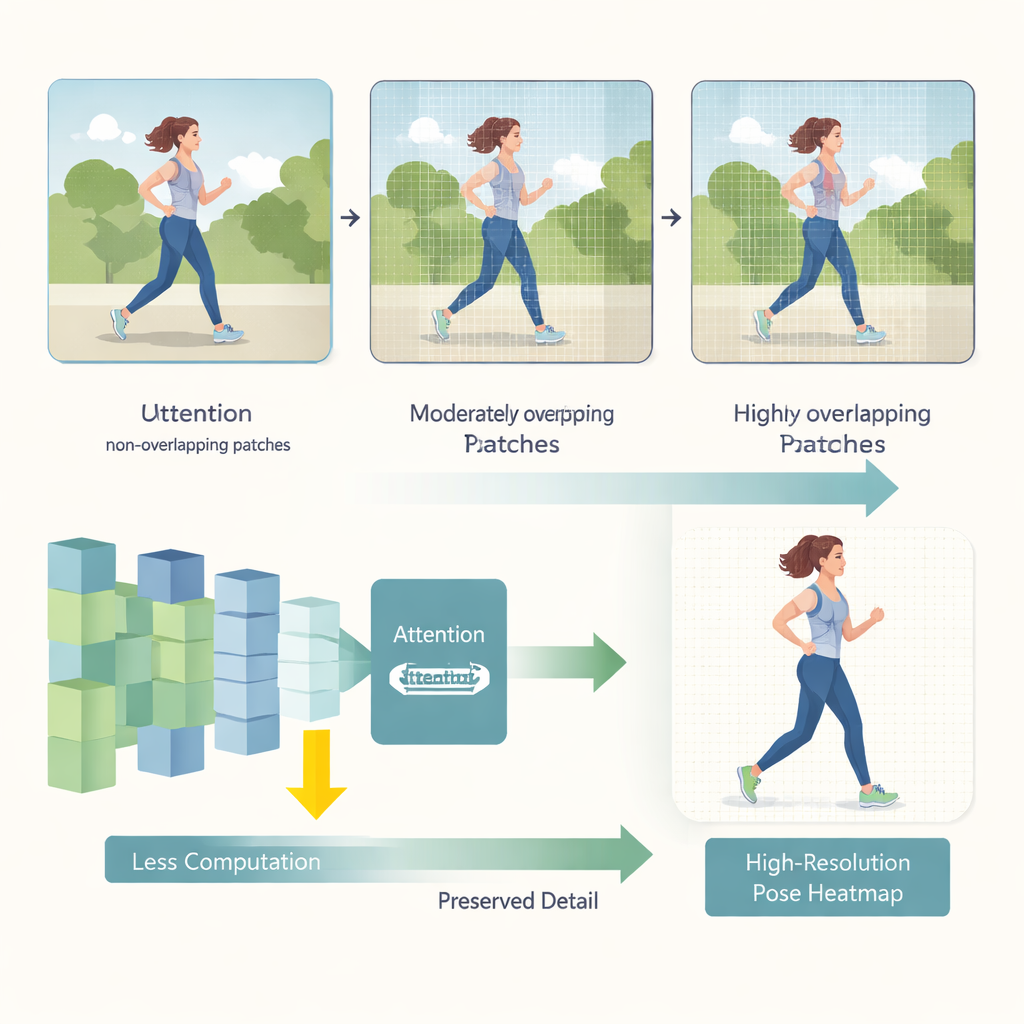
HEViTPose parte ripensando il modo in cui un’immagine viene suddivisa in pezzi per l’analisi. I precedenti modelli transformer spesso tagliano l’immagine in tasselli non sovrapposti, il che può interrompere la continuità visiva tra regioni adiacenti—come tagliare il braccio di una persona al bordo di un patch. HEViTPose si basa su un’idea chiamata embedding di patch sovrapposte e introduce una misura più chiara e regolabile chiamata Patch Embedding Overlap Width (PEOW). PEOW conta semplicemente quanti pixel i tasselli vicini condividono lungo i loro bordi. Variando sistematicamente questa sovrapposizione, gli autori mostrano che una sovrapposizione moderata permette alla rete di «percepire» meglio il cambiamento graduale di colore e forma da un tassello all’altro. Questa continuità locale più ricca porta a posizioni delle articolazioni più accurate, senza aumentare drasticamente la dimensione del modello o il costo computazionale.
Attenzione più intelligente con meno lavoro
La seconda innovazione chiave è un nuovo modulo di attenzione chiamato Cascaded Group Spatial Reduction Multi-Head Attention (CGSR-MHA). I meccanismi di attenzione dicono alla rete quali parti dell’immagine dovrebbero influenzare ogni previsione, ma tipicamente crescono di costo quando le immagini diventano più grandi. CGSR-MHA affronta questo problema in tre modi. Primo, divide le feature in gruppi, così ogni gruppo gestisce solo una porzione dell’informazione invece di tutto contemporaneamente. Secondo, riduce la risoluzione spaziale all’interno di ciascun gruppo prima di calcolare l’attenzione, diminuendo notevolmente il numero di operazioni. Terzo, utilizza diversi piccoli attention head anziché pochi grandi, preservando la diversità di ciò a cui il modello può «prestare attenzione» mantenendo basso il costo. Impostazioni scelte con cura sul numero di gruppi, sul livello di riduzione e sul numero di head consentono un buon compromesso tra velocità e accuratezza.
Modelli leggeri che competono ancora ai vertici
Per testare HEViTPose, gli autori lo valutano su due benchmark ampiamente usati: il dataset MPII delle attività umane quotidiane e il più grande dataset COCO con persone in molte scene diverse. Su diverse dimensioni di modello, HEViTPose eguaglia o si avvicina all’accuratezza dei principali sistemi di stima della posa pur usando molti meno parametri e meno calcolo. Per esempio, una versione raggiunge un’accuratezza simile a quella di una popolare rete ad alta risoluzione (HRNet) riducendo il numero di parametri appresi di oltre il 60% e diminuendo il carico computazionale di oltre il 40%. Rispetto a un altro modello ibrido moderno che mescola convoluzioni e transformer, HEViTPose offre prestazioni simili ma gira circa 2,6 volte più velocemente su una GPU. Questi risparmi si traducono direttamente in prestazioni in tempo reale più fluide e requisiti hardware inferiori.
Cosa significa per le applicazioni quotidiane
In termini semplici, HEViTPose dimostra che non è necessario scegliere tra accuratezza ed efficienza nell’insegnare ai computer a leggere il linguaggio del corpo umano. Sovrapponendo con cura i pezzi d’immagine esaminati e riprogettando il modo in cui l’attenzione viene calcolata all’interno della rete, il sistema può individuare le articolazioni con alta precisione rimanendo compatto e veloce. Questo lo rende interessante per usi nel mondo reale come il tracking sportivo, la videosorveglianza, l’interazione uomo-robot e il monitoraggio in auto, dove velocità e consumo energetico sono importanti. Le idee alla base di HEViTPose—sovrapposizione più intelligente e attenzione efficiente—potrebbero anche essere adattate a compiti correlati come il tracciamento della posa animale o il rilevamento di punti di riferimento facciali, portando potenzialmente «occhi digitali» più acuti a molti dispositivi senza richiedere hardware da supercomputer.
Citazione: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
Parole chiave: stima della posa umana, visione artificiale, vision transformer, deep learning efficiente, meccanismo di attenzione